Command Palette
Search for a command to run...
LFM2 技术报告
LFM2 技术报告
摘要
我们提出 LFM2,一个面向高效设备端部署并具备强大任务能力的液态基础模型家族。通过在边缘设备延迟与内存约束条件下,采用“硬件感知的架构搜索”方法,我们构建了一个紧凑的混合骨干网络,该网络结合了门控短卷积与少量分组查询注意力模块,在CPU上实现的预填充(prefill)与解码速度相比同等规模的模型最高提升2倍。LFM2家族涵盖3.5亿至83亿参数,包括密集模型(350M、700M、1.2B、2.6B)以及一个专家混合模型变体(总参数8.3B,活跃参数1.5B),所有模型均支持32K上下文长度。LFM2的训练流程包含三项关键设计:温度调节的、解耦的Top-K知识蒸馏目标,有效避免了支持集不匹配问题;基于难度排序的数据的课程学习(curriculum learning);以及三阶段后训练策略:监督微调、长度归一化的偏好优化,以及模型融合。在10至12万亿token上预训练后,LFM2模型在多个多样化基准测试中均表现出色;例如,LFM2-2.6B在IFEval上达到79.56%的准确率,在GSM8K上达到82.41%。我们进一步构建了多模态与检索任务的扩展版本:用于视觉-语言任务的LFM2-VL,用于语音任务的LFM2-Audio,以及用于信息检索的LFM2-ColBERT。LFM2-VL通过高效的视觉处理机制,支持灵活的精度-延迟权衡;LFM2-Audio采用分离的音频输入与输出路径,实现与参数量大三倍的模型相当的实时语音到语音交互性能;LFM2-ColBERT则提供低延迟的查询与文档编码器,支持跨多种语言的高性能检索。所有模型均以开源权重及部署包形式发布,支持ExecuTorch、此网址(this http URL)和vLLM,使LFM2成为面向边缘应用的实用基础模型,满足快速、内存高效推理与强大任务能力的双重需求。
一句话总结
Liquid AI 团队推出了 LFM2,这是一系列面向边缘设备优化的基础模型,采用硬件协同设计的混合骨干架构,结合门控短卷积与稀疏分组查询注意力机制,在保持 350M–8.3B 参数范围内强大任务性能的同时,使 CPU 上的预填充和解码速度最高提升 2 倍;模型通过受控的、解耦的 Top-K 知识蒸馏目标和三阶段后训练流程,显著提升了小模型质量,并扩展至多模态(LFM2-VL、LFM2-Audio)和检索(LFM2-ColBERT)任务,所有模型均开放权重并支持 ExecuTorch、llama.cpp 和 vLLM 部署,适用于对低延迟、内存高效推理有要求的设备端应用。
主要贡献
-
LFM2 引入了面向设备端部署的边缘优先架构,采用输入感知的门控卷积与分组查询注意力(GQA)构成的最小化混合骨干,通过硬件协同搜索进行优化,在 CPU 和异构 NPU 上严格设备约束下实现了质量、延迟与内存的平衡。
-
LFM2 训练流程包含 10–12T 标记的预训练阶段,结合长上下文中期训练,以及一种新颖的受控、解耦 Top-K 知识蒸馏目标,有效提升小模型性能且避免支持不匹配;随后是三阶段后训练流程,进一步增强鲁棒性与下游准确率。
-
LFM2 在设备端实现了出色的效率-准确率权衡:密集模型(350M–2.6B)在 CPU 上的预填充与解码延迟相比同类基线最高提升约 2 倍;8.3B MoE 变体以仅约 1.5B 激活参数实现 3–4B 级别性能,并原生支持多模态(视觉、音频)与检索能力。
引言
作者针对语音助手、本地协作者和智能体工作流等应用中对设备端生成式 AI 的日益增长需求展开研究,这些场景对 CPU 和 NPU 上的延迟、内存与能耗有严格限制,使得云端推理不切实际。以往工作主要聚焦于数据中心部署的大型模型,导致面向边缘环境的高效高质量小型模型存在空白。为此,作者推出了 LFM2,这是第二代 Liquid Foundation Models 的家族,从架构到训练均协同设计以实现边缘优先性能。其核心贡献是一种硬件协同优化的混合骨干,结合门控卷积与分组查询注意力,使密集模型与 MoE 模型(350M–8.3B 激活参数)在 CPU 上实现预填充与解码速度提升 2 倍,同时保持强大准确率。该框架还包含高效的预训练(采用解耦 Top-K 蒸馏目标)、三阶段后训练流程以及原生多模态(视觉、音频、检索)变体,所有模型均开放权重,并支持主流边缘运行时。
数据集

-
LFM2 密集模型在混合数据集上进行预训练,其中约 75% 为英文文本,20% 为多语言文本,5% 为代码。多语言部分优先涵盖日语、阿拉伯语、韩语、西班牙语、法语和德语,另支持中文、意大利语和葡萄牙语。MoE 模型 LFM2-8B-A1B 采用类似混合比例,但更强调代码——60% 英文、25% 多语言、15% 代码,其中 50% 代码样本使用填空中间(FIM)目标进行训练。
-
密集型 LFM2 模型在 4,096 标记上下文长度下预训练 10 万亿标记,随后在 1 万亿高质量标记上进行中期训练,上下文窗口扩展至 32,768 标记,并采用加速学习率衰减。LFM2-8B-A1B 模型遵循相同两阶段流程,但初始预训练达 12 万亿标记。
-
监督微调(SFT)数据包含 350M 至 2.6B 模型的 539 万样本,8B-A1B 模型为 924 万样本,分别来自 67 和 79 个精心筛选的数据源。数据涵盖开源数据集、授权数据及为设备端部署优化的合成数据。语料库中 80% 为英文,其余 20% 均匀分布在阿拉伯语、中文、法语、德语、日语、韩语和西班牙语中。多语言内容融入所有任务类别,而非孤立处理,以实现自然的跨语言迁移。
-
一套全面的数据质量流程确保训练数据的高保真度。流程始于对候选数据集的人工评估,随后使用集成判别大模型进行自动化过滤,以评估事实准确性、相关性与有用性。通过规则与自动化方法移除格式错误样本、拒绝模式及高频短语。采用 CMinHash 与句子嵌入结合高相似度阈值,执行精确、近似重复与语义去重。通过 n-gram 与语义匹配进行去污染,防止评估基准泄露。
-
采用数据驱动的课程学习策略,利用 12 个多样化大模型的集成对训练样本按难度排序。每个样本的模型实证成功率决定其难度等级。第二个模型基于提示特征预测该排序,使训练从简单到复杂逐步推进。
-
对视觉-语言模型,图像预处理采用两种模式:对于 ≤512×512 像素的图像使用单帧模式,缩放对齐 SigLIP2 编码器的 patch 网格;对于更大图像采用动态分块,将其分割为 512×512 块(2–10 块),可选添加缩略图帧。块与缩略图交错插入位置标记,并以图像开始/结束标记包裹。图像标记数量根据分辨率在 128 至 2,800 之间变化。
-
VLM 训练采用多阶段混合:使用多样化图像-文本描述数据进行连接器预训练;中期训练包含广泛描述、文档 VQA、OCR 与细粒度推理数据(部分重新标注与增强);SFT 阶段使用多轮、多图像、任务多样化的视觉-语言交互。多语言视觉-语言数据被翻译为阿拉伯语、中文、法语、德语、意大利语、日语、韩语、葡萄牙语和西班牙语,以增强跨语言视觉理解。未使用显式定位监督(如边界框)。
-
音频训练数据涵盖转录、语言分类、文本转语音及语音聊天指令调优。数据包括 CommonVoice 和 LibriSpeech 等开源数据集,以及通过专有流程生成的内部合成对话。合成数据强调副语言特征(停顿、填充词、语调)和通过语音克隆实现的多样化用户声音。数据通过规则与 LLM 方法过滤,确保连贯性与质量。总音频量约为每轮 47.2 万小时,相当于约 215 亿音频嵌入。
-
模型在多个基准上进行评估:MMLU(5-shot,聊天模板)、MMLU-Pro(5-shot CoT,系统提示)、GPQA Diamond(10 次运行,答案置换)、IFBench(严格/宽松准确率)、Multi-IF(3 轮平均)、GSM8K、GSMPlus、MATH 500、MATH Level 5、MMMLU(0-shot,多语言)和 MGSM(每语言 5-shot)。所有任务均使用贪婪解码,结合上下文适当的标记限制与一致的解析策略。
方法
LFM2 架构设计为一组面向设备端部署的通用基础模型,强调效率与强大任务能力。核心设计为最小化混合骨干,是硬件协同架构搜索的结果。该搜索在严格设备侧延迟与峰值内存约束下,优先考虑下游质量,尤其针对 CPU 和异构 NPU。最终架构为仅解码器堆叠,结合两种主要模块:多数廉价的门控短卷积模块与少数分组查询注意力(GQA)模块,辅以 SwiGLU 前馈模块。该混合设计因在质量-延迟-内存权衡上表现最优而被选中,优于包含线性注意力或状态空间模型的更复杂混合架构,在相同设备性能预算下表现更优。框架图展示了整体结构,显示 LFM2-Base 为基底,从中衍生出 LFM2-VL、LFM2-Audio 与 LFM2-ColBERT 等专用变体。LFM2-Base 本身由一系列相同层组成,每层包含一个门控短卷积模块、一个 GQA 模块与一个 SwiGLU 模块,按特定交错模式排列。模型效率进一步通过使用预归一化 RMSNorm 与 QK-Norm 的 RoPE 得到增强,这是现代 Transformer 架构中的标准组件。
门控短卷积模块是 LFM2 骨干的关键组件,提供在 CPU 上具有优异缓存行为的快速局部混合。该模块对输入隐藏序列 h∈RL×d 首先应用线性映射生成三个特征向量 B、C 与 h~。随后使用逐元素乘法在深度可分离 1D 卷积(核大小 k)周围施加输入依赖的门控。卷积输出再通过另一个逐元素乘法与 C 调制,最后投影至输出维度。该算子与其它高效序列模块中的短程组件密切相关,搜索结果表明,当与少量全局注意力层结合时,其局部混合能力足以满足大多数任务需求。GQA 模块负责处理长程依赖,通过在头组间共享键值(KV)来减少 KV 内存流量,同时保持多头查询。SwiGLU 模块为位置感知的多层感知机,其扩展比例由搜索选择,以提供非线性变换。模型的分词器为字节级 BPE,词汇表大小为 65,536,专为高效编码多种语言与结构化数据而设计。
LFM2 家族包含密集型与混合专家(MoE)变体。密集模型(350M–2.6B 参数)直接由混合骨干构建。MoE 变体 LFM2-8B-A1B 总参数达 8.3B,但每标记仅激活 1.5B 参数,适用于计算每标记为首要约束的设备端场景。该模型保留快速的 LFM2 混合骨干,但将多数层中的密集 MLP 替换为稀疏 MoE MLP。为保证稳定性,前两层保持密集,其余层均包含 MoE 模块。每层 MoE 模块包含 32 个专家,模型使用归一化 Sigmoid 路由器选择 Top-k=4 个专家,路由中引入自适应路由偏置以实现负载均衡。专家本身为 SwiGLU MLP。该稀疏架构使模型在解码成本相当于 1.5B 级模型的同时,达到 3–4B 级模型的质量。
LFM2 的训练流程为多阶段设计,专为小型设备端模型优化。首先在大规模数据集(10–12T 标记)上进行预训练,使用标准的下一个标记预测目标,结合受控、解耦的 Top-K 知识蒸馏(KD)目标。该 KD 目标利用内部 LFM1-7B 作为教师模型。为解决从大教师模型蒸馏时出现的支持不匹配问题,作者将 Kullback–Leibler(KL)散度分解为两项:一项为二元项,匹配教师 Top-K 集合分配的总概率质量;另一项为条件 KL 项,匹配 Top-K 集合内的相对概率。这种“解耦、受控 Top-K”目标通过仅对条件项施加温度,避免了朴素 Top-K 蒸馏的不稳定性,防止在对完整词汇表截断分布进行温度调节时出现支持不匹配。整体损失为该 KD 项与标准下一个标记交叉熵损失的平衡组合。
预训练完成后,每个 LFM2 检查点均经历三阶段后训练流程,以增强其面向终端用户应用的能力。第一阶段为监督微调(SFT),使用大规模通用数据混合,教授模型对话能力、指令遵循与多轮连贯性。第二阶段为偏好对齐,实现对离线数据的高效直接对齐,包括从 SFT 检查点生成的同策略样本。该阶段采用一系列长度归一化对齐目标,如结合相对与绝对损失分量的广义损失函数,基于隐式奖励。第三阶段为模型合并,涉及候选模型的系统性评估与组合,以提升鲁棒性并优化性能。该流程旨在提升与终端用户相关的下游能力,如检索增强生成(RAG)与函数调用。整体训练分类如框架图所示,展示从基础模型经 SFT、对齐与合并,最终形成优化模型的演进过程。
实验
- LFM2 模型在智能手机(三星 Galaxy S25)和笔记本电脑(AMD Ryzen AI 9 HX 370)CPU 上表现出卓越的推理效率,相比 Qwen3、Gemma 和 Llama-3.2 等同规模开源基线,预填充与解码吞吐量提升 1.4–3.7×,在多个规模上均表现优异,其中 LFM2-8B-A1B 的解码吞吐量比密集型 4B 模型高出 2.8–3.7×。
- 在 350M 至 8B 参数规模上,设备端性能通过一致的吞吐量提升得到验证:LFM2-1.2B 的预填充吞吐量比同类模型高 2.3–2.8×,解码吞吐量高 1.7–2.2×,同时保持竞争力的性能。
- LFM2 模型在知识、指令遵循与数学推理基准上达到最先进水平:LFM2-1.2B 在 IFEval 上得分为 74.89%(超越 30% 更大的 Qwen3-1.7B),LFM2-2.6B 在 GSM8K 上达 82.41%,LFM2-8B-A1B 在 MATH 500 上提升 +10.6 分。
- LFM2-VL 模型在多模态基准上超越同规模开源 VLM:LFM2-VL-3B 在 SEEDBench 上得分为 76.55,在 RealWorldQA 上为 71.37,多语言 MMBench 上超过 Qwen2.5-VL-3B(+1.51),MMB 上超过 +3.92,同时保持强语言能力(MMLU 上 62.70)。
- LFM2-Audio-1.5B 在语音到语音聊天(VoiceBench)与自动语音识别(ASR)中表现具有竞争力,性能可匹配或接近更大模型如 Qwen2.5-Omni-3B 与 Whisper,具备出色的实时、低延迟适用性。
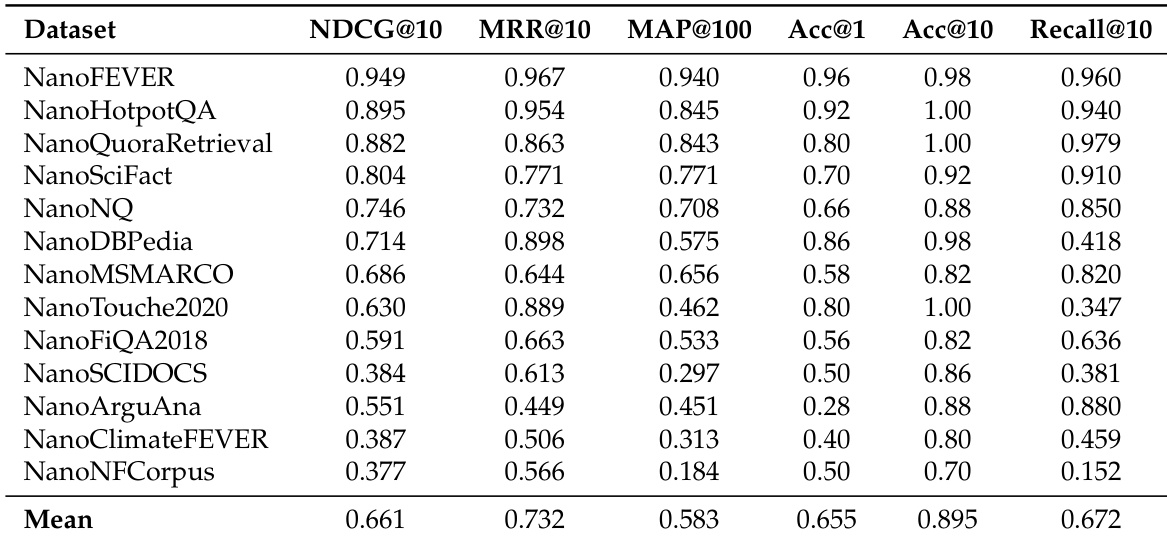
- LFM2-ColBERT-350M 在多语言检索(NanoBEIR)上实现 0.661 的平均 NDCG@10,优于 GTE-ModernColBERT-v1 的跨语言迁移能力,英语与低资源语言(如阿拉伯语、日语、韩语)之间的性能差距缩小 26%。
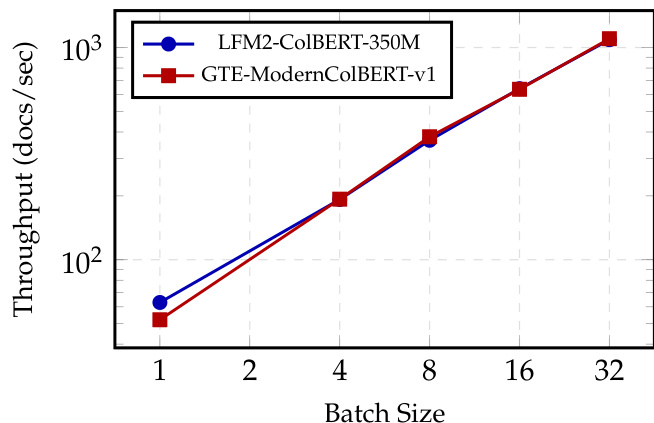
- LFM2-ColBERT-350M 在 NVIDIA H100 GPU 上的查询与文档编码吞吐量与 GTE-ModernColBERT-v1 相当,尽管模型尺寸大 2.37 倍,展示了在检索任务中的高效率。
作者使用表格将 LFM2 模型与多个开源基线在知识、指令遵循、数学推理与多语言基准上进行比较。结果显示,LFM2 模型在同等规模下表现具有竞争力,LFM2-2.6B 在指令遵循与数学推理任务上超越更大模型如 Llama-3.2-3B 与 SmolLM3-3B,而 LFM2-8B-A1B 在知识与推理能力上相比小规模变体有显著提升。
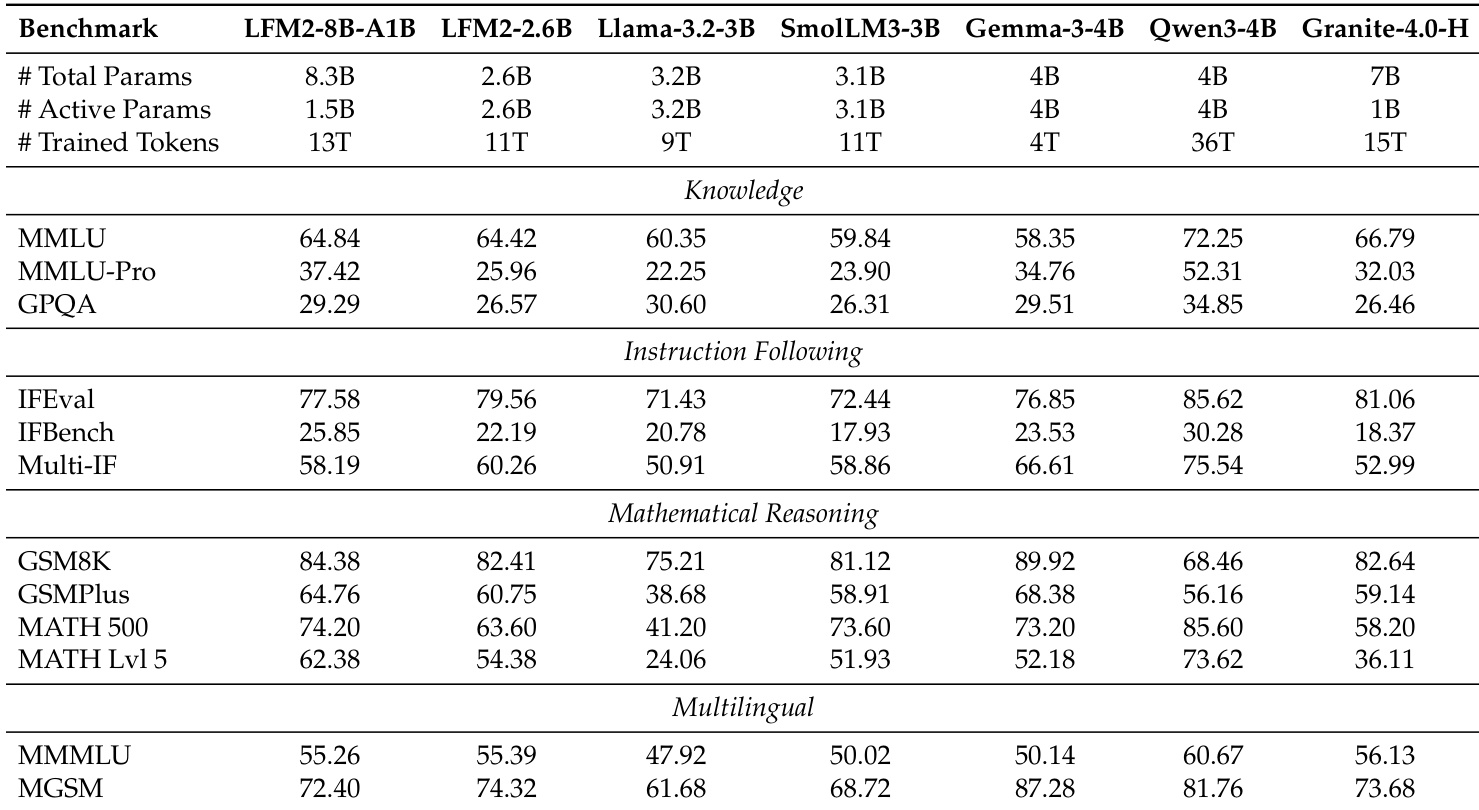
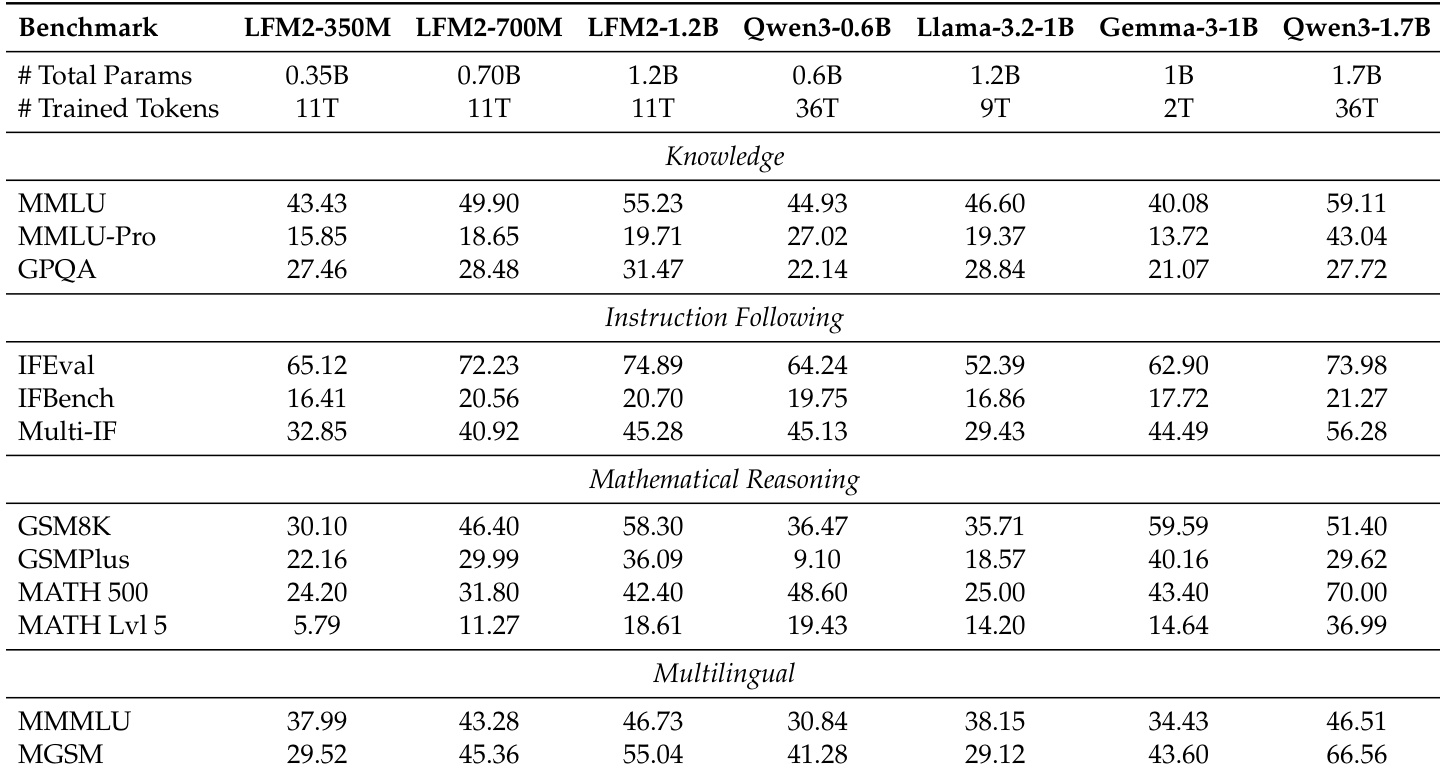
作者在多个基准上评估 LFM2 模型,结果显示 LFM2-350M 在 MMLU 和 GPQA 等知识任务中表现具有竞争力,而 LFM2-700M 与 LFM2-1.2B 在指令遵循与数学推理任务上超越同规模基线。结果表明,LFM2 模型在多样评估维度上保持强大性能,尤其在指令遵循与数学推理方面相对于其规模表现突出。
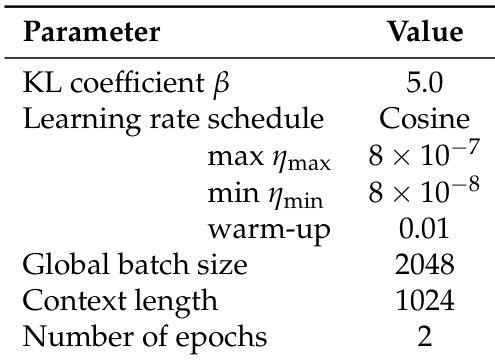
作者采用余弦学习率调度,最大学习率为 8×10−7,最小为 8×10−8,预热因子为 0.01,全局批量大小为 2048,上下文长度为 1024,训练 2 个周期。这些设置应用于 LFM2 模型训练,旨在优化边缘设备上的高效推理。
作者使用自定义评估工具包测量 LFM2-ColBERT-350M 在单语言与跨语言检索任务上的性能,展示了其强大的多语言能力与在多种语言上的稳定表现。结果显示,LFM2-ColBERT-350M 在所有任务与语言上平均 NDCG@10 达 0.661,尤其在英语上表现优异,对欧洲语言的跨语言迁移能力稳健。
作者在 NanoBEIR 多语言基准上评估 LFM2-ColBERT-350M,13 个多样化检索任务与语言上平均 NDCG@10 达 0.661。模型展现出强大的多语言能力,在高资源与低资源语言上均保持一致性能,与 GTE-ModernColBERT-v1 基线相比性能差距显著缩小。