Command Palette
Search for a command to run...
CUDA-L2:通过强化学习超越cuBLAS的矩阵乘法性能
CUDA-L2:通过强化学习超越cuBLAS的矩阵乘法性能
Songqiao Su Xiaofei Sun Xiaoya Li Albert Wang Jiwei Li Chris Shum
摘要
本文提出CUDA-L2,一个融合大语言模型(LLMs)与强化学习(RL)的系统,用于自动优化半精度通用矩阵乘法(HGEMM)的CUDA内核。该系统以CUDA执行速度作为强化学习的奖励信号,能够在1,000种配置空间中自动搜索并优化HGEMM内核。在离线模式下(内核连续执行,无时间间隔),CUDA-L2在平均性能上分别较广泛使用的torch.matmul提升22.0%、较NVIDIA闭源高性能库cuBLAS(采用最优布局配置:normal-normal NN 与 transposed-normal TN)提升19.2%、较基于启发式策略的cuBLASLt-heuristic(调用cuBLASLt库并依据启发式建议选择算法)提升16.8%,并较最具竞争力的cuBLASLt-AutoTuning模型(从cuBLASLt建议的最多100个候选算法中选择最优者)提升11.4%。在服务器模式下(内核以随机间隔执行,模拟真实推理场景),性能提升进一步扩大:分别达到torch.matmul的+28.7%、cuBLAS的+26.0%、cuBLASLt-heuristic的+22.4%以及cuBLASLt-AutoTuning的+15.9%。CUDA-L2表明,即使对于性能高度优化、关键性极强的内核(如HGEMM),通过大语言模型引导的强化学习自动化方法,仍可实现显著性能提升。该方法能够系统性地探索人类难以企及规模的配置空间,从而发现更优的实现方案。项目代码与资源详见:github.com/deepreinforce-ai/CUDA-L2
一句话总结
作者提出CUDA-L2——一种由大语言模型引导的强化学习系统,可自动优化面向LLM推理的A100 GPU半精度矩阵乘法(HGEMM)内核。该系统通过系统化探索先前框架无法手动调优的优化空间,在1,000种矩阵配置下实现了比torch.matmul和Nvidia cuBLAS库高出两位数的加速比。
核心贡献
- 由于LLM中矩阵维度(M, N, K)变化导致需采用不同策略,且GPU架构间优化策略迁移性差,手动优化半精度通用矩阵乘法(HGEMM)内核极具挑战性。尽管矩阵乘法在计算中至关重要,但可扩展调优仍受阻。
- CUDA-L2引入大语言模型引导的强化学习系统,可自动优化1,000种维度配置(涵盖{64, 128, ..., 16384}的全部103组合)的HGEMM内核,通过多阶段强化学习训练、增强版CUDA代码预训练及NCU性能分析指标实现架构特定决策。
- 在覆盖常见LLM层维度的1,000种HGEMM配置评估中,CUDA-L2在离线模式下比torch.matmul平均提速+22.0%、比cuBLASLt-AutoTuning平均提速+11.4%;在服务器模式推理模拟中,加速比分别提升至+28.7%和+15.9%。
引言
高性能矩阵乘法(HGEMM)对加速GPU上的AI工作负载至关重要,微小的速度提升即可显著影响大规模模型训练与推理。现有厂商库(如cuBLAS)已设定较高性能基准,但CUDA-L1等先前优化框架因训练数据局限于特定基准测试、缺乏对CUTLASS/CuTe等现代GPU工具及新架构的认知而在HGEMM优化中表现不佳。作者通过CUDA-L2突破这些限制——该强化学习系统能超越受限基准测试范围,融合最新硬件洞察,在HGEMM执行速度上超越cuBLAS。
数据集
作者采用两大来源的CUDA代码数据集进行延续预训练,关键细节如下:
-
构成与来源:
整合网络爬取的CUDA代码(经基于规则的过滤和LLM提取清洗)与成熟库实现(PyTorch、ATen、CUTLASS、NVIDIA教程/示例)。 -
子集特性:
- 网络来源:原始代码经严格清洗与分段处理,缺乏自然指令提示。
- 库代码:直接集成无需额外过滤。
两子集均处理为"指令-上下文-代码"三元组。
-
训练应用:
三元组用于DeepSeek 671B的延续预训练。每组三元组包含:
(1) LLM生成的指令(通过Claude Sonnet 4描述代码功能),
(2) 基于指令检索的文档/示例,
(3) 原始CUDA代码片段。
该混合数据培养通用CUDA优化及检索增强能力。 -
处理细节:
未进行裁剪。元数据通过为原始代码生成描述性提示、再结合检索上下文增强构建。最终三元组专用于训练集。
方法
作者结合多阶段强化学习(RL)与大语言模型(LLM)自主生成并优化HGEMM CUDA内核。CUDA-L2系统在CUDA-L1基础上,通过领域特定预训练、细粒度性能分析反馈及检索增强上下文,高效探索矩阵维度(M, N, K)与硬件约束的庞大配置空间。
训练流程始于对约1,000个来自PyTorch/ATen/CUTLASS等库的CUDA内核语料库进行延续预训练。这些内核涵盖线性代数、卷积、规约、注意力等操作,使LLM掌握广泛CUDA惯用法。此阶段采用对比RL策略:模型将生成的内核变体与参考实现对比,并基于测试迭代的平均加速比获得奖励。参数更新使用GRPO算法,通过平滑与裁剪奖励防止奖励作弊。
在后续HGEMM专用RL阶段,模型被约束为针对不同(M, N, K)配置生成半精度矩阵乘法内核。奖励函数平衡性能、正确性与代码简洁性:
r(custom)=N1i=1∑N[tcustomitrefi−α⋅diffi]−βL(custom)其中diffi度量与FP32 CPU基准的最大逐元素偏差,L(custom)惩罚代码长度。这促使模型生成既快速、数值精确又紧凑的内核。
为指导优化决策,CUDA-L2将NVIDIA Nsight Compute(NCU)性能指标(如内存吞吐量、SM占用率、缓存效率)融入RL上下文,使模型能基于底层硬件行为推理而非仅依赖端到端执行时间。生成的内核通过nvcc编译为独立.cu文件,支持CUDA C/C++、CuTe、内联PTX及CUTLASS模板,但排除Triton等基于Python的DSL。
模型根据问题规模自主选择适当抽象:小矩阵倾向使用轻量级内核(基于WMMA内在函数且同步最少);大矩阵则采用CuTe高级抽象管理复杂分块操作与多级流水线。奖励机制对简短代码的偏好自然强化了CuTe在复杂优化中的表达优势。
CUDA-L2发现并应用多种高级优化技术,包括:通过swizzle模式避免共享内存库冲突、带可配置缓冲级的多级流水线、异步内存拷贝、寄存器累加、块swizzling提升L2缓存局部性等。它还能针对(M, N, K)三元组确定这些技术的最佳参数化(如swizzleStride或n_stage)。
一项创新是采用带乒乓执行的双缓冲寄存器片段,将数据预取与张量核计算重叠以消除停顿周期。当寄存器余量充足且K较大时,该技术显著提升吞吐量。类似地,模型采用激进的多步预取策略,提前多轮加载数据以完全重叠内存与计算流水线,尤其适用于高迭代次数场景。
在收尾阶段,当寄存器与共享内存布局对齐时,CUDA-L2消除不必要的中间张量,使用宽数据类型(如uint128_t)直接执行寄存器到共享内存的传输,减少拷贝操作并提升带宽利用率。如下图所示,这种直接宽拷贝替代了涉及中间张量的标准两步法。

此外,CUDA-L2通过在MMA操作周围交错A/B矩阵加载来修改预取调度。不同于连续发出两次预取,它采用交错方式:先预取A,再用已加载数据执行MMA,最后预取B。这增加了指令级并行性并更好利用执行单元,尤其在计算成为瓶颈时。下图对比了这种交错预取策略与标准连续方法。

实验
- 在覆盖常见LLM维度的1,000组(M, N, K)配置中验证CUDA-L2的自动HGEMM内核优化能力
- 在A100 GPU上离线模式比torch.matmul提速22.0%,服务器模式提速28.7%
- 使用最优NN/TN布局,比cuBLAS-max离线/服务器模式分别快19.2%/26.0%
- 在1,000组配置中,比cuBLASLt-heuristic离线/服务器模式分别快16.8%/22.4%
- 比cuBLASLt-AutoTuning(100算法搜索)离线/服务器模式分别快11.4%/15.9%,胜率稳定在79.3%-95.7%
- 在GPU利用率不足的小矩阵场景中增益更大(最高达1.4倍加速比)
作者在1,000组矩阵配置下将CUDA-L2与多个基线对比,报告离线与服务器模式的平均加速比。结果表明CUDA-L2持续超越所有基线:相比torch.matmul离线/服务器模式分别快22.0%/28.7%,相比最强基线cuBLASLt-AutoTuning-max分别快11.4%/15.9%,且所有对比胜率均超79%。
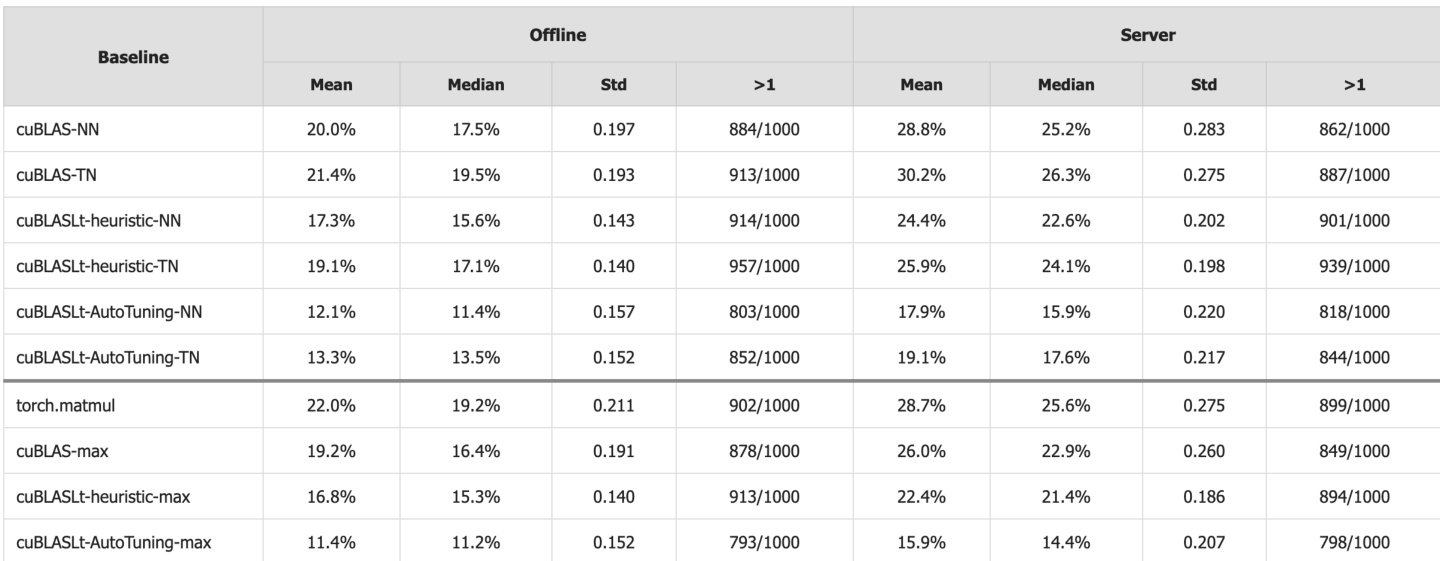
作者在1,000组矩阵配置下将CUDA-L2与主流HGEMM基线对比,显示离线与服务器模式均持续加速。结果表明:离线模式下CUDA-L2比基线平均快11.4%至22.0%,服务器模式提升至15.9%至28.7%;若按配置选择CUDA-L2或基线中更快者,增益进一步扩大。该系统甚至超越最具竞争力的cuBLASLt-AutoTuning,证实其在规模化内核自动化优化中的有效性。