Command Palette
Search for a command to run...
ATLAS:多语言预训练、微调与解码多语言困境的自适应迁移缩放定律
ATLAS:多语言预训练、微调与解码多语言困境的自适应迁移缩放定律
Shayne Longpre Sneha Kudugunta Niklas Muennighoff I-Hung Hsu Isaac Caswell Alex Pentland Sercan Arik Chen-Yu Lee Sayna Ebrahimi
摘要
现有规模定律研究几乎完全聚焦于英语,然而当前最主流的AI模型却明确服务于数十亿国际用户。在本项工作中,我们开展了迄今规模最大的多语言规模定律研究,共包含774项多语言训练实验,涵盖1000万至80亿参数的模型规模、400多种训练语言以及48种评估语言。我们提出了适用于单语和多语言预训练的自适应迁移规模定律(Adaptive Transfer Scaling Law, ATLAS),其在样本外泛化能力上显著优于现有规模定律,性能提升通常超过0.3 R²。通过对实验结果的深入分析,我们揭示了多语言学习的动态机制、语言间的迁移特性,以及多语言带来的“多语言诅咒”问题。首先,我们构建了一个跨语言迁移矩阵,实证测算了38×38=1444个语言对之间的相互收益得分。其次,我们推导出一种语言无关的规模定律,阐明了在新增语言时如何最优地调整模型规模与数据量,同时保持性能不下降。第三,我们识别出在何种条件下应从头开始预训练,而非基于多语言检查点进行微调的计算拐点。我们希望这些发现能为多语言场景下规模定律的科学化与普及化奠定基础,助力实践者高效扩展模型能力,推动人工智能发展超越“以英语为中心”的范式。
一句话总结
来自麻省理工学院、斯坦福大学、Google Cloud AI 和 Google DeepMind 的研究人员提出了 ATLAS——一种新型多语言模型扩展定律,其性能优于先前方法 0.3+ R²,能够在应对“多语言诅咒”的同时实现高效的跨语言扩展与迁移,推动全球人工智能的民主化。
主要贡献
- 我们提出了 ATLAS,一种适用于单语和多语预训练的新型自适应迁移扩展定律,在涵盖 400 多种语言、模型规模从 10M 到 8B 参数的 774 项实验中,其样本外泛化能力显著优于先前的扩展定律,通常提升超过 0.3 R²。
- 我们构建了首个大规模 38×38 跨语言迁移矩阵,实证量化了 1444 对语言组合之间的相互促进与干扰效应,为理解多语言学习动态与迁移效率提供了基础资源。
- 我们推导出应对“多语言诅咒”的实用扩展指南,并识别了从零预训练与从多语言检查点微调之间的计算交叉点,使扩展语言覆盖范围时能做出高效的扩展决策。
引言
作者利用大规模多语言实验,解决当前扩展定律主要局限于英语的问题——这至关重要,因为大多数现实世界的 AI 模型服务于全球用户,但其优化框架仍以英语为中心。先前工作或聚焦于小规模模型、有限语言对,或忽略了因容量限制导致增加语言会降低性能的现象——即“多语言诅咒”。其主要贡献是 ATLAS,一种自适应迁移扩展定律,可使样本外泛化能力提升超过 0.3 R²,同时提供 38×38 跨语言迁移矩阵、管理多语言容量权衡的扩展定律,以及一个实用公式,用于判断从零预训练优于从多语言检查点微调的时机。
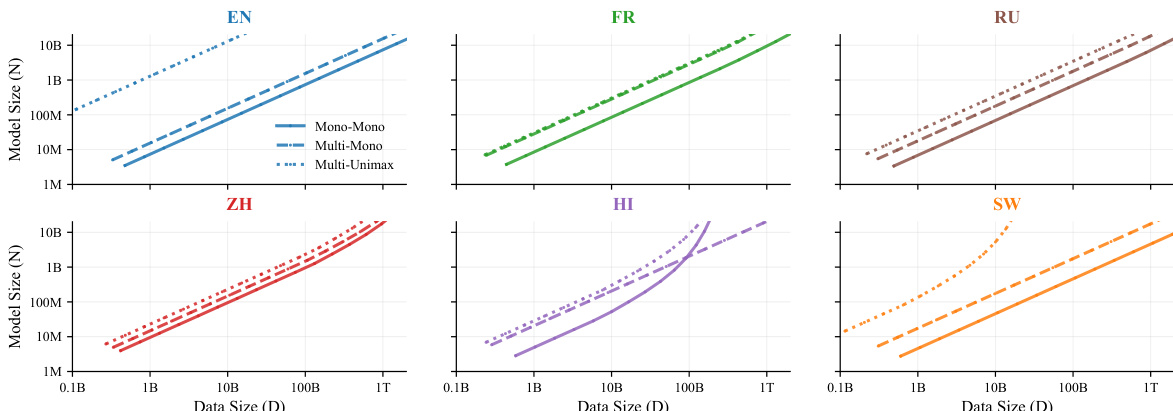
数据集

作者使用 MADLAD-400 数据集——一个源自 CommonCrawl、覆盖 400 多种语言的语料库——作为主要预训练来源,经过精心筛选的多语言过滤和预处理。在评估时,他们从 MADLAD-400 与 Flores-200 重叠的 50 种语言中选取,覆盖多样化的语系、文字系统和资源水平,采用分层抽样方法并手动调整以避免类型学冗余。
关键子集细节:
- MADLAD-400 测试集:对每种语言采样 20M 个 token 或总 token 数的 20%(取较小值),每种语言总计约 20.5M token,以确保使用 Tao 等人(2024)提出的词汇无关指标进行稳定的损失测量。
- Flores-101:作为次要测试集;从平行语料库中提取单语序列,以计算可比较的序列级损失。
训练设置:
- 模型规模从 10M 到 8B 参数,使用 64K SentencePiece 词汇表。
- 训练了 280 个单语、240 个双语和 120 个多语模型(包括 Unimax 风格混合),以及 130 个微调模型——总计超过 750 次运行。
- 实验变量包括模型规模 (N)、训练 token 数 (D) 和语言混合 (M),核心关注英语、法语、中文、印地语、斯瓦希里语、俄语、西班牙语、葡萄牙语和日语。
- 训练超参数遵循 Kudugunta 等人(2024)的工作,并根据最新研究进行优化。
评估策略:
- 通过保留测试集上的 R² 评估扩展定律,分别针对四个维度:最大模型规模 (N)、最大 token 数 (D)、最高计算量 (C) 和未见过的语言混合 (M)。
- R² 在语言间平均计算:单语设置为 [EN, FR, RU, ZH, HI, SW],多语设置额外加入 [ES, DE]。
- 词汇无关损失确保所有测试集上的跨语言比较公平。
方法
作者提出了自适应迁移扩展定律(ATLAS),一个统一框架,旨在建模单语和多语环境下的扩展行为,同时考虑数据重复与跨语言迁移效应。ATLAS 基于标准扩展定律形式,将损失表示为模型规模 N 和有效数据曝光量 Deff 的函数,如下所示:
L(N,Deff)=E+NαA+DeffβB核心创新在于 Deff 的定义,它将总数据曝光量分解为三个独立部分:目标语言的单语项、捕捉跨语言影响的迁移语言项,以及所有其他语言的剩余项。该分解形式化为:
Deff=MonolingualSλ(Dt;Ut)+Transfer Languagesi∈K∑τiSλ(Di;Ui)+Other LanguagesτotherSλ(Dother;Uother)每个部分使用饱和函数 Sλ(D;U) 来建模数据重复超过一个 epoch 后的边际收益递减。该函数定义为:
Sλ(D;U)={D,U[1+λ1−exp(−λ(D/U−1))],D≤U(≤1 epoch)D>U(>1 epoch)参数 λ 控制饱和速率,并在所有数据源间共享,确保重复对有效数据曝光的影响具有一致性。迁移权重 τi 和 τother 是可学习参数,用于量化每组语言对目标语言性能的相对贡献。这些权重使用先前分析得出的语言迁移分数初始化,使 ATLAS 能自适应地建模跨语言迁移动态。
该框架旨在适应不同的数据收集约束和训练机制。通过明确分离单语和迁移贡献,ATLAS 避免了先前方法忽略数据重复或无法区分不同类型跨语言效应的局限。这种模块化设计使模型能有效泛化到样本外维度,包括更大的模型规模、扩展的数据范围和未见过的语言组合。共享的单一重复参数 λ 与灵活的迁移权重结构确保 ATLAS 在捕捉多语环境中的复杂扩展行为时仍保持计算高效。
实验
- 使用双语迁移分数(BTS)构建了 30×30(及 38×38)跨语言迁移矩阵,发现英语是 19/30 个目标语言的最佳源语言,其次是法语(16/30)、西班牙语(13/30)和希伯来语(11/30);乌尔都语和普什图语等低资源语言表现出持续的负迁移。
- 发现正迁移与共享文字系统(平均 BTS:-0.23)或语系(p < 0.001)高度相关,其中文字系统的影响大于语系;迁移仅在共享文字系统/语系的语言对内对称(如法语-西班牙语),否则不对称(如中文-波斯语)。
- 量化“多语言诅咒”:增加语言数量 (K) 会提高目标损失,但通过扩大模型规模 (N) 比增加数据 (D) 更能缓解;拟合扩展定律 L(K,N,D) = L∞ + A·K^φ/N^α + B·K^ψ/D^β,其中 φ=0.11,ψ=-0.04(R²≥0.87),证实轻微容量惩罚可被正迁移部分抵消。
- 推导计算最优扩展:若从 K 扩展至 r·K 种语言而不损失性能,需将模型规模扩大 r^(φ/α) ≈ r^0.11/α,总 token 数扩大 r^(1+ψ/β) ≈ r^(1-0.04/β);例如,4 倍语言数需 1.4 倍 N 和 2.74 倍 D_tot,通过迁移可使每种语言所需数据减少 32%。
- 预训练 vs 微调:在 144B–283B token 以内,从 Unimax 检查点微调优于从零预训练;超出后,从零预训练更优;计算阈值建模为 log(C) = 1.1M × N^1.65,使实践者可根据预算和模型规模做出选择。
- 验证 BTS 可扩展性:迁移分数随模型增大而提升,并在训练早期稳定;更大模型可缓解负迁移(如 en→zh),将干扰转为中性,而协同语言对(如 es→pt)则显示适度增益。
作者使用双语迁移分数衡量源语言训练对目标语言性能的影响,正分数表示有益迁移,负分数表示干扰。结果表明,语言相似性(特别是共享语系和文字系统)强烈预测迁移有效性,英语对许多目标语言最有益,而低资源语言常表现出负迁移。
作者通过一系列全面实验测量跨语言迁移及多语言训练对模型性能的影响。结果表明,语言相似性(尤其是共享语系和文字系统)强烈预测正迁移,英语对许多目标语言最有益。此外,更大模型可缓解负干扰并提升迁移效率,而“多语言诅咒”可部分被正向跨语言迁移抵消。
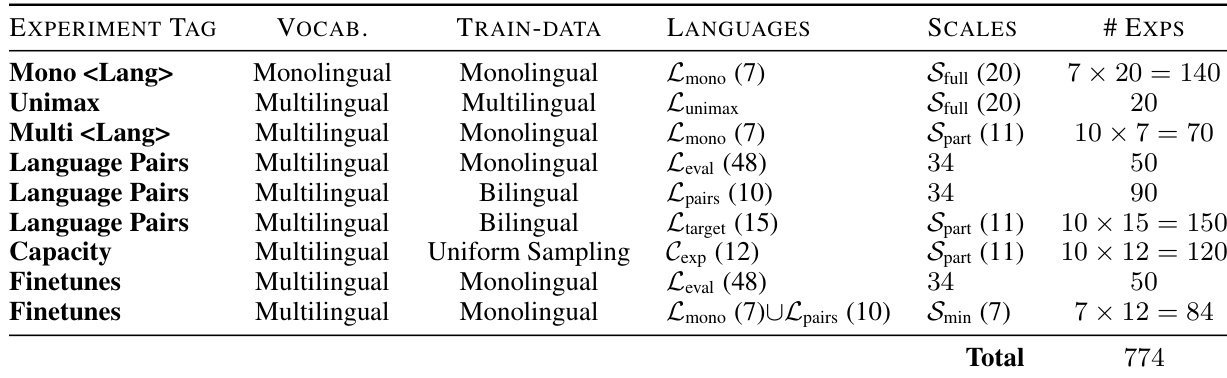
作者使用双语迁移分数衡量源语言训练对目标语言性能的影响,发现语言相似性——特别是共享语系和文字系统——强烈预测正迁移。结果表明,同时共享语系和文字系统的语言对表现出最强的对称和正向迁移,而语系和文字系统均不同的语言对则表现出更大不对称性和负迁移,其中文字系统相似性的影响强于语系。
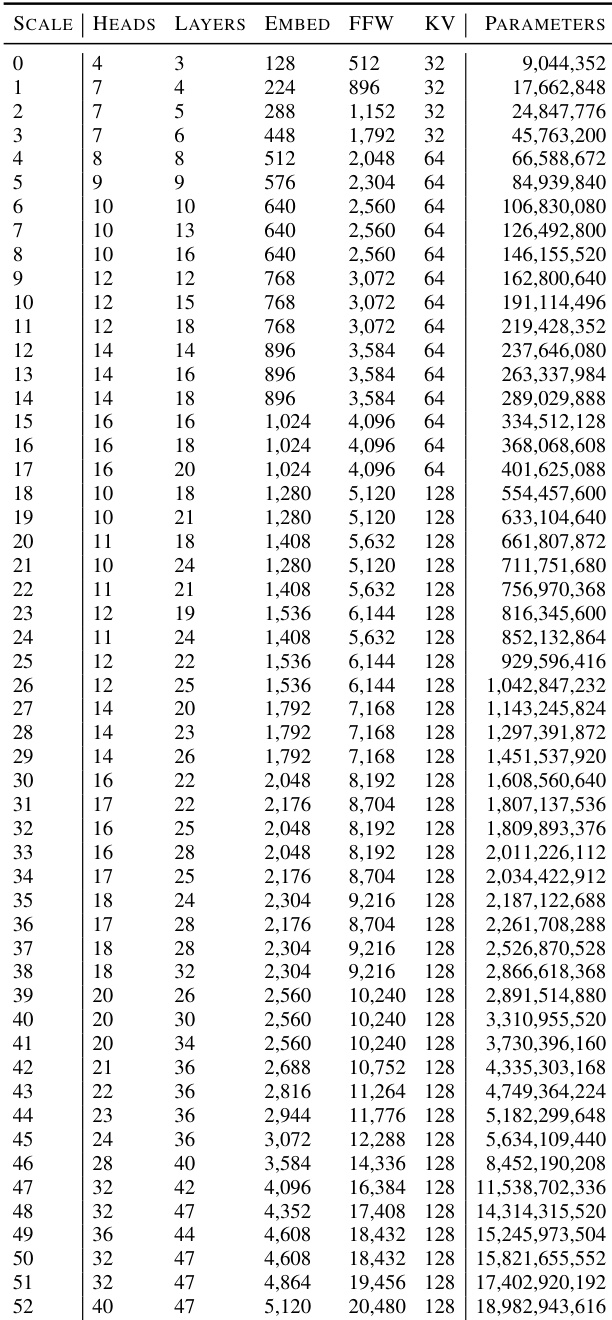
作者使用从 10M 到 8B 参数的多种模型规模,搭配不同注意力头数、层数、嵌入大小和前馈宽度,研究多语言学习动态。下表提供每种规模的具体架构配置,用于实验中测量语言迁移和模型容量效应。
作者比较了单语和多语模型的扩展定律,发现他们提出的多语扩展定律在不同评估指标上表现优异。[Ours] ATLAS (Dt + Dother + ∑κt Di) 模型优于现有基线,尤其在多语设置中,高 R² 值表明其拟合稳健且泛化能力强。
