Command Palette
Search for a command to run...
套利:通过优势感知推测实现高效推理
套利:通过优势感知推测实现高效推理
摘要
现代大型语言模型通过采用长链思维(Chain of Thoughts)实现了令人瞩目的推理能力,但在推理过程中带来了巨大的计算开销,这促使研究者们致力于提升性能与计算成本之间的比率。在诸多优化技术中,推测解码(Speculative Decoding)通过使用一个快速但精度较低的草稿模型,自回归地生成候选词元(tokens),再由能力更强的目标模型并行验证这些词元,从而加速推理过程。然而,由于在语义等价的推理步骤中因词元不匹配而导致的无效拒绝,传统的基于词元级别的推测解码在复杂推理任务中表现受限。尽管近期研究已转向基于步骤级别的语义验证机制——通过整体接受或拒绝整个推理步骤来提升效率,但现有方法仍频繁对被拒绝的步骤进行重复生成,改进有限,造成宝贵的目标模型计算资源浪费。为应对这一挑战,我们提出 Arbitrage,一种新颖的基于步骤级别的推测生成框架。该框架根据草稿模型与目标模型之间的相对优势,动态地调度生成过程。与采用固定接受阈值的传统方法不同,Arbitrage 引入了一个轻量级路由模块,该模块经过训练,能够预测目标模型更有可能生成高质量推理步骤的时机。这种路由机制近似于一个理想的“套利预言机”(Arbitrage Oracle),始终选择质量更高的推理步骤,从而在效率与准确性之间实现接近最优的权衡。在多个数学推理基准测试中,Arbitrage 均显著优于先前的步骤级推测解码基线方法,在保持相同准确率的前提下,推理延迟最高可降低约两倍。
一句话总结
加州大学伯克利分校、苹果公司、国际计算机科学研究所(ICSI)和劳伦斯伯克利国家实验室(LBNL)提出了 ARBITRAGE,这是一种基于步骤级的推测性解码框架,通过引入轻量级路由器动态选择草案模型与目标模型中质量更高的推理步骤,减少无效的重新生成,相比先前方法在数学推理任务上将推理延迟最多降低至原来的 1/2。
主要贡献
- 现有的步骤级推测性解码方法通常因采用固定的接受阈值而无法考虑草案模型与目标模型之间的相对性能差异,导致频繁且无实质质量提升的重新生成,造成计算资源浪费。
- ARBITRAGE 引入了一种动态路由机制,利用轻量级路由器预测目标模型在哪些步骤上可能生成显著更优的推理结果,从而更高效地使用目标模型的计算资源。
- 在多个数学推理基准上的评估表明,ARBITRAGE 相比先前的步骤级方法最多可将推理延迟降低约 2 倍,同时保持甚至提升输出准确性。
引言
大型语言模型(LLMs)通过长链式思维(CoT)生成在复杂推理任务上表现出色,但其自回归式的 token 解码方式在推理过程中形成了内存瓶颈,尤其在长推理序列中尤为明显。推测性解码(Speculative Decoding, SD)通过使用快速的草案模型提出 token 或推理步骤,再由能力更强的目标模型并行验证,从而提升吞吐量。尽管步骤级 SD(验证整个推理步骤而非单个 token)提升了接受率和鲁棒性,但现有方法如基于奖励引导的 SD(RSD)依赖于绝对质量阈值来决定是否使用目标模型重新生成,导致频繁且往往不必要的重新生成,浪费计算资源却未带来显著的质量提升。
作者提出一个关键洞察:路由决策不应基于草案步骤的绝对质量,而应取决于目标模型在特定步骤上相对于草案模型的预期优势。为此,他们提出了 ARBITRAGE,一种步骤级推测性生成框架,引入一个轻量级路由器,用于预测目标模型是否可能生成比草案模型显著更优的推理步骤。该路由器近似于一个理想的 ARBITRAGE ORACLE(始终选择质量更高的步骤),实现基于优势的动态路由。通过在增益较小时避免昂贵的目标模型重新生成,ARBITRAGE 减少了冗余计算,优化了效率与准确性的权衡。实验表明,在多个数学推理基准上,ARBITRAGE 在保持相同准确率的情况下,相比先前的步骤级 SD 方法最多可将延迟降低约 2 倍。
数据集
-
作者使用从 NuminaMath-CoT 数据集中构建的步骤级数据集,并通过分层采样选取 30,000 个问题作为微调的种子数据。
-
对于每个问题上下文 x,草案模型和目标模型从相同的前缀开始解码,生成成对的推理步骤 (zd,zt)。作者使用固定的 PRM 模型计算 sd 和 st,然后计算步骤级优势 Δ,并导出 oracle 标签 γ=I[Δ>0],表示使用目标模型是否能提升输出质量。
-
为降低 oracle 信号的方差,每个上下文可能生成多个目标样本;其 PRM 分数取平均值得到 sˉt 和 Δˉ,并据此计算最终的 oracle 标签 y。
-
最终形成的训练元组 (x,zd,zt,sd,st,Δ,y) 构成了用于训练路由器模型的监督数据集。
-
由于类别不平衡(大多数草案步骤可接受,即 y=0),作者对多数类(y=0)进行随机下采样,以平衡数据集,减轻模型偏向接受草案步骤的偏差。
-
其他预处理包括为每一步标注生成模型、归一化序列长度,并将步骤分隔符统一为
\n\n,以确保 PRM 评分与路由器输入的一致性。
方法
作者提出了一种名为 ARBITRAGE 的步骤级推测性解码框架,该框架基于预测的质量优势,在轻量级草案模型和更强大的目标模型之间动态路由。与依赖过程奖励模型(PRM)绝对奖励阈值的传统推测性解码不同,ARBITRAGE 引入了一个轻量级路由器,用于估计使用目标模型重新生成某一步骤是否能获得比草案输出更高的 PRM 分数,从而避免不必要的目标模型调用。
在每个推理步骤中,草案模型根据当前上下文 x 生成候选步骤 zd,并在输出分隔符后终止。该步骤随后由 ARBITRAGE ROUTER 评估,路由器输出一个标量 y^=hθrouter(x,zd),表示目标模型生成的步骤 zt 在 PRM 下优于 zd 的预测概率。是否接受或升级的决策由可调阈值 τ 控制:若 y^≤τ,则接受草案步骤;否则,目标模型将从相同前缀重新生成该步骤。
参考框架示意图,其中展示了两种可能的执行路径:在步骤 1 中,路由器预测升级无优势(y^<τ),因此接受草案步骤并继续;在步骤 2 中,路由器预测存在显著优势(y^>τ),触发目标模型重新生成后再继续。
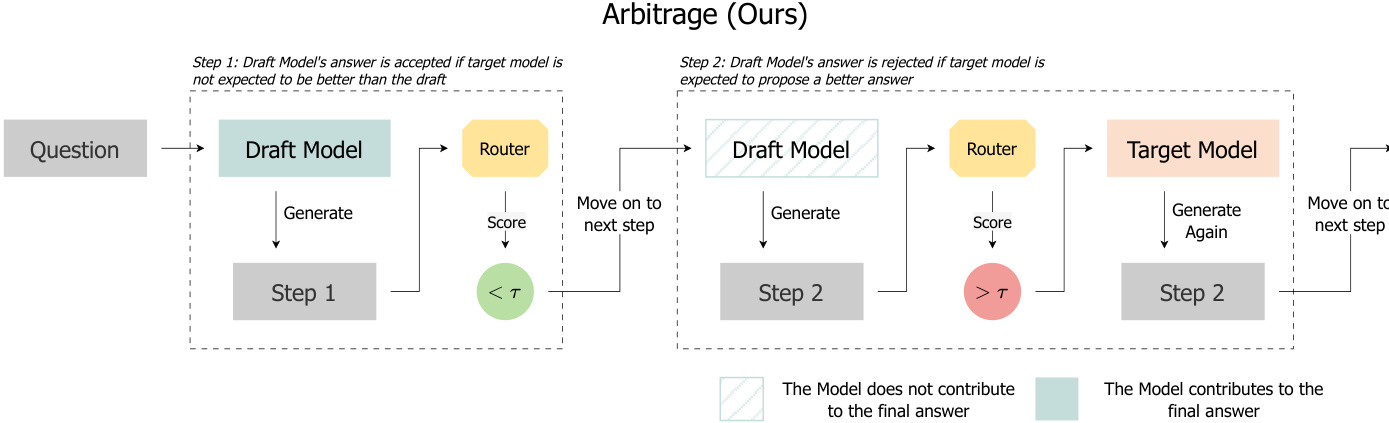
路由器在离线阶段训练,以逼近 ARBITRAGE ORACLE —— 一种理论上最优但计算上不可行的策略,该策略通过比较相同上下文中草案和目标步骤的反事实 PRM 分数 sd 和 st 来决策。Oracle 选择奖励更高的步骤:z∗=argmaxz∈{zd,zt}hθPRM(x,z)。优势 Δ=st−sd 量化了目标模型相对于草案模型的潜在增益。Oracle 的最优路由策略为 aτ∗=I{Δ>τ},在固定升级预算下最大化预期质量。
如下图所示,ARBITRAGE 避免了 RSD 固有的“无效重新生成”问题:在 RSD 中,步骤 3 和步骤 4 被重新生成,但其 PRM 分数低于或等于草案版本;而 ARBITRAGE 仅在预测优势为正的步骤 3 上重新生成,并在路由器预测无改进的步骤 4 上直接接受草案,避免了重新生成。

路由器的预测通过 τ 实现对计算-质量权衡的细粒度控制,且每步仅引入一次前向传播。该设计在保持推测性解码效率的同时,显著减少了冗余计算,因为路由器在推理时无需执行目标模型即可近似 Oracle 的优势感知决策。
实验
- 实证分析表明,RSD 在 70% 的委派率下最多产生 40% 的无效目标模型调用,由于在低分但正确的草案步骤或草案与目标共有的失败模式上进行重新生成,导致无质量增益。
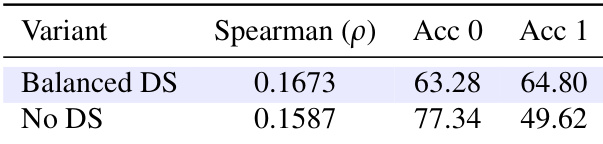
- ARBITRAGE ROUTER 使用 1.5B PRM 检查点进行训练,并结合步骤级标注和类别平衡下采样,在解决标签不平衡问题后实现了更高的 Spearman 相关性(ρ=0.1673)和平衡准确率。
- 在 MATH500 和 OlympiadBench 上,ARBITRAGE ROUTER 在 LLaMA3(1B/8B)、LLaMA3(8B/70B)和 Qwen2.5-Math(3bit-7B/7B)等模型组合上均优于 RSD,在相近接受率下实现更高准确率,且与 Oracle 表现接近。
- 消融实验确认,使用步骤标注的二分类方案性能最佳:相比无标注和多分类变体,其提升了 Spearman 相关性和标签为 1 的准确率。
- ARBITRAGE 在 MATH500 上最多实现 1.62 倍的延迟降低,在 OlympiadBench 上最多实现 1.97 倍的加速,且保持相同准确率,证明其通过减少不必要的目标模型调用实现了更优的计算-质量权衡。
作者评估了将历史路由上下文纳入 ARBITRAGE 路由器的影响,发现包含先前模型选择的标注输入可提升 Spearman 相关性和升级决策的准确率。结果显示,标注变体的相关性更高(0.1508 vs. 0.1305),标签为 1 的准确率也更好(72.96% vs. 69.58%),表明路由历史增强了模型识别目标升级有益步骤的能力。

作者评估了 ARBITRAGE 路由器不同标签粒度的影响,发现二分类变体在 Oracle 优势得分的 Spearman 相关性和两类平衡准确率上均达到最高。将类别数增加至 4 或 10 会降低整体相关性并引入标签偏斜,表明二分类路由在实际部署中提供了最稳健的权衡。

作者评估了类别平衡下采样对路由器训练的影响,发现数据集平衡后提升了 Spearman 相关性和标签为 1 的准确率,同时减少了对多数接受类的偏差。若不进行下采样,路由器会过度自信地接受草案步骤,导致升级不足和整体路由质量下降。