Command Palette
Search for a command to run...
LongCat-Video 技术报告
LongCat-Video 技术报告
摘要
视频生成是构建世界模型的关键路径,而高效生成长时视频的能力则是其中的核心技术之一。为此,我们推出了LongCat-Video——一款参数量达136亿的基础视频生成模型,在多项视频生成任务中均展现出卓越性能,尤其在高效且高质量的长视频生成方面表现突出,标志着我们在构建世界模型道路上迈出的初步步伐。其核心特性包括:统一架构支持多任务:基于扩散Transformer(Diffusion Transformer, DiT)框架,LongCat-Video 采用单一模型即可支持文本到视频(Text-to-Video)、图像到视频(Image-to-Video)以及视频续写(Video-Continuation)等多种任务;长视频生成能力:通过在视频续写任务上进行预训练,LongCat-Video 能够在生成数分钟长度的视频时,保持出色的视觉质量与时间连贯性;高效推理机制:采用时空双维度的粗到精生成策略,可在数分钟内生成720p、30fps的高质量视频;结合块稀疏注意力(Block Sparse Attention)机制,显著提升高分辨率下的推理效率;基于多奖励强化学习人类反馈(Multi-reward RLHF)的强性能表现:通过多奖励机制的强化学习人类反馈训练,LongCat-Video 的性能已达到与最新闭源模型及领先开源模型相当的水平。目前,相关代码与模型权重已公开发布,旨在推动该领域研究的快速发展。
一句话总结
美团龙猫团队提出 LongCat-Video,一个136亿参数的扩散Transformer模型,统一了文本到视频、图像到视频和视频续写任务,通过粗到细采样和块稀疏注意力实现高效、高质量的分钟级视频生成,多奖励强化学习人类反馈(RLHF)进一步提升性能,达到领先闭源与开源模型水平,推动可扩展世界模型的发展。
主要贡献
- LongCat-Video 是一个136亿参数的基础模型,通过单一扩散Transformer(DiT)架构统一了文本到视频、图像到视频和视频续写任务,支持基于零、一或多个输入帧的条件生成,实现灵活多样的视频生成能力。
- 该模型通过在视频续写任务上预训练,实现高质量、分钟级视频生成,显著提升时间连贯性并防止长序列中的质量退化,这是世界模型应用的关键需求。
- 通过粗到细生成策略和块稀疏注意力机制实现高效推理,将注意力计算量降至密集注意力的10%以下,可在数分钟内生成720p、30fps视频,且在内部和公开基准测试中性能媲美领先开源与闭源模型。
引言
作者利用扩散建模技术开发了 LongCat-Video,一个136亿参数的基础模型,专为通用视频生成设计,尤其注重长时、高质量输出。该工作在推进世界模型方面具有重要意义,其中视频生成是模拟和预测现实世界动态的关键机制,广泛应用于数字人、自动驾驶和具身AI等领域。以往方法在长视频生成中难以保持时间连贯性,主要受限于误差累积和密集注意力带来的高计算成本,且多数模型为任务专用或需后期微调才能生成长视频。作者的核心贡献在于提出一种统一架构,通过输入帧数量的条件控制,原生支持文本到视频、图像到视频和视频续写任务,实现无缝任务切换。关键的是,LongCat-Video 在视频续写任务上进行预训练,使其能够无退化地生成分钟级视频。为保障效率,模型采用粗到细生成策略和块稀疏注意力机制,将注意力计算量压缩至密集注意力的10%以下。此外,基于多奖励GRPO的强化学习人类反馈(RLHF)增强了与多种质量指标的对齐,最终性能与领先商业及开源模型相当。
数据集
- 数据集源自多样化的原始视频源,并通过两阶段流程构建:数据预处理与数据标注。
- 在预处理阶段,视频从多个来源获取,通过源视频ID和MD5哈希去重,使用PySceneDetect和自研TransNetV2模型分割为连贯片段,并通过FFMPEG裁剪去除黑边。
- 处理后的片段进行压缩并打包,以支持训练过程中的高效加载与清洗。
- 在标注阶段,每个片段均附加全面的元数据信息,包括时长、分辨率、帧率、码率、美学评分、模糊度评分、文本覆盖率、水印检测结果以及基于光流提取的运动强度。
- 视频内容通过微调后的LLaVA-Video模型描述,结合合成视频-文本对和Tarsier2数据,提升对时间动作的理解能力。
- 电影摄影元素(如镜头运动(平移、俯仰、变焦、鲨鱼镜头)、镜头大小、镜头类型)通过自定义分类器和Qwen2.5VL模型进行标注。
- 视觉风格属性(如写实、2D动漫、3D卡通、色彩基调)也使用Qwen2.5VL提取,以实现丰富的语义表达。
- 通过中英文互译、生成简洁摘要以及随机组合字幕元素与电影摄影和风格属性,实现字幕增强,提升多样性。
- 对字幕的文本嵌入进行聚类分析,实现无监督分类,划分为个人互动、艺术表演、自然景观等内容类型。
- 聚类标签用于指导数据平衡与补充,确保各类别分布均匀。
- 最终数据集在训练中采用灵活的子集混合比例,适配不同训练目标,并基于元数据进行针对性过滤,以保障高质量与多样性。
方法
作者采用扩散Transformer(DiT)架构作为 LongCat-Video 的核心框架,该136亿参数模型专为高效长视频生成设计。模型采用标准DiT结构,包含单流Transformer块,每个块包含3D自注意力层、用于文本条件的交叉注意力层,以及使用SwiGLU激活函数的前馈网络(FFN)。调制部分采用AdaLN-Zero,每个块内嵌入专用调制MLP。为增强训练稳定性,自注意力与交叉注意力模块中均采用RMSNorm作为QKNorm。视觉token的位置编码通过3D RoPE实现。模型处理由WAN2.1 VAE生成的潜在表示,该VAE将视频像素压缩为潜在变量,经初始patchify操作后总压缩比为4×16×16。文本条件由umT5多语言文本编码器处理。
该模型被设计为统一框架,支持文本到视频、图像到视频和视频续写任务。通过将所有任务定义为视频续写,模型在给定前序帧条件下预测未来帧。输入包含两个序列:无噪声条件序列Xcond和含噪声序列Xnoisy,沿时间轴拼接。时间步同样分区,tcond设为0以注入清晰信息,tnoisy从[0, 1]中采样。该配置使模型能根据输入模式区分不同任务。采用专用块注意力机制,条件token在自注意力中独立处理,且不参与交叉注意力。该设计支持条件token的键值(KV)特征缓存,对推理阶段高效生成长视频至关重要。
训练过程分为三个主要部分:基础模型训练、RLHF训练和加速训练。基础模型训练从渐进式预训练开始,先在低分辨率图像上学习视觉表征,再过渡到视频训练以捕捉运动动态,最后联合优化多个任务。随后在高质量、精炼数据集上进行监督微调(SFT)。模型采用流匹配框架,网络预测扩散过程的速度场vt。损失函数为预测值与真实速度场之间的均方误差。训练采用类似logit-normal的损失加权方案,并根据噪声token体积调整时间步偏移。
在RLHF训练中,作者采用基于组相对策略优化(GRPO)的流匹配模型。为应对收敛慢和奖励优化复杂等挑战,引入多项技术。关键创新在于固定SDE采样中的随机时间步:每条提示随机选择一个关键时间步t′,仅在t′处应用带噪声注入的SDE采样,其余时间步采用确定性ODE采样,从而实现精确信用分配。同时采用截断噪声调度与基于阈值的裁剪机制,稳定高噪声水平下的采样。此外,对策略损失与KL损失进行重加权,以归一化梯度幅值,消除时间与步长依赖。相对优势通过所有组中观察到的最大标准差计算,以提升训练稳定性。最终训练目标为策略损失与KL散度的重加权和。
为实现高效推理,模型采用粗到细生成策略。基础模型首先生成低分辨率(480p)、低帧率(15fps)视频。该视频随后通过三线性插值上采样至720p、30fps,并由LoRA微调的精炼专家进行优化。精炼专家通过流匹配学习上采样视频与目标高分辨率视频之间的变换。精炼阶段的训练输入为上采样视频的噪声版本,真实标签为指向目标视频的速度场。该方法显著提升效率与质量。精炼过程还扩展至图像到视频和视频续写任务,通过在精炼输入中引入高分辨率条件帧实现。
为进一步加速训练与推理,作者实现了一种可训练的3D块稀疏注意力(BSA)机制。该算子将视频潜在表示划分为非重叠的3D块,仅在查询块与若干相似度最高的关键块之间计算注意力,相似度基于其平均值确定。该方法将计算负载降至原始值的10%以下,同时保持近乎无损的质量。BSA算子在Triton中实现,支持通过环形注意力实现上下文并行,可高效训练大规模模型。采用top-k块选择模式,因其简单且高效。
实验
- 基于HPSv3的视觉质量、VideoAlign的运动质量及文本-视频对齐奖励的多奖励训练有效防止奖励欺骗,实现视频生成各方面的均衡优化,如图8所示,并通过泛化能力提升与过拟合减少得到验证。
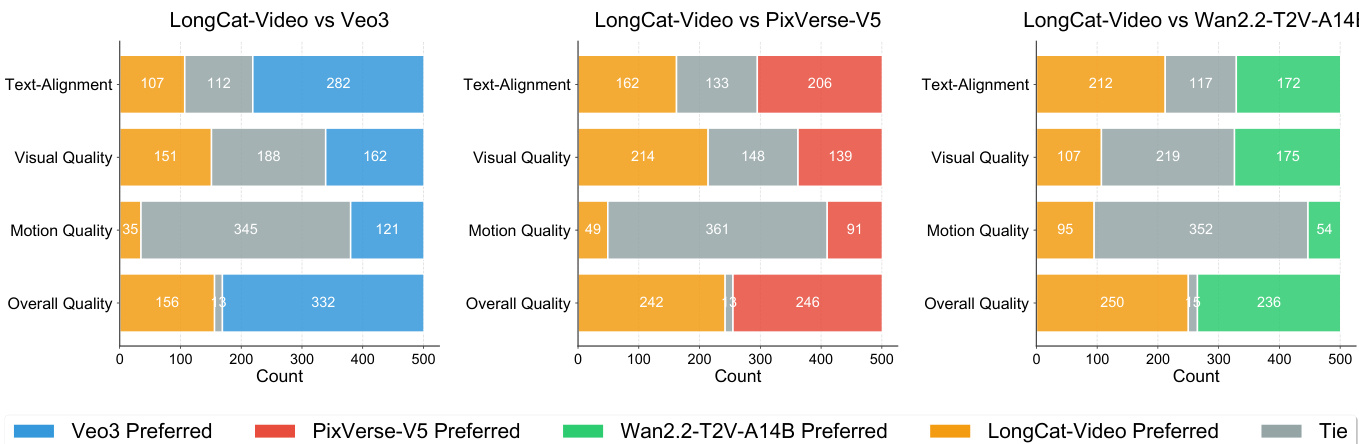
- 在内部文本到视频基准测试中,LongCat-Video整体质量达到顶级水平,超越Wan 2.2-T2V-A14B和PixVerse-V5,视觉质量接近Wan 2.2,文本对齐表现具有竞争力,在用户偏好(GSB)和MOS评估中优于开源模型。
- 在内部图像到视频基准测试中,LongCat-Video取得最高视觉质量得分(3.27),但在图像对齐与运动质量方面落后于Hailuo-2和Wan2.2-I2V-A14B,表明在时间一致性与参考图像保真度方面仍有提升空间。
- 在公开VBench 2.0基准测试中,LongCat-Video总体排名第二,尤其在常识维度领先,展现出卓越的运动合理性与物理规律遵循能力,是长视频与世界模型开发的关键优势。
- 粗到细生成与块稀疏注意力使单张H800 GPU上的推理时间减少超过10倍,可在数分钟内生成720p、30fps视频,同时提升视觉细节,如图10所示。
作者展示的模型配置包含48层,模型隐藏层大小为4096,FFN隐藏层大小为16384,32个注意力头,AdaLN嵌入大小为512。该配置支持LongCat-Video在高质量视频生成中的架构实现。

作者对比了全注意力与稀疏注意力训练阶段,发现两者使用相同的学习率、迭代次数和帧大小桶,但稀疏注意力实现了93.75%的稀疏度,同时保持相同阈值与训练时长。这表明稀疏注意力在不改变其他关键训练参数的前提下,显著降低计算复杂度。

作者采用Good-Same-Bad(GSB)评估方法,将LongCat-Video与Veo3、PixVerse-V5和Wan2.2-T2V-A14B进行对比,结果显示LongCat-Video在整体质量上优于Wan2.2-T2V-A14B,主要得益于更强的文本对齐与运动质量,与PixVerse-V5几乎持平。与Veo3相比,LongCat-Video被偏好频率较低,尤其在文本对齐与整体质量方面,Veo3表现更优。
作者采用多阶段训练方法,通过调整任务组合、大小桶、学习率与迭代次数来优化LongCat-Video。训练配置显示从简单任务(大批次、高学习率)逐步过渡到复杂多任务设置(小学习率、减少迭代次数),表明其策略旨在平衡效率与模型性能。

作者使用全面的内部基准测试,将LongCat-Video与多个领先模型在图像到视频生成方面进行对比。结果显示,LongCat-Video在视觉质量上得分最高,但在图像对齐与运动质量方面低于其他模型,表明其具有强视觉保真度,但在对齐与运动一致性方面仍有改进空间。
