Command Palette
Search for a command to run...
DeepSeek-OCR:上下文光学压缩
DeepSeek-OCR:上下文光学压缩
Haoran Wei Yaofeng Sun Yukun Li
摘要
我们提出 DeepSeek-OCR,作为通过二维光学映射实现长上下文压缩的初步探索。DeepSeek-OCR 由两部分组成:DeepEncoder 作为编码器,以及 DeepSeek3B-MoE-A570M 作为解码器。其中,DeepEncoder 作为核心引擎,旨在在高分辨率输入下保持低激活状态,同时实现高压缩比,从而确保视觉 token 数量处于最优且可管理的范围。实验结果表明,当文本 token 数量不超过视觉 token 数量的 10 倍(即压缩比小于 10 倍)时,模型可实现高达 97% 的解码(OCR)精度;即使在 20 倍压缩比下,OCR 准确率仍维持在约 60%。这一表现展示了其在历史长上下文压缩、大语言模型(LLM)中记忆遗忘机制等研究方向上的巨大潜力。此外,DeepSeek-OCR 还展现出显著的实用价值。在 OmniDocBench 基准测试中,其仅使用 100 个视觉 token 即超越了 GOT-OCR2.0(256 个 token/页)的性能,同时在仅使用少于 800 个视觉 token 的情况下,优于 MinerU2.0(平均每页超过 6000 个 token)。在实际生产环境中,DeepSeek-OCR 可实现每日生成超过 20 万页的 LLM/VLM 训练数据(单张 A100-40G GPU)。代码与模型权重已公开,可访问 http://github.com/deepseek-ai/DeepSeek-OCR。
一句话总结
作者提出 DeepSeek-OCR,一种新颖的端到端 OCR 系统,利用 DeepEncoder 实现高效的二维光学映射以压缩长文档,在 OmniDocBench 上仅使用 100 个视觉标记即达到最先进性能,超越 GOT-OCR2.0 和 MinerU2.0,同时在单张 A100-40G 显卡上实现每日超过 20 万页的可扩展训练数据生成。
主要贡献
-
本工作研究了光学二维映射作为一种将长文本上下文压缩为紧凑视觉表示的方法,证明 DeepSeek-OCR 在压缩比低于 10× 时可实现 97% 的 OCR 精度,并在 20× 压缩比下仍保持约 60% 的准确率,验证了基于视觉的文本压缩在长上下文大语言模型中的可行性。
-
DeepEncoder 作为核心组件,采用一种新颖架构,结合窗口注意力、全局注意力和 16× 卷积标记压缩器,在高分辨率输入下仍能保持低激活内存并最小化视觉标记数量,从而实现对密集文档布局的高效处理。
-
在 OmniDocBench 上,DeepSeek-OCR 超越了 GOT-OCR2.0 和 MinerU2.0 等最先进端到端模型,同时使用的视觉标记显著更少(低于 800 个),并在单张 A100-40G GPU 上实现每日生成超过 20 万页训练数据,展现出在大规模预训练中的强大实用价值。
引言
作者利用视觉语言模型(VLMs)探索文本内容的光学压缩,以应对大语言模型(LLMs)在长上下文处理中面临的二次计算成本问题。通过将视觉表示视为文本的压缩媒介,他们提出 DeepSeek-OCR 作为概念验证系统,实现了 9–12× 的文本压缩比,且 OCR 准确率超过 90%,证明视觉标记可高效编码密集文本信息。先前的端到端 OCR 模型虽有效,但缺乏对最小视觉标记需求的系统性分析,且在高分辨率输入下因标准视觉编码器的内存与标记爆炸问题而表现不佳。作者引入 DeepEncoder,一种结合窗口注意力、全局注意力和 16× 卷积压缩器的新型架构,以维持低激活内存并大幅减少视觉标记,从而实现对高分辨率文档的高效处理。基于 DeepSeek-3B-MoE,DeepSeek-OCR 在 OmniDocBench 上以极少量视觉标记达到最先进性能,并支持图表与公式解析等实用任务,利用 20 个节点实现每日 3300 万页的大规模数据生成。本工作为视觉-文本压缩建立基础,证明其作为提升 LLM 效率的可行策略,对长上下文建模与多模态预训练具有深远影响。
数据集
-
DeepSeek-OCR 的数据集由三大核心部分构成:OCR 1.0 数据(文档与场景 OCR)、OCR 2.0 数据(图表、化学公式与平面几何解析)、通用视觉数据以及纯文本数据,总训练混合比例为 70% OCR 数据、20% 通用视觉数据、10% 纯文本数据。
-
OCR 1.0 数据包含 3000 万页多语言 PDF(其中 2500 万页为中英文,500 万页为其他语言),使用 fitz 进行粗粒度标注以实现通用文本识别,同时对 200 万页中英文数据采用先进布局(PP-DocLayout)与 OCR 模型(MinerU、GOT-OCR2.0)进行精细标注。对于少数语言,采用模型飞轮方法结合 fitz 基于的补丁标注与训练后的 GOT-OCR2.0,生成 60 万样本。此外,使用 300 万高质量 Word 文档支持公式与表格理解,且不包含布局结构。
-
自然场景 OCR 数据包含来自 LAION 和 Wukong 的 1000 万张中英文图像,使用 PaddleOCR 进行标注。这些样本支持检测与识别双重输出,可通过提示词进行控制。
-
OCR 2.0 数据包括使用 pyecharts 和 matplotlib 渲染的 1000 万张图表图像,标签以 HTML 表格格式存储以减少标记使用;500 万张化学公式图像由 PubChem SMILES 通过 RDKit 生成;100 万张平面几何图像使用 Slow Perception 生成,并采用几何平移不变增强以提升多样性。
-
通用视觉数据(占总量 20%)源自 DeepSeek-VL2,涵盖图像描述、目标检测与定位任务,旨在保留通用视觉能力,同时避免使 DeepSeek-OCR 成为通用 VLM。
-
纯文本数据(占总量 10%)为内部预训练数据,全部被标记化为 8192 个标记,以匹配模型序列长度,确保强大的语言建模能力。
-
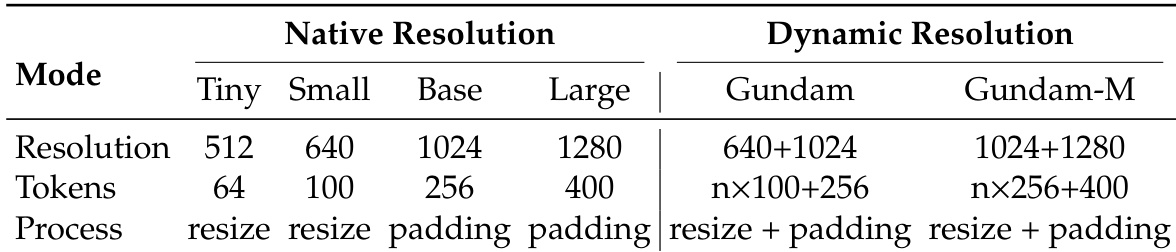
模型训练采用多种分辨率模式:四种原生分辨率(Tiny: 512×512,Small: 640×640,Base: 1024×1024,Large: 1280×1280),并使用动态插值位置编码。在 Base 与 Large 模式下,图像按原始宽高比进行填充,有效视觉标记数基于原始图像尺寸计算。Tiny 与 Small 模式采用直接缩放。
-
动态分辨率模式(如 Gundam 模式)结合局部 640×640 像素块(n 块)与 1024×1024 全局视图,生成 n×100 + 256 个视觉标记。当输入尺寸低于 640×640 时,该模式默认切换至 Base 模式。Gundam 模式与原生模式共同训练,Gundam-master(1024×1024 局部 + 1280×1280 全局)通过持续训练引入以实现负载均衡。
-
所有数据均使用归一化坐标(1000 个 bin),精细标注格式为交错的布局与文本序列。复杂布局与解析任务的真值结构化设计,以支持高效解码与模型训练。
方法
作者采用统一的端到端视觉语言模型(VLM)架构进行光学字符识别(OCR),由专用视觉编码器与解码器组成。如图所示,该框架包含两个主要组件:DeepEncoder,用于处理输入图像;以及 DeepSeek-3B-MoE 解码器,基于压缩后的视觉表示与提供的提示生成文本输出。该架构旨在实现高压缩比的同时保持低激活内存,尤其适用于高分辨率输入。

DeepEncoder 作为核心视觉编码器,是一种专为解决现有视觉编码器局限性而设计的新颖架构。其由两个主要模块构成:视觉感知特征提取模块与视觉知识特征提取模块。第一模块以窗口注意力为主,基于 8000 万参数的 SAM-base 模型,补丁大小为 16。第二模块负责密集全局注意力,基于 3 亿参数的 CLIP-large 模型。这两个模块串联连接。为减少视觉标记数量并控制激活内存,在两者之间引入一个两层卷积模块,对视觉标记执行 16× 下采样。该压缩步骤对管理计算负载至关重要,将标记数从 4096(1024×1024 图像)降至 256,从而实现低激活内存。
解码器为一个 30 亿参数的专家混合(MoE)模型,即 DeepSeek-3B-MoE,在推理过程中激活约 5.7 亿参数。该架构使模型在保持小型模型推理效率的同时,具备 30 亿模型的表达能力。解码器的功能是从 DeepEncoder 生成的压缩潜在视觉标记中重建原始文本表示。这被形式化为非线性映射 fdec:Rn×dlatent→RN×dtext,其中 Z∈Rn×dlatent 表示压缩后的视觉标记,X^∈RN×dtext 为重建的文本输出。
DeepSeek-OCR 的训练过程分为两个阶段。第一阶段,DeepEncoder 独立训练,采用下一标记预测框架。该阶段使用多样化数据集,包括 OCR 1.0 与 2.0 数据,以及从 LAION 数据集中采样的 1 亿张通用图像。训练进行 2 个周期,批量大小为 1280,使用 AdamW 优化器与余弦退火调度器,学习率为 5e-5,训练序列长度设为 4096。第二阶段,整个 DeepSeek-OCR 模型(包括预训练的 DeepEncoder 与解码器)联合训练。该两阶段方法使模型能够高效且有效地训练。
实验
- 在 HAI-LLM 上使用 20 个节点(每节点 8 张 A100-40G GPU)的流水线并行训练 DeepSeek-OCR,实现纯文本每日 900 亿标记、多模态数据每日 700 亿标记的训练速度,使用 AdamW 优化器,初始学习率为 3e-5。
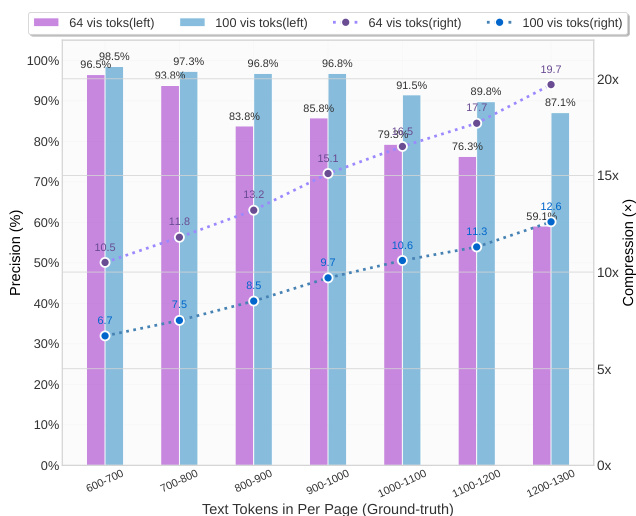
- 在 Fox 基准测试中,DeepSeek-OCR 在 10× 视觉-文本压缩比下实现约 97% 的解码精度,超过 10× 后性能下降,主要因布局复杂性与固定分辨率下的文本模糊;在 20× 压缩比下,精度仍维持在约 60%,表明其在无损与近无损光学上下文压缩方面具有巨大潜力。
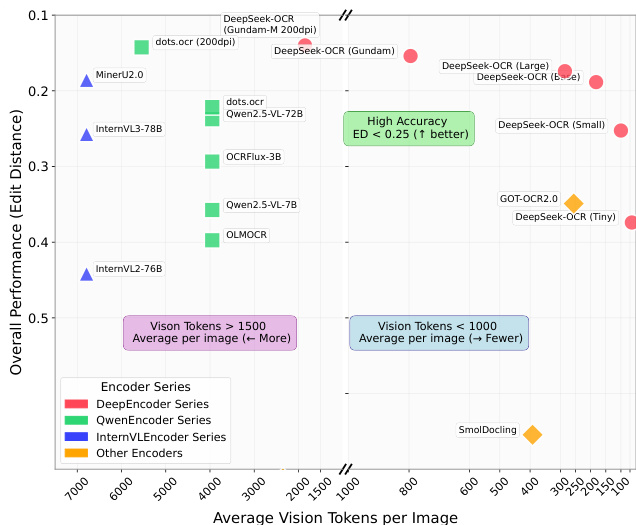
- 在 OmniDocBench 上,DeepSeek-OCR 仅使用 100 个视觉标记(640×640)即超越 GOT-OCR2.0,并在使用 400 个标记(1280×1280)时达到最先进性能,显著优于需约 7000 个标记的 MinerU2.0,展现出极高的实际效率。
- 在文档类别方面,幻灯片仅需 64 个视觉标记,书籍与报告在 100 个标记下表现良好,而报纸因文本密度高(4000–5000 标记)需使用 Gundam 或 Gundam-master 模式,凸显压缩边界与文档复杂度密切相关。
- DeepSeek-OCR 在无需 SFT 的情况下保留通用视觉理解能力(图像描述、目标检测、定位)与语言能力,支持上下文感知处理,为未来可扩展的长上下文建模应用奠定基础。
- 视觉-文本压缩方法通过逐步缩小渲染的历史文本图像,模拟人类记忆遗忘机制,实现多层级压缩,减少标记数量并模糊旧内容,为高效、可扩展的长上下文架构提供一种生物启发路径。
作者使用 DeepSeek-OCR 研究视觉-文本压缩,测试其从压缩视觉表示中解码文本的能力。结果表明,模型在 10× 压缩比下实现约 97% 的解码精度,超过该比值后性能下降,但在接近 20× 压缩比时仍保持约 60% 的准确率。

结果表明,DeepSeek-OCR 在不同文档类型上表现出不同程度的性能,小型模式(如 Tiny 与 Small)在幻灯片与书籍等文档上表现良好,而复杂文档(如报纸)则需更高模式(如 Gundam 或 Gundam-M)才能达到可接受的编辑距离。该模型展现出强大的实际 OCR 能力,以显著更少的视觉标记超越最先进方法,表明其在视觉-文本压缩方面的高效性。
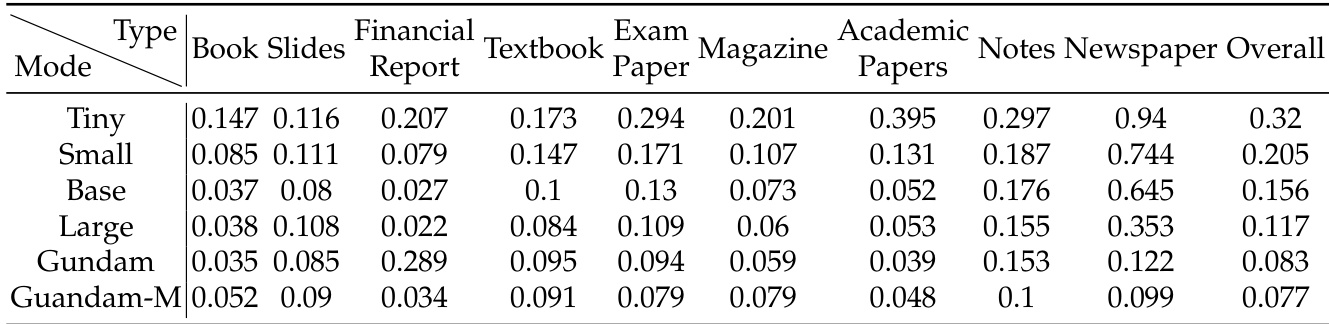
结果表明,与其它模型相比,DeepSeek-OCR 在较少视觉标记下实现高精度,尤其在 Tiny 与 Small 模式下,其性能优于 GOT-OCR2.0 与 MinerU2.0,且使用标记数显著更少。模型在不同文档类型上均表现优异,部分类别如幻灯片仅需 64 个视觉标记,而复杂文档如报纸则需更高标记数,表明压缩比与准确率之间存在权衡。
作者使用 DeepSeek-OCR 在 Fox 基准的英文文档上测试视觉-文本压缩比,评估不同分辨率与标记数定义的模式下的性能。结果表明,使用 64 或 100 个视觉标记时,模型实现高解码精度,在 10× 压缩比下达到约 97%,但超过该比值后性能下降,主要因布局复杂性增加与低分辨率下的文本模糊。
结果表明,DeepSeek-OCR 在视觉-文本压缩中实现高精度,对于包含 600–700 个文本标记的文本密集型文档,使用 64 或 100 个视觉标记时解码准确率超过 96%。当每页文本标记数超过 1000 时,精度下降,尤其在高压缩比下,表明在低视觉标记数下难以保留细粒度文本细节。