Command Palette
Search for a command to run...
PaddleOCR-VL:通过一款0.9B超紧凑视觉-语言模型提升多语言文档解析能力
PaddleOCR-VL:通过一款0.9B超紧凑视觉-语言模型提升多语言文档解析能力
摘要
在本报告中,我们提出PaddleOCR-VL——一种面向文档解析的当前最先进(SOTA)且资源高效的模型。其核心组件为PaddleOCR-VL-0.9B,一个轻量级但功能强大的视觉语言模型(VLM),该模型融合了基于NaViT架构的动态分辨率视觉编码器与ERNIE-4.5-0.3B语言模型,从而实现高精度的文档元素识别。该创新模型支持多达109种语言,能够高效识别复杂文档元素(如文本、表格、公式和图表),同时保持极低的资源消耗。通过在广泛使用的公开基准和内部基准上的全面评估,PaddleOCR-VL在页面级文档解析与元素级识别任务中均达到当前最优性能。其表现显著优于现有解决方案,在与顶级视觉语言模型的对比中展现出强劲竞争力,并具备快速推理能力。这些优势使其在真实应用场景中具备极高的实用价值与部署潜力。代码已开源,地址为:https://github.com/PaddlePaddle/PaddleOCR。
一句话总结
百度团队提出 PaddleOCR-VL,一种资源高效的视觉-语言模型,融合了 NaViT 风格的动态分辨率编码器与 ERNIE-4.5-0.3B 模型,实现了多语言文档解析的最先进性能,能够准确识别表格、公式等复杂元素,在保持快速推理能力的同时,优于现有方案,适用于真实场景的部署。
主要贡献
-
PaddleOCR-VL 提出了一种紧凑而强大的视觉-语言模型 PaddleOCR-VL-0.9B,结合了 NaViT 风格的动态分辨率视觉编码器与轻量级 ERNIE-4.5-0.3B 语言模型,实现了对文本、表格、公式和图表等复杂文档元素的高效且精准识别,支持 109 种语言,同时保持低资源消耗。
-
该框架采用系统化的数据构建流程,通过提示工程实现自动化标注,数据清洗以消除幻觉,并基于评估引擎进行针对性的困难样本挖掘,从而在大规模上构建高质量训练数据,支持鲁棒的多模态文档解析。
-
PaddleOCR-VL 在 OmniDocBench v1.0 和 v1.5 等公开基准以及内部评估中均达到最先进性能,显著优于现有基于流水线和端到端的方法,在页面级与元素级识别任务中均表现突出,同时在多种硬件配置下实现更快的推理速度和更高的吞吐量。
引言
文档解析对于从日益复杂且多语言的文档中提取结构化、语义明确的信息至关重要,广泛应用于知识管理、智能归档,并通过检索增强生成(RAG)支持大语言模型。以往方法存在关键局限:流水线方法易受误差传播和集成复杂性影响,而端到端视觉-语言模型通常计算成本高,阅读顺序准确性差,且在长篇或复杂布局上容易产生幻觉。为应对这些挑战,作者提出 PaddleOCR-VL,一种 0.9B 参数的超紧凑视觉-语言模型,专为高性能、资源高效的文档解析设计。该模型结合动态高分辨率视觉编码器与轻量级语言主干,实现文本、表格、公式和图表的快速推理与强识别能力。其采用新颖的数据构建流程——通过提示工程实现自动化标注、数据清洗以及针对性困难样本挖掘,构建了超过 3000 万样本的高质量数据集。该方法支持稳健训练,并在多个基准上实现最先进性能,同时在多种硬件上保持高效。系统在 109 种语言(包括复杂文字)的多语言文档解析中达到最先进水平,且针对生产环境中的真实部署进行了优化。
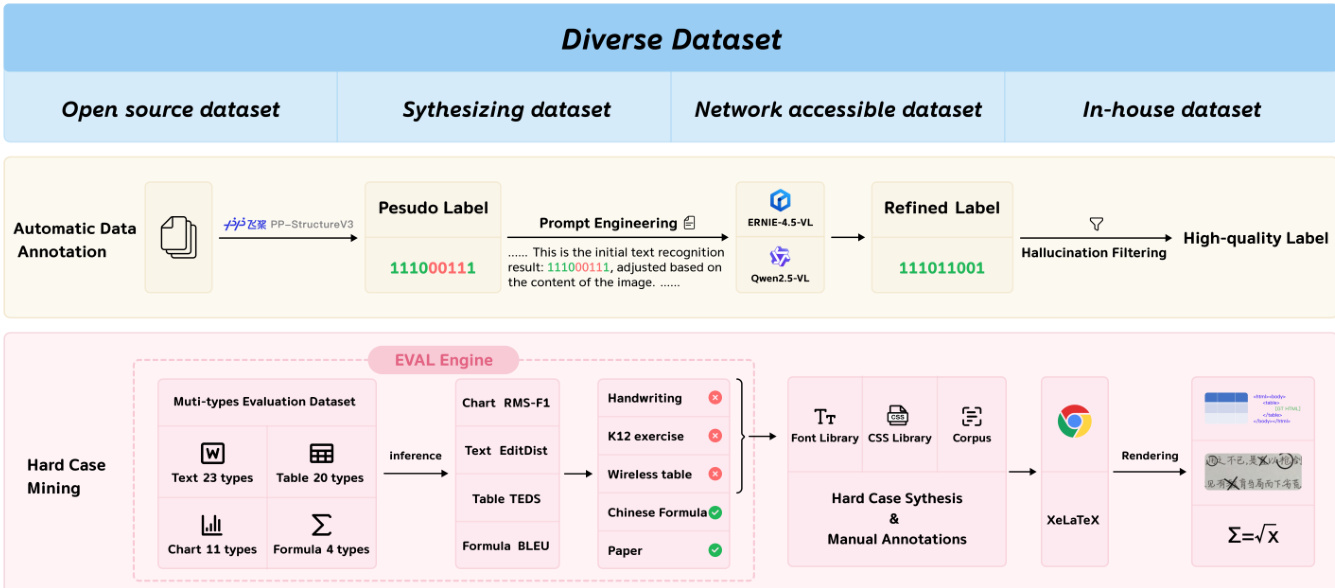
数据集
- 数据集源自四个主要来源:开源数据集、合成数据、公开可访问的网络数据以及内部收集,确保覆盖广泛的文档类型、语言和视觉风格。
- 文本数据包含 2000 万条高质量图像-文本对,来自 CASIA-HWDB、UniMER-1M、MathWriting 等来源,支持 109 种语言,涵盖学术论文、报纸、身份证、票据和古籍中的印刷体、手写体、扫描件和艺术字体。
- 表格数据包含超过 500 万张图像-表格对,通过 PP-StructureV3 和 ERNIE-4.5-VL 自动标注构建,从 arXiv HTML 源中挖掘潜在标注,并使用工具每小时生成 10,000 个样本,支持多样化表格类型与风格的可配置合成。
- 公式数据超过 100 万样本,涵盖中英文的简单与复杂印刷体、屏幕截图和手写公式。数据通过 arXiv 源码渲染、ERNIE-4.5-VL-28B-A3B 自动标注、基于 LaTeX 的过滤、长尾案例(如竖式计算、删除线)的针对性合成,以及整合 UniMER-1M 和 MathWriting 等公开数据集构建。
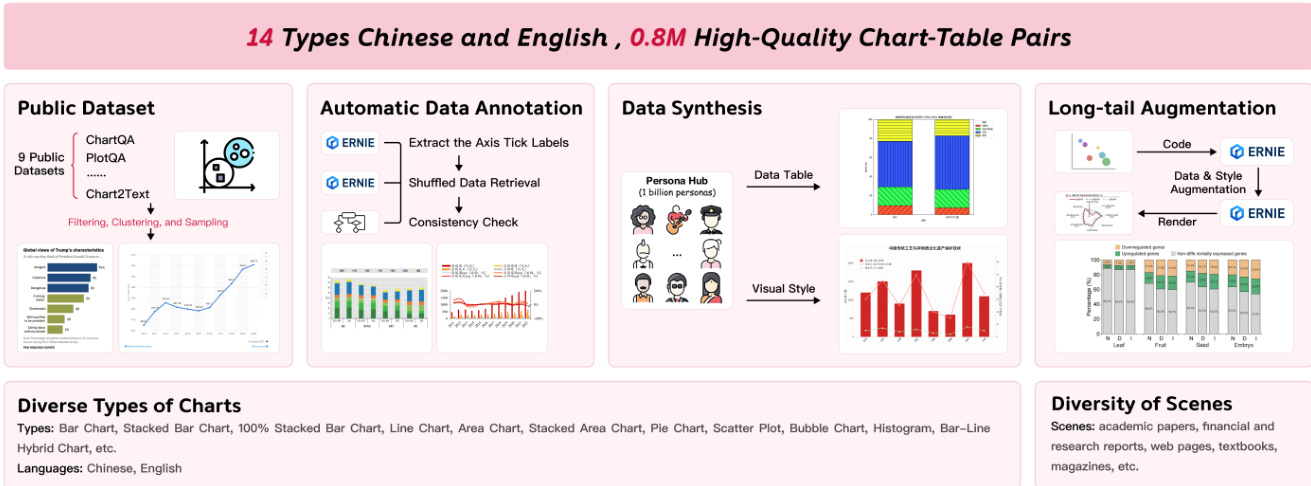
- 图表数据包含超过 80 万对中英文双语图像-图表对,来源于 ChartQA、PlotQA、Chart2Text 等公开数据集,经严格过滤流程清洗,采用两阶段基于大语言模型的方法标注,并通过三阶段合成流程(利用 LLM 人格与 matplotlib、seaborn 等渲染工具)生成多样视觉风格。
- 困难样本挖掘通过在 23 个文本、20 个表格、4 个公式和 11 个图表类别上使用人工标注的评估集识别模型弱点,随后利用字体库、CSS 和 XeLaTeX 等渲染工具合成挑战性样本。
- 所有数据均经过多阶段处理:使用 PP-StructureV3 和多模态大模型(ERNIE-4.5-VL、Qwen2.5VL)进行自动标注,过滤幻觉,并通过基于规则的验证(n-gram、HTML、渲染成功性)。
- 最终训练数据采用两阶段混合策略,文本、表格、公式和图表的比例均衡,使模型能够学习跨多样化布局与领域的全面文档解析能力。
- 元数据通过分层标注(文本行、块、页)、结构化输出格式(OTSL 用于表格)以及视觉内容与语义标注之间的一致对齐构建。
- 在公式与表格提取过程中应用裁剪,基于布局分析隔离感兴趣区域后再进行标注或合成。
方法
作者采用两阶段框架进行文档解析,如整体系统图所示。该架构将布局分析与细粒度内容识别解耦,实现对复杂文档的高效准确处理。第一阶段 PP-DocLayoutV2 执行布局分析,定位并分类语义区域,并预测其阅读顺序。第二阶段 PaddleOCR-VL-0.9B 利用这些布局预测结果,对文本、表格、公式和图表等多种内容类型进行详细识别。随后,一个轻量级后处理模块将两阶段输出聚合,生成结构化 Markdown 与 JSON 格式。
布局分析阶段采用专用轻量级模型 PP-DocLayoutV2,以避免端到端视觉-语言模型带来的高延迟与高内存消耗。该模型由两个顺序连接的网络组成。第一个是基于 RT-DETR 的目标检测模型,负责定位与分类布局元素。检测到的边界框与类别标签随后传递给后续的指针网络,用于预测元素的阅读顺序。该指针网络是一个轻量级 Transformer,包含六层,旨在建模检测元素之间的相对顺序。该布局分析模型的架构详见附图。
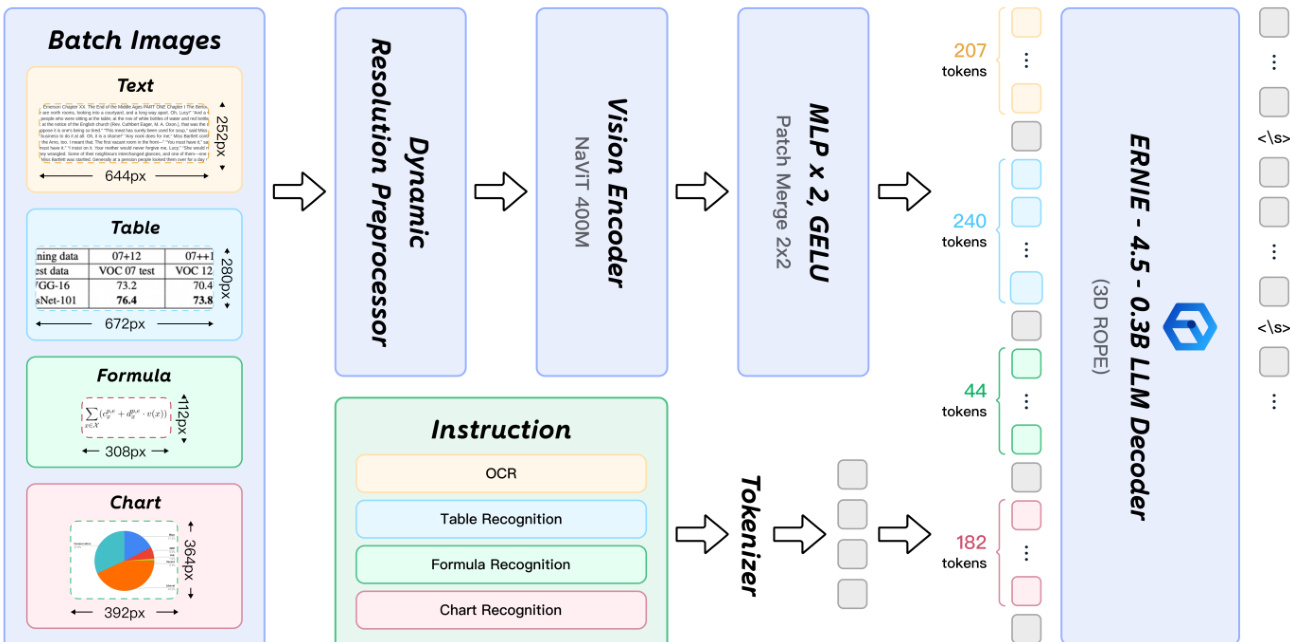
元素级识别阶段由 PaddleOCR-VL-0.9B 驱动,这是一种受 LLaVA 架构启发的视觉-语言模型。该模型整合了预训练视觉编码器、动态分辨率预处理器、随机初始化的两层 MLP 投影器以及预训练大语言模型。视觉编码器为基于 NaViT 风格的模型,从 Keye-VL 的视觉模型初始化,支持原生分辨率输入,使模型能够无失真地处理任意分辨率图像。投影器高效地将编码器的视觉特征映射到语言模型的嵌入空间。所用语言模型为 ERNIE-4.5-0.3B,一个参数紧凑的模型,因其出色的推理效率而被选中。该模型架构如以下图示所示。
两个模块的训练过程不同。对于 PP-DocLayoutV2,采用两阶段策略:首先在自建数据集上训练 RT-DETR 模型以完成布局检测与分类;随后冻结其参数,使用恒定学习率和 AdamW 优化器独立训练指针网络以预测阅读顺序。对于 PaddleOCR-VL-0.9B,采用后适应策略:视觉与语言模型均使用预训练权重初始化。训练分为两个阶段:第一阶段在 2900 万张图像-文本对上进行预训练对齐,建立视觉输入与其文本表示之间的一致理解;第二阶段在 270 万样本的精选数据集上进行指令微调,聚焦于四项具体任务:OCR、表格识别、公式识别与图表识别。该微调过程将模型的通用多模态理解能力适配至特定下游识别任务。
实验
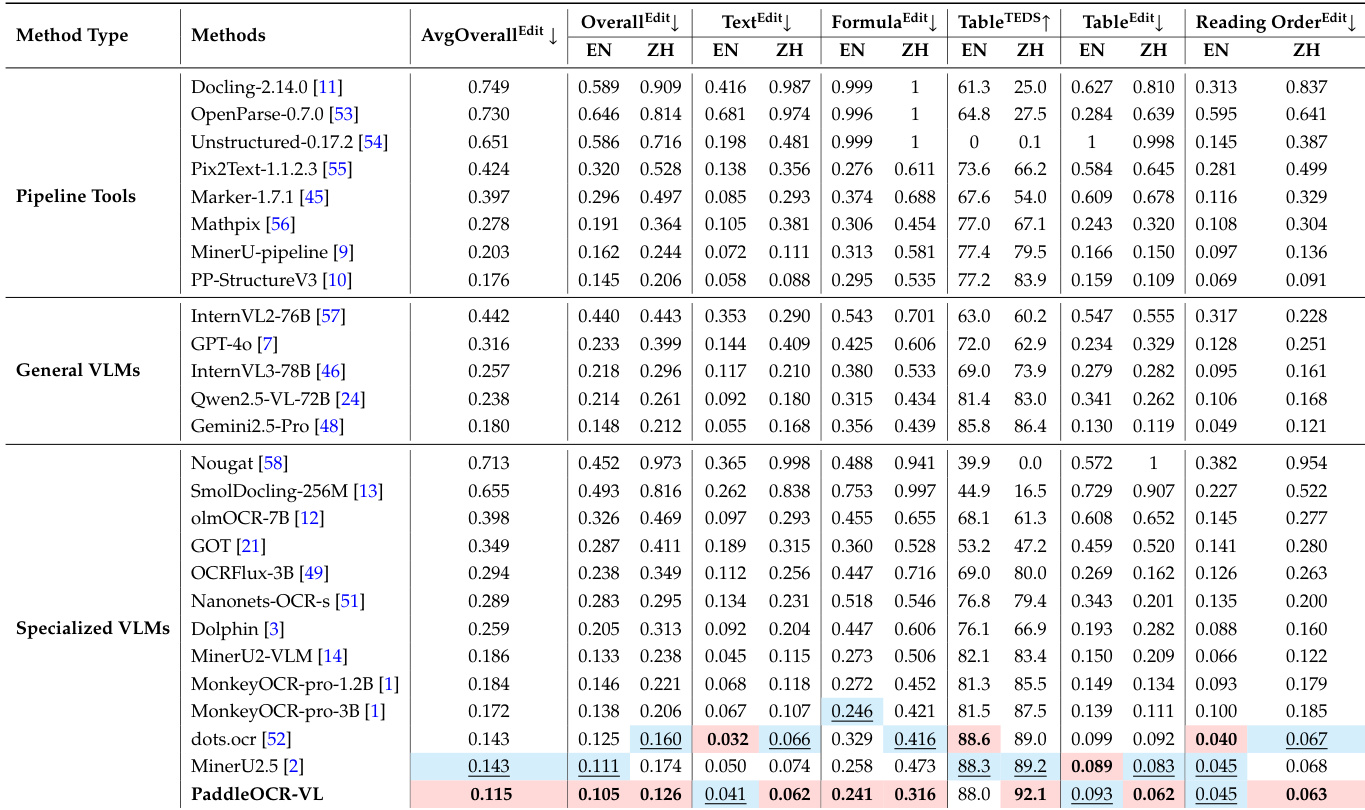
- 在 OmniDocBench v1.5、olmOCR-Bench 和 OmniDocBench v1.0 上评估页面级文档解析,于 OmniDocBench v1.5 上取得 92.86 的最先进总体得分,优于 MinerU2.5-1.2B(90.67),在文本(编辑距离 0.035)、公式(CDM 91.22)、表格(TEDS 90.89 与 TEDS-S 94.76)和阅读顺序(0.043)方面均领先。
- 在 OmniDocBench v1.0 上,平均总体编辑距离为 0.115,中文文本(0.062)与英文文本(0.041)表现最先进,中文表格(92.14)与阅读顺序(0.063)得分最高。
- 在 olmOCR-Bench 上,取得 80.0 ± 1.0 的最高总体得分,ArXiv(85.7)、页眉页脚(97.0)领先,多栏(79.9)与超小文本(85.7)排名第二。
- 元素级评估:在 OmniDocBench-OCR-block 上,各类文档类型编辑距离最低(如 PPT2PDF:0.049,学术文献:0.021);在 In-house-OCR 上,109 种语言与 14 种文本类型(包括手写与艺术字体)均达最先进水平;在 Ocean-OCR-Handwritten 上,英文(编辑距离 0.118)与中文(0.034)识别均领先。
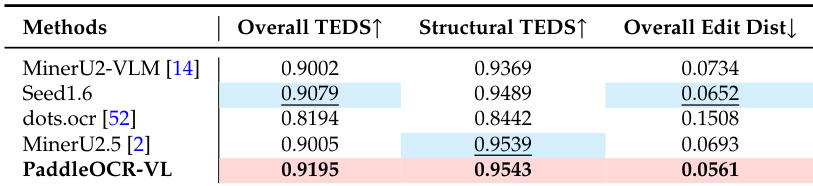
- 在 OmniDocBench-Table-block 上,取得最高 TEDS(0.9195)与最低编辑距离(0.0561);在 In-house-Table 上,总体 TEDS(0.8699)与结构 TEDS(0.9066)得分最高。
- 在 OmniDocBench-Formula-block 上,取得最先进 CDM 得分(0.9453);在 In-house-Formula 上,达到 0.9882 CDM,展现出复杂场景下卓越的公式识别能力。
- 在内部 Chart 基准上,优于专家级 OCR VLM 与 72B 级模型,RMS-F1 高,展示出在中英文共 11 种图表类型上的强大解析能力。
- 推理评估:在单张 A100 GPU 上使用 FastDeploy,页面吞吐量比 MinerU2.5 提高 53.1%,token 吞吐量提高 50.9%,展现出跨硬件配置的最先进效率与可扩展性。
结果表明,PaddleOCR-VL 在 OmniDocBench-Table-block 基准上,表格识别的总体 TEDS 与结构 TEDS 得分最高,总体编辑距离最低,全面超越所有对比模型。
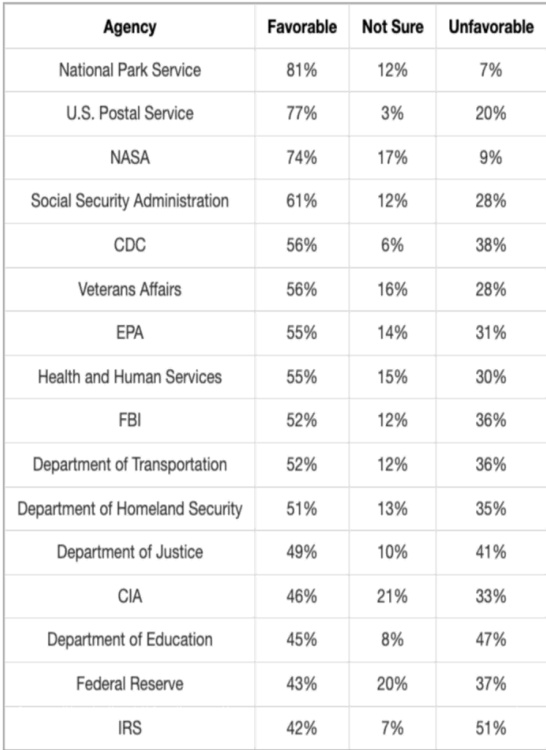
作者使用表格展示不同条件下(包括不同深度与橡胶膜方向)的压力测量结果。结果显示,压力计中液面高度差随深度增加而增大,橡胶膜方向对测量压力有影响,深度为 15 cm 且膜面侧向时差异最大。
作者使用 OmniDocBench v1.5 基准评估文档解析性能,表格显示 PaddleOCR-VL 在总体编辑距离上取得 0.115 的最高分,优于所有其他方法在文本、公式与表格识别等关键指标上的表现。结果表明,PaddleOCR-VL 在多数类别中领先,尤其在中文文本与表格识别方面表现突出,同时展现出强大的多语言与复杂布局处理能力。
作者使用 In-house-OCR 基准评估多语言文本识别性能,报告各类文字的编辑距离。结果显示,PaddleOCR-VL 在所有评估语言中均取得最低编辑距离,包括阿拉伯语(0.122)、韩语(0.052)、泰米尔语(0.043)、希腊语(0.135)、泰语(0.081)、泰卢固语(0.114)、天城文(0.097)、西里尔文(0.109)、拉丁文(0.013)和日语(0.096),展现出卓越的多语言识别能力。

作者使用表格展示对美国多个政府机构的公众意见调查结果,显示持正面、不确定或负面看法的受访者比例。结果显示,国家公园管理局的正面评价最高(81%),而国税局最低(42%),各机构从上至下呈现明显的负面评价趋势。