Command Palette
Search for a command to run...
HunyuanOCR 技术报告
HunyuanOCR 技术报告
摘要
本文介绍了 HunyuanOCR,这是一个面向光学字符识别(OCR)任务的商用级、开源且轻量化的视觉语言模型(VLM),参数量仅为10亿(1B)。该模型采用原生视觉Transformer(ViT)与轻量级大语言模型(LLM)通过MLP适配器连接的架构。HunyuanOCR在性能上表现出色,超越了主流商业API、传统流水线以及更大规模模型(如Qwen3-VL-4B)。具体而言,它在感知类任务(文本定位与检测、文本解析)方面优于现有公开解决方案,在语义类任务(信息抽取、文本图像翻译)中表现卓越,并在ICDAR 2025 DIMT挑战赛(小型模型赛道)中斩获第一名。此外,在OCRBench评测基准上,HunyuanOCR作为参数少于30亿的视觉语言模型,达到了该类别下的最先进(SOTA)水平。HunyuanOCR在三个关键维度实现了突破性进展:1)统一多功能性与高效性:在轻量化框架内全面支持文本定位、文本解析、信息抽取(IE)、视觉问答(VQA)及文本图像翻译等核心能力,有效克服了传统“专用OCR模型”功能单一与“通用VLM”效率低下的双重局限。2)端到端架构的简化设计:采用纯端到端建模范式,彻底摒弃对预处理模块(如版面分析)的依赖,从根本上解决了传统流水线中常见的误差传播问题,显著简化了系统部署流程。3)数据驱动与强化学习策略:我们验证了高质量数据在模型性能提升中的关键作用,并首次在业界证明,强化学习(Reinforcement Learning, RL)策略可为OCR任务带来显著的性能增益。HunyuanOCR已正式在HuggingFace平台开源。同时,我们提供基于vLLM的高性能部署方案,使模型在实际生产环境中的运行效率处于行业领先水平。我们期望该模型能够推动OCR领域前沿研究的发展,并为工业级应用提供坚实可靠的技术基础。
一句话总结
作者提出 HunyuanOCR,这是一个由腾讯及合作者开发的10亿参数开源视觉-语言模型,通过数据驱动训练和新颖的强化学习策略,采用轻量级架构(ViT-LLM MLP适配器)统一了端到端的OCR能力——包括文本定位、文档解析、信息抽取和翻译,性能超越更大模型和商业API,实现了工业与科研应用中的高效部署。
主要贡献
- HunyuanOCR 引入了一种轻量级(10亿参数)的端到端视觉-语言模型,将文本定位、文档解析、信息抽取、视觉问答和文本图像翻译等多种OCR任务统一在一个紧凑框架中,克服了传统窄管道系统和资源密集型通用VLM的局限性。
- 该模型采用原生ViT与轻量级LLM通过MLP适配器连接,基于2亿条高质量、面向应用的样本进行训练,并结合在线强化学习(GRPO),在OCRBench上达到最先进性能,并在ICDAR 2025 DIMT挑战赛(小型模型赛道)中获得第一名。
- 通过消除布局分析等预处理模块的需求,HunyuanOCR 实现了无误差传播的简化推理流程,并借助vLLM实现高部署效率,适用于低延迟、支持设备端运行的真实工业场景。
引言
作者利用视觉-语言模型(VLM)日益增强的能力,解决传统OCR系统长期存在的局限性——这些系统依赖复杂的级联管道,易受误差传播影响且维护成本高。尽管近期专用于OCR的VLM通过整合布局分析与识别提升了性能,但仍常依赖独立的布局检测模块,限制了真正的端到端学习与统一的多任务建模。为此,作者提出 HunyuanOCR,一个仅含10亿参数的紧凑、开源多语言VLM,采用完全端到端架构。该设计实现了对多种OCR任务(包括文本定位、文档解析、信息抽取、视觉问答和多语言翻译)的统一、单次推理,无需依赖中间处理阶段。模型在关键基准上达到最先进水平,超越开源与商业OCR系统,同时保持适合设备端部署的高推理效率。其成功源于以高质量、面向应用的数据为中心的训练策略,以及针对复杂知识密集型任务优化的强化学习框架。
数据集
- 数据集包含超过2亿张图像-文本对,数据来源包括公开基准、网络爬取的真实世界图像,以及专有的合成数据生成工具。
- 涵盖九类主要现实场景:街景、文档、广告、手写文本、截图、卡片/证书/发票、游戏界面、视频帧和艺术字体,支持超过130种语言。
- 数据筛选强调质量、多样性和难度平衡:使用LLM判断过滤高质量开源与合成数据集,确保图像-文本对齐并剔除易被利用的任务(如选择题);丢弃输出多样性低或奖励方差为零的样本以维持多样性;基于模型表现的通过率过滤机制,剔除过于简单或无法解决的样本。
- 数据用于多任务训练,训练划分设计反映真实使用场景,混合比例经过精心平衡,以确保在不同OCR与信息抽取(IE)场景下的鲁棒性。
- 在信息抽取方面,数据集包含30项IE任务,覆盖十余种卡片与证书类型(如身份证、护照、驾驶证、营业执照)和十余种收据类型(如购物小票、增值税发票、火车票、银行回单),推荐使用中英文双语指令以保证基准一致性。
- 元数据构建反映任务特定需求,未提及显式裁剪——而是通过精心选择与过滤原始及合成输入,确保自然场景的完整呈现。
方法
作者为 HunyuanOCR 设计了协作式架构,包含三个核心模块:原生分辨率视觉编码器、自适应MLP连接器和轻量级语言模型。该框架实现了对文本定位、解析、信息抽取、视觉问答和文本图像翻译等多样化OCR任务的统一端到端处理。该架构通过直接处理原始图像并单次生成结构化输出,消除了传统管道系统固有的误差传播问题。

原生分辨率视觉编码器基于SigLIP-v2-400M预训练模型,采用混合生成-判别联合训练策略,提升视觉语义理解能力。其利用自适应分块机制在原始分辨率下处理图像,保持原始宽高比,避免失真与细节丢失,尤其适用于长文本文档或极端宽高比场景。图像按其原始比例划分为图像块,所有块由具备全局注意力机制的视觉Transformer(ViT)处理,确保高保真特征提取。
自适应MLP连接器作为视觉与语言域之间的桥梁,实现可学习的池化操作,执行空间维度自适应内容压缩,将高分辨率视觉特征图的token序列长度降低。该过程在减少冗余的同时保留关键区域(如文本密集区)的语义信息,实现视觉特征向语言模型输入空间的高效、精准映射。
轻量级语言模型基于密集架构的Hunyuan-0.5B模型,引入XD-RoPE,将传统RoPE分解为四个独立子空间:文本、高度、宽度和时间。该设计建立原生对齐机制,连接一维文本序列、二维页面布局与三维时空信息,使模型能够逻辑推理地处理复杂布局解析与跨页文档分析。模型采用全端到端训练,无需后处理及由此带来的误差累积,从而在混合布局文档理解等复杂场景中表现出更强鲁棒性。
实验
- 在包含900张图像的内部基准上评估HunyuanOCR,覆盖九类文本定位任务(艺术、文档、游戏、手写、广告、卡片/发票、屏幕截图、街景、视频),作为端到端视觉-语言模型达到最先进性能,以显著更少参数超越基于管道的方法和更大通用VLM。
- 在OmniDocBench及其Wild变体上,HunyuanOCR在数字、扫描和真实拍摄文档的文档解析任务中均取得最佳结果,尽管参数量仅为10亿,仍超越更大专用模型;在DocML上,使用编辑距离指标实现14种非中文/英文语言的最先进多语言解析性能。
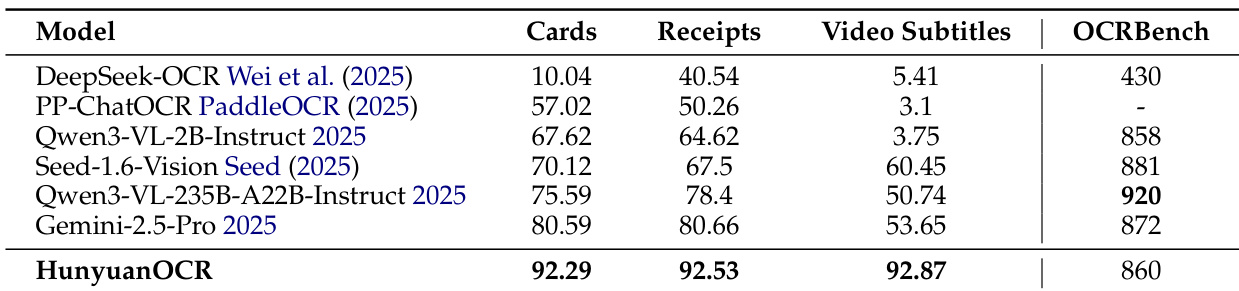
- 在信息抽取与视觉问答任务中,HunyuanOCR在30类文档与视频字幕上达到最高准确率,超越Qwen3VL-235B-Instruct和Gemini-2.5-Pro等更大模型,并在OCRBench上与Qwen3VL-2B-Instruct持平或超越。
- 在文本图像翻译任务中,HunyuanOCR在DoTA上超越参数超过80亿的VLM,并在ICDAR 2025 Track 2中获得第一名,展现出强大的多语言与复杂布局翻译能力,在内部DocML基准上也优于更大模型。
- 强化学习显著提升性能:艺术与屏幕场景的定位得分提升超过2分,OmniDocBench的解析得分从92.5升至94.1,IE与VQA任务提升约2分,OCRBench平均得分提升3.3分,归因于细粒度规则奖励与LLM作为裁判的奖励机制。
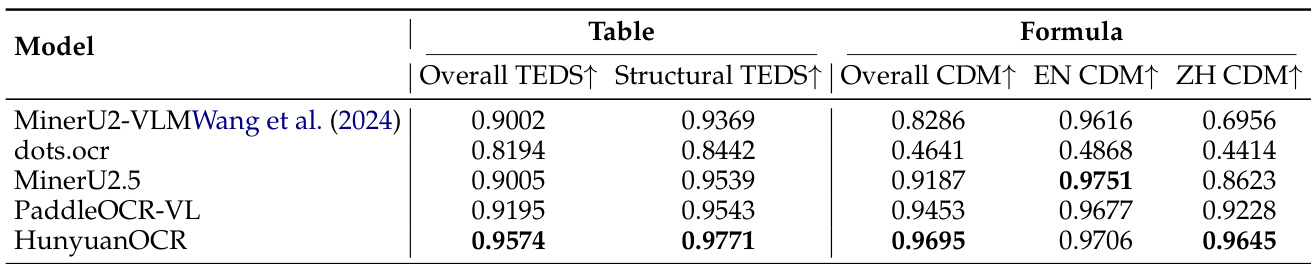
- 元素级评估显示,HunyuanOCR在OmniDocBench-Formula-block与OmniDocBench-Table-block上表现出色,使用针对性提示生成LaTeX与HTML输出时精度极高。
- 定性结果表明,HunyuanOCR在密集、复杂与艺术性文档中具备稳健的文本定位与解析能力,输出坐标准确,结构化Markdown完整,语义理解正确,适用于多样现实场景。
作者使用HunyuanOCR在OmniDocBench上评估文档解析性能,取得94.10的最高总分,超越所有其他模型(包括更大模型)。结果表明,HunyuanOCR在文本定位、视觉问答与文本翻译任务中同样领先,尽管参数量仅为10亿,仍展现出强大泛化能力。
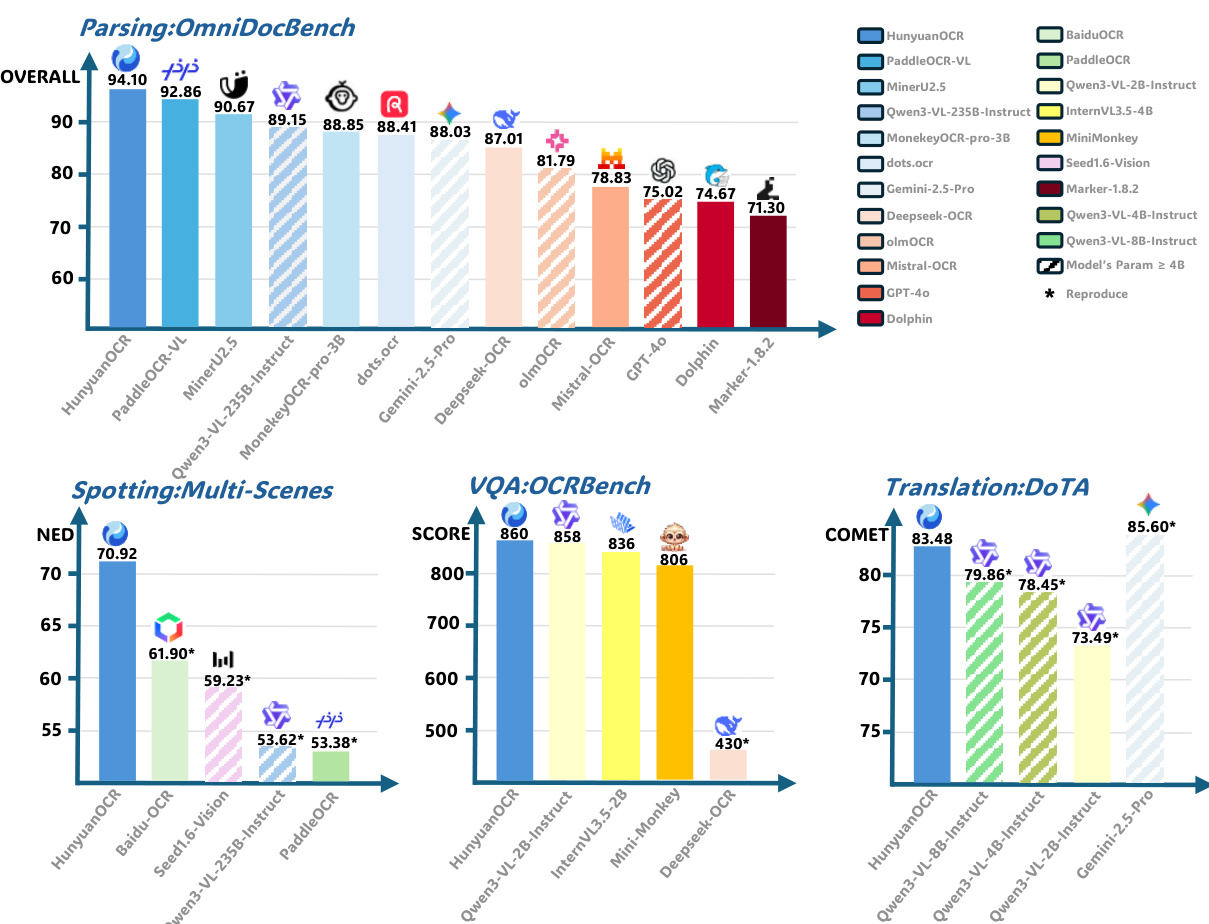
作者采用恒定学习率8e-7、Adam优化器和全局批量大小512的强化学习设置训练HunyuanOCR。在生成rollout时,每条提示采样8个响应,温度设为0.85,top-p设为0.95,以确保奖励评估所需的多样化候选输出。
作者使用HunyuanOCR在900张图像的基准上评估九类不同场景的文本定位性能,包括艺术文本、文档和视频帧。结果表明,HunyuanOCR在整体性能上表现最佳,显著超越传统基于管道的方法和通用视觉-语言模型,且参数量远少于后者。
结果表明,HunyuanOCR在所有评估任务中均达到最高整体准确率,在卡片与收据信息抽取、视频字幕提取以及OCRBench任务中,超越Qwen3-VL-235B-Instruct和Gemini-2.5-Pro等更大模型。该模型仅用约10亿参数即实现信息抽取与视觉问答的最先进性能,充分展现其紧凑架构的强大能力。
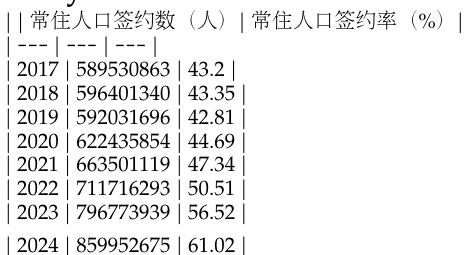
作者使用表格展示2017年至2024年居民人口与登记率的年度数据,显示居民人数与登记率逐年持续上升。数据显示,居民人口从2017年的5.895亿增长至2024年的8.599亿,同期登记率从43.2%上升至61.02%。