Command Palette
Search for a command to run...
WorldMirror:基于任意先验提示的通用3D世界重建
WorldMirror:基于任意先验提示的通用3D世界重建
Yifan Liu Zhiyuan Min Zhenwei Wang Junta Wu Tengfei Wang Yixuan Yuan Yawei Luo Chunchao Guo
摘要
我们提出WorldMirror,一个面向多样化三维几何预测任务的全集成、前馈式统一模型。与现有方法受限于仅图像输入或针对特定任务进行定制化设计不同,我们的框架能够灵活融合多种几何先验信息,包括相机位姿、内参以及深度图,并在一次前向传播中同时生成多种三维表示形式:稠密点云、多视角深度图、相机参数、表面法向量以及三维高斯分布。该优雅而统一的架构充分利用可用的先验信息,有效缓解结构歧义问题,从而在单次前向推理中输出几何一致的三维结果。WorldMirror在多个基准测试中均取得了当前最优性能,涵盖相机参数估计、点云重建、深度图预测、表面法向量估计以及新视角合成等任务,同时保持了前馈推理的高效性。相关代码与模型将很快公开发布。
一句话总结
浙江大学、香港中文大学与腾讯混元的研究人员提出 WorldMirror,一种前馈模型,通过将相机位姿、深度等多样化先验信息整合到单一架构中,统一多个三维几何预测任务,实现点云、3D高斯、深度图与法向量的同步生成,在保持几何一致性的同时,于各类基准测试中达到最先进效率。
主要贡献
- WorldMirror 提出一种通用的前馈三维重建框架,将校准后的相机内参、位姿及深度图等多样化几何先验整合至统一架构中,能够稳健处理结构歧义问题,并提升跨任务的几何一致性。
- 模型采用多模态先验提示机制,结合专用标记化与动态先验注入策略,可灵活处理任意可用先验子集,同时在推理过程中保持高性能。
- WorldMirror 在多个三维重建基准测试中均达到最先进水平,其在点图与相机估计、表面法向预测及新视角合成等任务上的表现全面超越现有方法,且所有输出均在单次前向传播中完成。
引言
视觉几何学习在增强现实、机器人和自主导航等应用中至关重要,准确的图像三维重建是其核心。尽管近期前馈神经网络模型已逐步取代传统的迭代方法(如 SfM 和 MVS),但这些模型通常仅处理原始图像,缺乏融合校准内参、相机位姿或来自激光雷达/RGB-D传感器深度等宝贵几何先验的能力,导致在复杂场景下鲁棒性受限。此外,大多数现有模型为任务专用,仅解决单一或少数几何任务,限制了其通用性与在更广泛流水线中的集成能力。
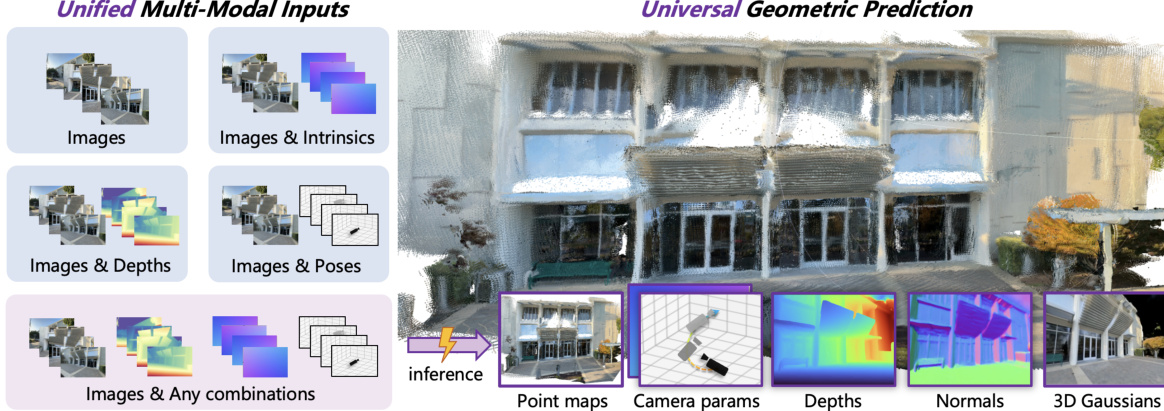
为克服上述局限,作者提出 WorldMirror,一种通用三维重建框架,通过新颖的多模态先验提示机制,灵活利用任意可用的几何先验。该方法采用轻量级专用编码器,将不同先验转换为统一表示:紧凑型先验(如位姿、内参)编码为单个标记,密集型先验(如深度图)则转换为空间对齐的标记,从而实现灵活统一的输入处理。训练阶段采用动态先验注入策略,确保模型在推理时对任意先验可用性具有鲁棒性。模型进一步在单一基于 Transformer 的架构中统一了多种三维任务,包括点图回归、相机与深度估计、表面法向预测及新视角合成,并辅以系统性的课程学习策略以应对复杂的多任务训练。实验表明,WorldMirror 在各类基准测试中均达到最先进性能,无论在精度还是任务覆盖范围上均优于先前方法。
方法
作者采用统一的前馈架构,以应对多样化的三维几何预测任务,实现从多视角图像中同步生成多种三维表示。该框架名为 WorldMirror,设计上可灵活整合可用的各类几何先验(如相机位姿、内参、深度图),同时在先验缺失时仍保持稳健性能。整体架构由多模态先验提示机制与通用几何预测模块构成,共同形成端到端几何理解的完整系统。
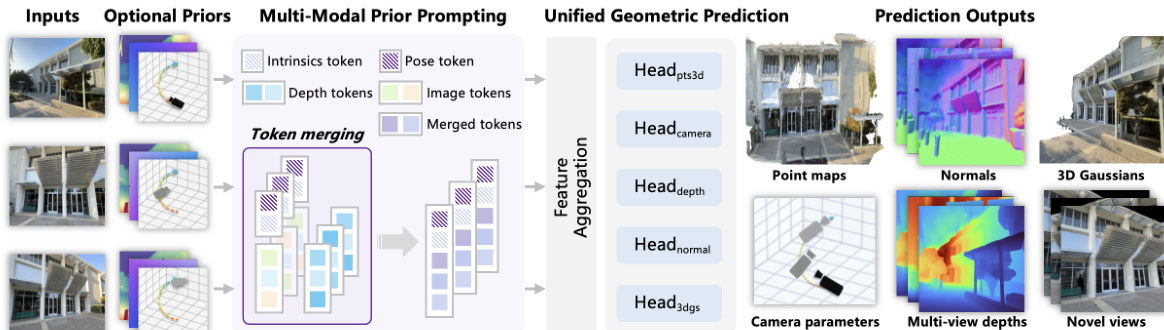
如图所示,框架从多视角图像输入开始,与可选的先验信息一同处理。模型采用多模态先验提示策略,将多种先验模态嵌入视觉表示中。对于相机位姿,每个位姿 [Ri∣ti] 被归一化至单位立方体,并通过将旋转矩阵转换为四元数,再与归一化平移向量结合,编码为7维向量。该向量随后通过两层MLP投影为维度 D 的标记,生成相机位姿标记 Ticam。类似地,校准后的内参以焦距和主点形式提取,按图像分辨率归一化后,通过两层MLP投影为内参标记 Tiintr。深度图作为密集空间信号,被归一化至 [0,1],并通过与视觉标记块大小匹配的卷积层嵌入,生成空间对齐的深度标记 Tidepth,并叠加至图像标记上。这些先验标记随后与图像标记 Tiimg 拼接,形成统一的提示标记集 Tiprompt,使模型能够适应任意可用先验的组合。
复合标记集由视觉Transformer骨干网络处理,该网络在多视角间进行特征聚合,生成综合表示。这些表示随后输入多任务头,实现通用几何预测。框架可预测多种几何属性,包括三维点图、多视角深度图、相机参数、表面法向与三维高斯。对于点图、深度与相机参数估计,模型使用DPT头从图像标记回归密集输出,而相机参数则通过Transformer层从相机位姿标记预测。表面法向估计采用DPT头后接L2归一化,以确保输出为单位向量,并采用混合监督策略,结合标注数据与由真实深度图推导的伪法向,缓解标注稀缺问题。

对于新视角合成,模型通过DPT头回归像素级高斯深度图与特征图,预测三维高斯点云(3DGS)。这些深度预测利用真实相机位姿与内参进行反投影,获得高斯中心;其余属性——透明度、方向、尺度、残差球谐颜色系数及融合权重——则通过将特征图与卷积网络提取的外观特征结合推断。为减少重叠区域的冗余,采用体素化对每像素高斯进行聚类与剪枝。训练时,输入图像被划分为上下文集与目标集,三维高斯由上下文视角构建,并通过可微分光栅化器渲染,以监督目标视角与原始上下文视角,确保视角间一致性。
模型通过最小化复合损失函数实现端到端训练,该函数整合所有预测任务的监督信号。包括点图、深度、相机参数、表面法向与3DGS的损失,其中3DGS损失进一步包含RGB渲染、深度一致性与梯度一致性项,以增强鲁棒性并减少预测高斯中的漂浮点。框架利用可用先验的能力使其在挑战性场景中实现稳健重建,而其多任务设计则确保不同输出间的几何一致性。
实验
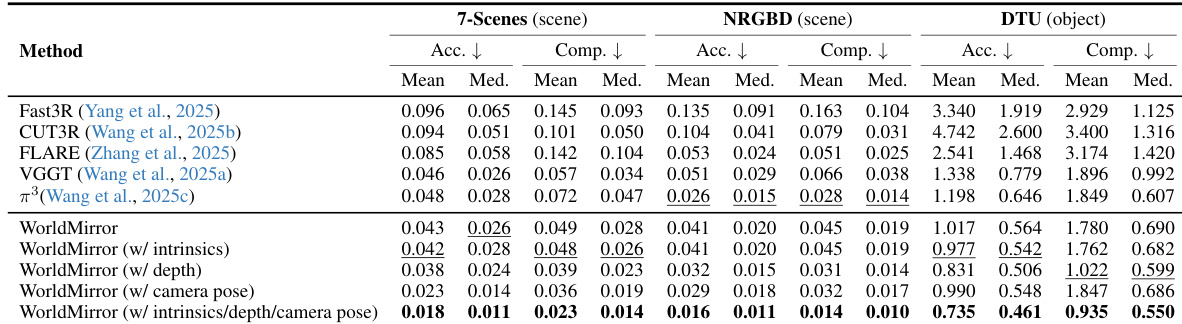
- 在 7-Scenes、NRGBD 与 DTU 上进行点图重建:相比 VGGT 与 π3,分别取得 10.4% 与 17.8% 的平均精度提升,使用全部先验时较无先验基线分别提升 58.1% 与 53.1%。
- 在 RealEstate10K、Sintel 与 TUM-dynamics 上进行相机位姿估计:在 RealEstate10K 与 TUM-dynamics 上实现卓越的零样本性能,在 Sintel 上虽因动态场景训练数据有限,仍取得具有竞争力的结果。
- 在 iBims-1、NYUv2 与 ScanNet 上进行表面法向估计:显著优于基于回归与扩散的方法,在各数据集上均保持一致提升。
- 在 RealEstate10K、DL3DV 与 VR-NeRF 上进行新视角合成:在稀疏与密集视角设置下,所有指标均超越前馈3DGS基线(包括 AnySplat),展现出强大的泛化能力与渲染质量。
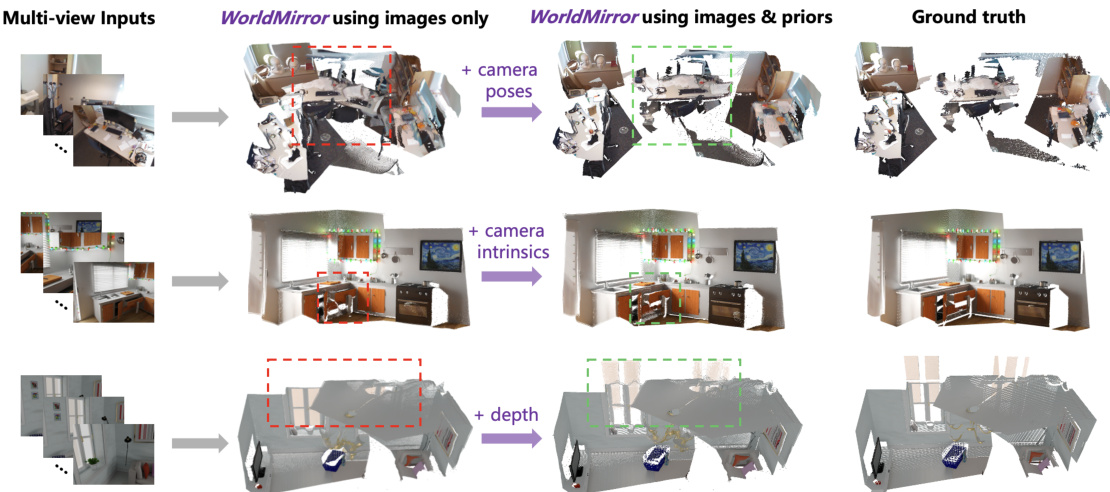
- 先验引导评估:引入单一或多几何先验(相机位姿、内参、深度)均提升各任务性能,其中相机位姿提供全局几何约束,内参解决尺度歧义,深度图提供像素级约束。
- 消融研究:单标记先验嵌入优于逐像素密集条件;移除3DGS预测框架或训练策略中的任一组件均导致新视角合成性能下降。
- 3DGS后优化:使用预测点云或3DGS基元初始化显著加速收敛并提升渲染质量,超越前馈基线。
结果表明,WorldMirror 在三个数据集上的相机位姿估计任务中均达到最先进水平,多数指标超越先前方法。在 RealEstate10K 与 TUM-dynamics 上,其相对旋转与平移精度全面超越所有基线;在 Sintel 上虽因训练数据中户外动态场景有限,仍保持具有竞争力的结果。

结果表明,所提方法在三个数据集上均表现优异,RealEstate10K 与 VR-NeRF 上取得最高 PSNR 与 SSIM 值,DL3DV 上 LPIPS 指标显著优于基线方法。模型在不同视角数量下均保持强性能,展现出新视角合成中的鲁棒性与泛化能力。

作者使用 WorldMirror 在 7-Scenes、NRGBD 与 DTU 数据集上评估点图重建,报告准确率与完成度指标。结果表明,即使不使用任何先验,WorldMirror 也优于此前最先进方法,平均准确率显著提升,结合全部先验后进一步增益,所有数据集上均取得最佳结果。
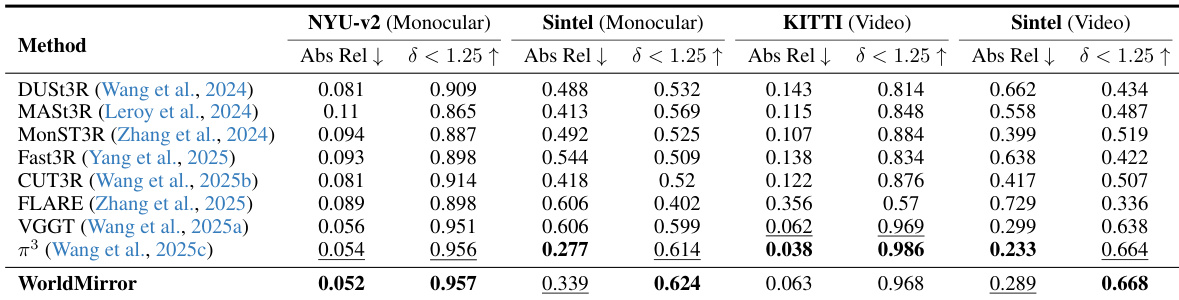
作者使用 WorldMirror 在 NYUv2、Sintel 与 KITTI 数据集上评估单目与视频深度估计,报告绝对相对误差及阈值 1.25 内预测占比。结果表明,WorldMirror 在所有基准上均表现具有竞争力,多数情况下达到或超越最先进方法,尤其在 Sintel 与 KITTI 上表现突出,尽管在 KITTI 上与 π3 相比存在小幅差距,作者归因于训练数据中城市驾驶场景代表性不足。
结果表明,WorldMirror 在 RealEstate10K 与 DL3DV 数据集上的新视角合成任务中均表现卓越,相比 FLARE 与 AnySplat 等基线,在 PSNR、SSIM 与 LPIPS 指标上均有显著提升。相机与内参先验的引入进一步提升了重建质量,尤其在密集视角设置下,充分验证了所提统一几何表示的有效性。
