Command Palette
Search for a command to run...
SoulX-Podcast:面向具有方言与副语言多样性的真实感长篇播客
SoulX-Podcast:面向具有方言与副语言多样性的真实感长篇播客
摘要
近年来,文本到语音(TTS)合成技术取得了显著进展,大幅提升了语音的表达力与自然度。然而,现有大多数系统主要针对单说话人场景设计,在生成连贯的多说话人对话语音方面仍存在明显不足。本技术报告介绍了一种名为SoulX-Podcast的新型系统,该系统专为播客风格的多轮、多说话人对话式语音生成而设计,同时在传统TTS任务中也达到了当前最优水平。为满足多轮口语对话对更高自然度的需求,SoulX-Podcast集成了多种副语言控制机制,支持普通话、英语以及多种汉语方言(包括四川话、河南话和粤语),从而实现更具个性化的播客式语音生成。实验结果表明,SoulX-Podcast能够持续生成超过90分钟的对话内容,保持稳定的说话人音色,并实现平滑的说话人切换。此外,系统生成的语音表现出情境自适应的韵律特征,能够自然地反映对话推进过程中语调与节奏的变化。在多项评估指标下,SoulX-Podcast在单人独白TTS与多轮对话语音合成任务中均达到了当前最先进的性能水平。
一句话总结
西北工业大学、Soul AI 实验室和上海交通大学的作者提出 SoulX-Podcast,一种新型多说话人对话式文本转语音系统,能够生成自然、上下文感知且长篇幅的播客风格语音,支持普通话、英语及多种汉语方言,通过先进的副语言控制与说话人一致性机制,在单人独白和多轮对话合成任务中均达到当前最优性能。
主要贡献
- SoulX-Podcast 通过引入基于大语言模型的框架,解决生成自然、长篇幅多说话人对话语音的挑战,该框架对带有说话人标签的交错文本-语音序列进行建模,实现多轮对话中连贯、上下文感知的语音合成。
- 系统支持多种语言和方言——包括普通话、英语、四川话、河南话和粤语——并实现跨方言零样本语音克隆,仅需一个音频提示即可在任意支持方言中生成具有稳定说话人身份的语音。
- 实验结果表明,SoulX-Podcast 可生成超过 90 分钟稳定、高质量的对话语音,具备平滑的说话人切换和上下文自适应的语调,同时在多轮对话合成与传统文本转语音任务中均达到当前最优性能。
引言
作者利用大语言模型(LLM)与离散语音标记化技术推进文本转语音(TTS)合成,填补了多说话人、长篇幅对话语音生成中的关键空白。尽管现有 TTS 系统在单说话人、独白合成方面表现优异,但在长对话中难以维持自然的语调、说话人一致性与整体连贯性,尤其在多样语言语境下更为明显。现有对话式 TTS 方法或缺乏细粒度的副语言控制,或无法支持方言变化,限制了真实感与个性化表达。为克服这些局限,作者提出 SoulX-Podcast,一个统一框架,支持普通话、英语及多种汉语方言(包括四川话、河南话、粤语)的长篇、多轮播客式语音合成,并实现跨方言零样本语音克隆。该系统对带有说话人标签与副语言控制的交错文本-语音序列进行建模,确保说话人身份稳定、语调上下文感知且转换平滑。在对话合成与传统 TTS 任务中均达到当前最优性能,展现出在生成超过 90 分钟自然、连贯对话方面的强大鲁棒性与通用性。
数据集
- 数据集包含约 0.3 百万小时的自然对话语音与约 1.0 百万小时的独白数据,总计约 1.3 百万小时的高质量语音用于训练。
- 对话数据来源于公开播客录音与真实场景语音,通过两阶段流程添加方言与副语言标注。
- 副语言标注方面,作者首先使用特定语言的 ASR 模型——中文使用 Beats,英文使用 Whisperd——对非语言信号(如笑声、叹气)进行粗粒度检测。
- 第二阶段,使用 Gemini-2.5-Pro API 验证并优化这些检测结果,生成精确、时间对齐的副语言标签,并进行细粒度分类。
- 该流程最终获得约 1,000 小时带有详细副语言标注的语音。
- 方言数据通过两种方式获取:直接采集四川话、粤语、河南话的公开录音,以及使用训练好的方言识别模型从更广泛数据集中提取方言语句。
- 方言语音的转录使用 Seed-ASR API 生成,因标准 ASR 流水线存在局限,最终获得约 2,000 小时四川话、1,000 小时粤语与 500 小时河南话语音。
- 该数据集用于训练 SoulX-Podcast 模型,对话与独白子集以优化混合比例组合,以实现富有表现力、上下文感知的对话合成。
- 未提及显式裁剪,但数据在标注过程中经过仔细过滤与对齐,以确保高保真度与时间精度。
- 方言与副语言线索的元数据在标注过程中构建,支持合成阶段对语音输出的细粒度控制。
方法
作者采用两阶段生成框架,用于长篇幅、多说话人、多方言对话语音合成,如架构图所示。该框架名为 SoulX-Podcast,首先由大语言模型(LLM)预测语义标记,随后通过流匹配转换为声学特征,最终由声码器合成波形音频。LLM 主干基于预训练的 Qwen3-1.7B 模型,其文本词典扩展以包含语音标记及用于编码副语言与方言属性的特殊标记。
参见框架图 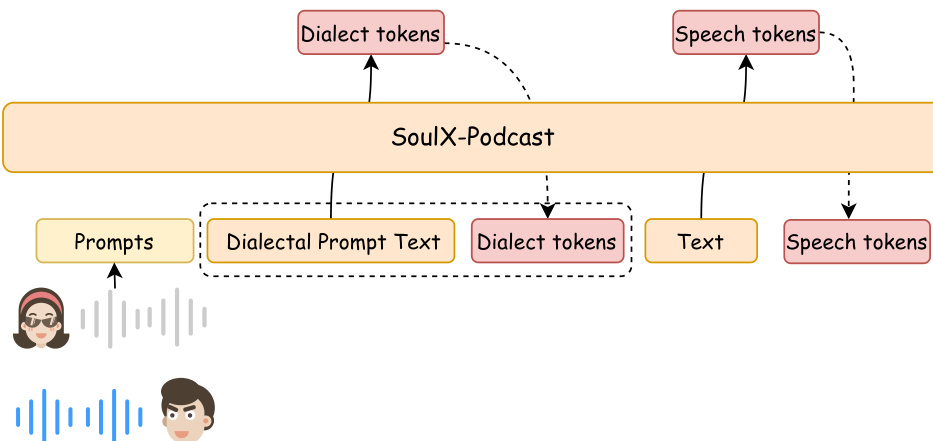 。
。
模型采用交错的文本-语音标记组织方式,以实现灵活的多轮对话生成。序列中每个语句以说话人标记开头以标识身份,随后是方言特定标记用于方言控制,再接文本标记。副语言线索作为文本标记处理,并置于序列中对应位置。该结构支持以连贯、逐轮方式合成具有稳定说话人身份、方言特征与副语言表达的语音。
训练过程采用课程学习策略,以有效利用异构数据模式。首先,LLM 主干在独白与对话数据混合集上训练,建立基础的文本到语音能力。随后,模型在中英文多说话人对话数据上进一步训练,融入方言与副语言元素。为应对中文方言数据稀缺问题,额外在方言数据上进行微调,以增强模型的方言生成能力。为应对长音频生成挑战,引入上下文正则化机制,逐步丢弃历史语音标记,同时保留其文本上下文。这促使模型依赖语义连续性而非低层声学记忆,从而提升长对话合成中的连贯性与稳定性。
如图所示: 。
。
推理阶段,模型遵循训练时建立的标记组织方式,以自回归方式交错生成多个说话人的文本与语音标记。针对跨方言语音克隆,作者提出一种方言引导提示(Dialect-Guided Prompting, DGP)策略,以解决从普通话提示生成目标方言时控制信号较弱的问题。该策略通过在输入文本前添加简短的、具有方言特征的句子,有效引导模型在后续生成中输出具有目标方言特征的语音。
实验
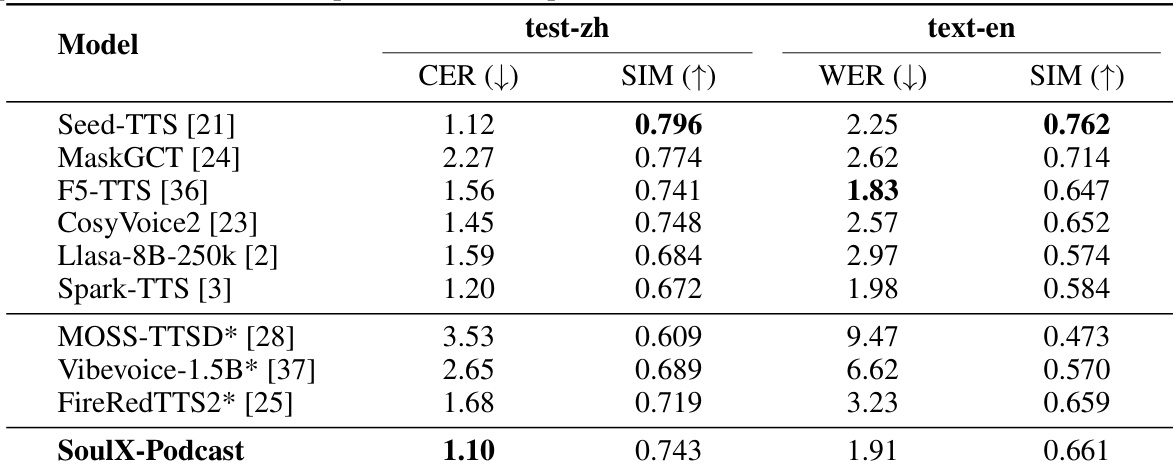
- 在独白语音合成任务上评估 SoulX-Podcast:在中文测试集上达到最低 CER,在英文测试集上达到第二低 WER,零样本 TTS 下说话人相似度排名仅次于 Seed-TTS 与 MaskGCT。
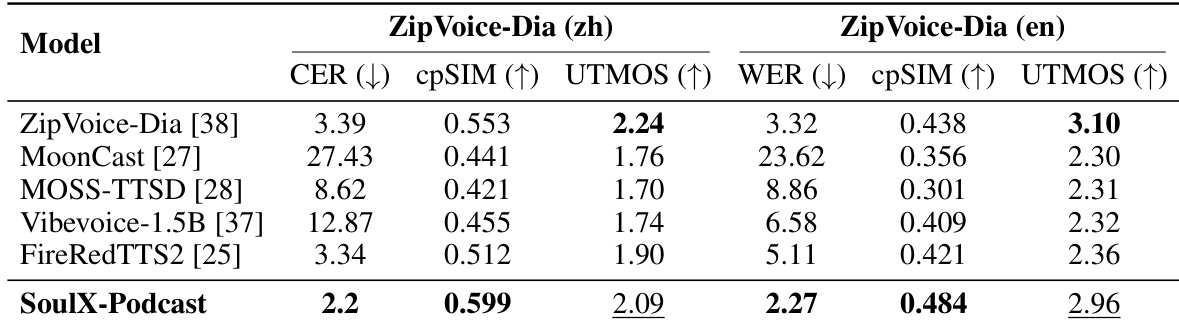
- 在多轮、多说话人播客生成任务中表现卓越:在 ZipVoice-Dia 测试集上达到最低 WER/CER 与最高跨说话人相似度(cpSIM),UTMOS 得分具有竞争力。
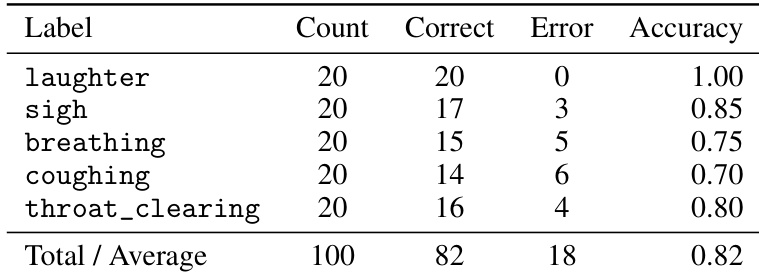
- 验证副语言控制能力:对五类副语言事件的整体识别准确率达 82%,对 实现近乎完美的控制,对 与 <throat_clearing> 保持高保真度,但对细微事件如 (75%)与 (70%)准确率较低。
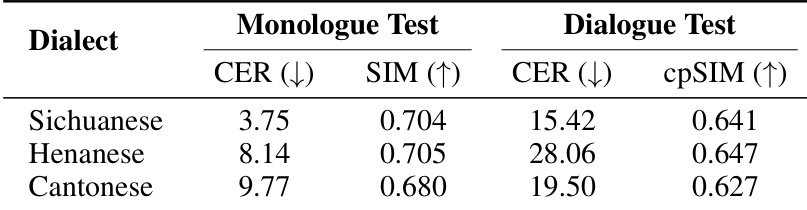
- 在四川话、河南话与粤语中展现强大方言能力:在所有方言中保持与普通话和英语相当的说话人相似度,CER 值较高可能源于 ASR 系统局限。
结果表明,SoulX-Podcast 在副语言事件控制方面表现强劲,五类标签整体识别准确率达 0.82。模型在笑声控制上近乎完美,对叹气与清嗓也表现出高保真度,但对呼吸与咳嗽等细微事件的准确率较低。
结果表明,SoulX-Podcast 在 ZipVoice-Dia 基准测试中优于现有多说话人 TTS 系统,中英文测试中均实现最低 CER 与 WER,同时保持最高跨说话人一致性(cpSIM)与具有竞争力的 UTMOS 得分,表明其在多轮对话生成中具备优异的说话人连贯性与高感知质量。
作者在三种汉语方言——四川话、河南话与粤语——的独白与对话场景下评估 SoulX-Podcast 的性能。结果表明,所有方言中均保持一致的说话人相似度,CER 值反映不同可懂度水平,其中四川话在独白合成中达到最低 CER,粤语在对话合成中表现最佳。
结果表明,SoulX-Podcast 在中文测试集上达到最低 CER,在英文测试集上排名第二,展现出在零样本独白语音合成中的强大性能。同时在两种语言评估中均实现高说话人相似度,排名仅次于 Seed-TTS 与 MaskGCT。