Command Palette
Search for a command to run...
PrismAudio:面向视频到音频生成的分解式思维链与多维奖励机制
PrismAudio:面向视频到音频生成的分解式思维链与多维奖励机制
Huadai Liu Kaicheng Luo Wen Wang Qian Chen Peiwen Sun Rongjie Huang Xiangang Li Jieping Ye Wei Xue
摘要
视频到音频(Video-to-Audio, V2A)生成需要在四个关键感知维度上取得平衡:语义一致性、视听时间同步性、美学质量以及空间准确性。然而,现有方法存在目标纠缠问题,即在单一损失函数中混淆了相互竞争的目标,且缺乏对人类偏好的对齐。为此,我们提出了 PrismAudio,这是首个将强化学习(Reinforcement Learning, RL)引入 V2A 生成并集成专用思维链(Chain-of-Thought, CoT)规划框架的模型。该方法将整体推理过程解耦为四个专用 CoT 模块(语义 CoT、时间 CoT、美学 CoT 和空间 CoT),每个模块均配备针对性的奖励函数。这种 CoT 与奖励函数的对应关系使得多维 RL 优化成为可能,引导模型在所有视角上协同生成更优的推理结果,从而在保持可解释性的同时解决了目标纠缠问题。为使该优化在计算上切实可行,我们提出了 Fast-GRPO,其采用混合 ODE-SDE 采样策略,相较于现有的 GRPO 实现显著降低了训练开销。此外,我们构建了 AudioCanvas 基准测试集,该数据集在分布上更为均衡,覆盖了比现有数据集更丰富、更具挑战性的真实场景,包含 300 个单事件类别和 501 个多事件样本。实验结果表明,PrismAudio 在域内 VGGSound 测试集和域外 AudioCanvas 基准测试集上,于全部四个感知维度均取得了最先进(state-of-the-art)的性能。
一句话总结
来自香港科技大学、阿里巴巴集团和香港中文大学的研究人员推出了 PrismAudio,这是首个通过专门的思维链规划将强化学习整合到视频到音频生成中的框架。该规划将推理分解为语义、时间、美学和空间模块,并配以针对性奖励以解决目标纠缠问题,同时保持可解释性,此外还包括用于降低训练开销的 Fast-GRPO 以及包含 300 个单事件类别和 501 个多事件样本的 AudioCanvas 基准测试。
核心贡献
- 作者介绍了 PrismAudio,这是首个将强化学习整合到视频到音频生成中的框架,并采用专门的思维链规划。该方法将推理分解为四个专门的 CoT 模块,并配以针对性奖励函数,以解决目标纠缠问题,同时保持可解释性。
- 为了确保计算实用性,作者提出了 Fast-GRPO,这是一种采用混合 ODE-SDE 采样的优化方法。与现有的 GRPO 实现相比,该技术显著降低了训练开销。
- 作者还介绍了 AudioCanvas,这是一个严格的基准测试,比现有数据集具有更好的分布平衡性,并涵盖了更多现实多样且具挑战性的场景。它包含 300 个单事件类别和 501 个多事件样本以支持评估。
引言
视频到音频生成需要平衡语义一致性、时间同步性、美学质量和空间准确性,以便从无声视频中合成声景。现有方法存在目标纠缠问题,即竞争目标在单个损失函数中混淆,且缺乏人类偏好对齐。最近的思维链方法由于单体规划无法独立解决不同的感知维度而进一步失败。作者介绍了 PrismAudio,它将强化学习与每个感知轴的专门思维链模块整合在一起。这种分解使得多维强化学习优化能够指导所有视角的推理,同时保持可解释性。为了降低训练开销,他们提出了使用混合 ODE-SDE 采样的 Fast-GRPO。此外,团队还推出了 AudioCanvas,这是一个针对多样化场景的严格基准测试,在所有维度上实现了最先进的性能。
数据集
- 作者使用 AudioSet 本体中的 300 个不同类别构建 AudioCanvas,专注于音效和音乐,同时排除人声和歌唱。
- 最终基准包含 3,177 个高质量视频,包括一个精心策划的 501 个多事件视频子集,旨在评估复杂场景交互。
- 过滤协议自动丢弃现有 V2A 模型获得近乎完美分数的样本,而专业专家手动筛选多样性和音视频相关性。
- Gemini 2.5 Pro 生成涵盖语义、时间、美学和空间维度的结构化思维链标题,随后由文本大语言模型将其解耦为单独的模块。
- 该数据集支持高级基准测试和视频 LLama2 等模型的微调,访问权限通过正式申请流程限制给学术研究人员。
- 通过提供参考链接而非原始视频重新分发,并为所有内容使用匿名标识符,维持隐私和伦理标准。
方法
所提出的方法 PrismAudio 通过包含 CoT 感知音频基础模型、用于推理分解的定制 CoT 模块和 GRPO 后训练框架的三阶段管道运行。整体架构整合了这些组件,以实现具有多维推理能力的高质量视频到音频生成。
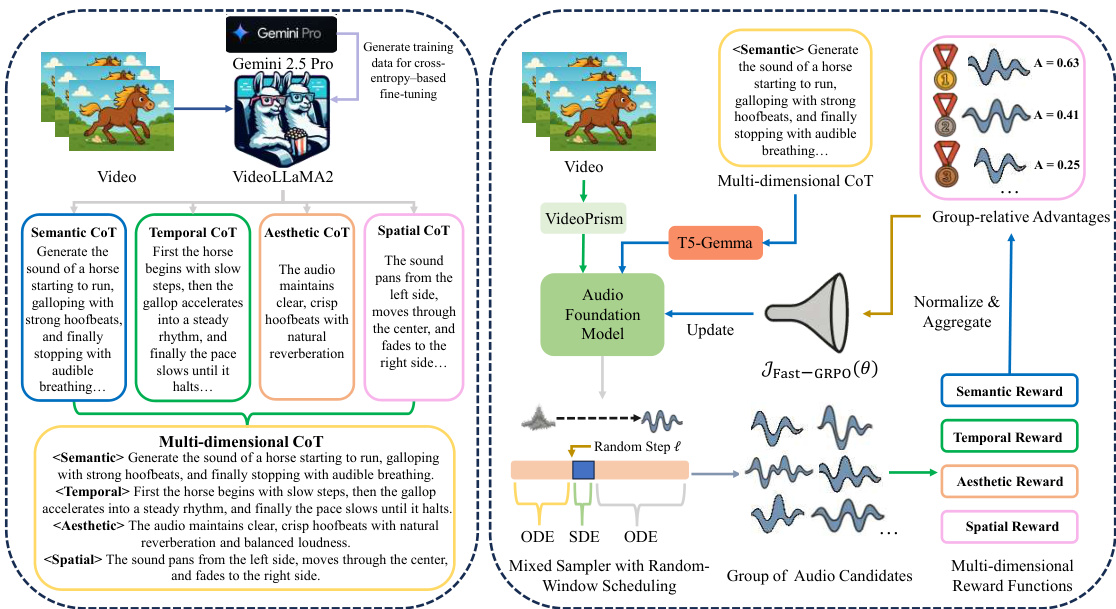
CoT 感知音频基础模型 核心生成模型建立在利用流匹配的扩散变压器骨干之上。为了克服现有模型在处理复杂视频场景和结构化推理文本方面的局限性,作者实施了两个关键架构增强。首先,他们用 VideoPrism 替换了标准的基于 CLIP 的编码器,这是一种最先进的视频编码器,旨在捕捉物体、动作和环境上下文的丰富语义表示。其次,为了有效地使模型适应多维 CoT 所需的结构化推理模式,标准 T5 编码器升级为 T5-Gemma。这种编码器 - 解码器架构适应了仅解码器大语言模型的推理能力,使模型能够稳健地理解由 CoT 模块生成的分析文本。
分解多维 CoT 推理 为了解决单体推理路径的局限性,该方法将视频到音频推理分解为四个专门维度:语义、时间、美学和空间。语义 CoT 识别音频事件和特征,而时间 CoT 确定这些事件的顺序。美学 CoT 专注于自然度和保真度等质量方面,空间 CoT 分析声音定位和距离。Gemini 2.5 Pro 用于构建这些维度的高质量训练数据。然后使用这些数据微调 VideoLLaMA2,使其能够生成四个专门的 CoT。这些不同的推理文本被连接起来形成多维 CoT,作为音频基础模型的增强结构化文本条件。
Fast-GRPO 后训练框架 最后阶段使用 Fast-GRPO 框架将音频基础模型与多维人类偏好对齐。该过程涉及四个与 CoT 维度相对应的专门奖励函数:语义奖励(通过 MS-CLAP 测量)、时间奖励(通过 Synchformer 评估)、美学奖励(使用 Meta Audiobox Aesthetics)和空间奖励(采用 StereoCRW)。为了在这些目标上高效优化,作者引入了带有随机窗口调度的混合采样器。虽然流匹配生成本质上是确定性的(一个 ODE),但它被重新表述为随机过程(一个 SDE)以启用基于 RL 的优化。Fast-GRPO 算法策略性地将随机性限制在生成轨迹内随机放置的小时间窗口中。对于每个训练迭代,采样一个起始位置 ℓ 以定义宽度为 w≪T 的优化窗口 W(ℓ):
W(ℓ)={ℓ,ℓ+1,…,ℓ+w−1}.生成过程基于此窗口交错进行确定性 ODE 步骤和随机 SDE 步骤。对于步长 Δt,更新规则为:
xt+1={xt+vθ(xt,t,c)Δt,xt+μSDE(xt,t,c)Δt+σtΔtεt,if t∈/W(ℓ)(ODE step)if t∈W(ℓ)(SDE step)其中 εt∼N(0,I),vθ 是模型预测的速度。这种混合方法允许进行可处理的策略比率计算,并减少每个样本的函数评估次数 (NFE),从而实现近线性复杂度训练。策略模型通过最大化以下目标进行优化,该目标源自限制在选定 SDE 步骤上的 Fast-GRPO 公式:
JFast−GRPO(θ) = Ec,ℓ,{xi}∼πθoldN1i=1∑Nw1t∈W(ℓ)∑min(rti(θ)Ai,clip(rti(θ),1−ε,1+ε)Ai).其中 Ai 是从多维奖励的加权和计算出的组归一化优势。
实验
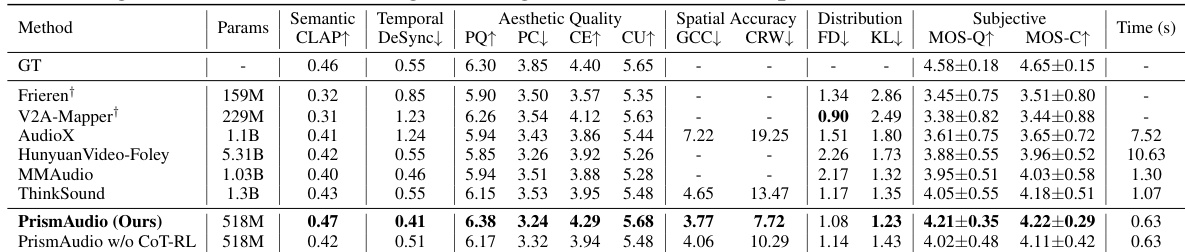
该研究在 VGGSound 测试集和新引入的 AudioCanvas 基准测试上评估性能,使用全面的客观指标和主观平均意见得分来评估语义、时间、空间和美学维度。结果表明,PrismAudio 通过采用多维思维链强化学习框架实现了最先进的性能,该框架有效地平衡了竞争感知目标,而消融分析证实结构化分解推理对于在复杂场景中保持稳健性至关重要。定性比较进一步突出了模型在保留高频细节和准确瞬态响应方面优于现有方法的能力。
下表比较了各种思维链推理策略,范围从无推理基线到提出的多维方法。结果表明,与无结构或单块方法相比,结构化、分解的推理显著提高了语义、时间和美学指标的性能。MultiCoT 方法实现了最佳总体得分,验证了高质量生成逻辑规划的必要性。MultiCoT 实现了最高的语义对齐和时间同步得分。结构化推理策略优于随机或非结构化方法。分解推理产生的美学质量优于单体方法。

作者在 VGGSound 测试集上评估了所提出的方法与竞争性基线。结果表明,与之前的模型相比,PrismAudio 在语义、时间和美学维度上实现了更优越的性能。消融研究进一步表明,CoT-RL 框架为基础模型提供了实质性改进。PrismAudio 在音频质量和一致性方面获得了最高的主观得分。所提出的方法在空间准确性和时间同步性方面优于基线。CoT-RL 优化为基础模型带来了显著的性能提升。
实验评估了不同思维链推理结构对音频生成质量的影响。结果表明,与无结构或单体方法相比,结构化、分解的推理在语义、时间和美学维度上显著优于后者。MultiCoT 在语义理解和美学质量方面优于单体 CoT。没有 CoT 推理的基线模型在所有评估指标上表现不佳。与随机关键词排序相比,结构化逻辑计划对于高质量生成至关重要。

作者使用 AudioCanvas 基准测试评估视频编码器在检索任务上的表现。VideoPrism 在所有场景复杂性下均实现了比 CLIP 和 X-CLIP 显著更高的召回分数。性能差距在多事件场景中尤为大,突显了 VideoPrism 的稳健性。VideoPrism 在所有场景类别中实现了最高的召回分数。性能优势在复杂的多事件场景中最为显著。VideoPrism 在基线退化的情况下保持了稳健的检索准确性。

作者比较了文本编码器以验证其处理结构化推理的能力。T5-Gemma 在顺序理解和因果逻辑指标上始终优于 T5-Base 和 T5-Large。这些发现支持选择指令微调模型来处理复杂的思维链描述。T5-Gemma 在顺序理解任务中实现了最高得分。T5-Gemma 的因果推理能力显著更强。与基线相比,T5-Gemma 的多步推理准确率保持较高水平。

实验通过比较音频生成、视频检索和文本编码任务验证了所提出的框架。结果表明,与无结构方法相比,结构化、多维思维链推理和 CoT-RL 优化显著增强了语义对齐和时间同步。此外,VideoPrism 和 T5-Gemma 等组件在复杂场景检索和因果逻辑方面表现出卓越的稳健性,证实了指令微调模型对于高质量生成的必要性。