Command Palette
Search for a command to run...
X-VLA:作为可扩展跨具身视觉-语言-动作模型的软提示Transformer
X-VLA:作为可扩展跨具身视觉-语言-动作模型的软提示Transformer
摘要
成功的通用型视觉-语言-动作(Vision-Language-Action, VLA)模型依赖于在多种机器人平台上的有效训练,并需利用大规模、跨本体(cross-embodiment)、异构的多样化数据集。为有效利用丰富且多样的机器人数据源所固有的异构性,我们提出了一种新颖的软提示(Soft Prompt)方法,该方法仅引入极少量新增参数,通过将提示学习(prompt learning)思想融入跨本体机器人学习框架,并为每种不同的数据源分别引入可学习的嵌入(embeddings)集合。这些嵌入作为特定本体的提示,在统一框架下使VLA模型能够高效地挖掘和利用不同本体之间的特征差异。我们提出的新型X-VLA架构——一种基于流匹配(flow-matching)的VLA结构——完全依赖于软提示化的标准Transformer编码器,兼具良好的可扩展性与结构简洁性。在6个仿真环境及3台真实机器人平台上进行的综合评估表明,我们的0.9B参数规模实例X-VLA-0.9B在一系列基准测试中均达到当前最优(SOTA)性能,在从灵活灵巧操作到跨本体、跨环境、跨任务的快速适应能力等多个维度上均展现出卓越表现。项目主页:https://thu-air-dream.github.io/X-VLA/
一句话摘要
清华大学人工智能产业研究院(AIR)、上海人工智能实验室的研究人员提出X-VLA-0.9B模型,这是一种基于流匹配的视觉-语言-动作模型。该模型通过本体特定软提示(可学习嵌入向量)解决跨本体异质性问题(不仅限于动作空间),在六项仿真基准测试和包括高难度灵巧布料折叠任务在内的三款真实机器人平台上取得最先进成果,且仅需极少参数调优。
核心贡献
- 现有视觉-语言-动作模型因机器人平台的硬件与动作空间差异难以泛化至异构平台,导致训练不稳定且跨域性能不佳,即使利用预训练视觉语言模型亦无法解决。
- X-VLA引入软提示机制,通过为每种硬件配置设计可学习嵌入向量吸收本体特异性差异,在保留共享主干网络进行本体无关推理的同时,实现对多样化数据集的可扩展预训练。
- 在广泛基准测试中,X-VLA-0.9B以显著优势在数百种场景取得最先进结果,并在0.9B参数量、290K训练片段及7个数据源条件下展现出无饱和迹象的可扩展训练趋势。
引言
视觉-语言-动作(VLA)模型对实现机器人理解自然语言指令、视觉感知环境并执行物理动作至关重要——然而由于机器人平台的硬件与动作空间异质性,其在实际部署中面临挑战。现有方法或手动重塑动作空间,或在语义层面统一动作,但均未能解决本体特定推理问题,导致扩展至多样化数据源时训练不稳定且泛化能力差。作者提出X-VLA框架,利用轻量级硬件特定嵌入向量作为软提示吸收本体差异,同时保留共享主干网络用于通用推理。该设计支持在模型规模、数据多样性及数据量维度进行可扩展预训练——仅需极少可调参数即取得最先进成果,并展现出无性能饱和的进一步扩展潜力。
数据集
作者描述数据集构成与使用方式如下:
-
构成与来源:核心数据集Soft-FOLD是专为灵巧操作研究创建的1,200段高质量人类演示片段(非公开数据集)。论文提及基础预训练广泛依赖经同行评审的开源机器人数据集(如Bu等, 2025; Wu等, 2025),但未在此详述。
-
关键子集细节(Soft-FOLD):
- 规模:1,200段精选片段(含重置操作,每小时采集20-25段)。
- 来源:基于结构化策略的人类演示。
- 过滤规则:
- 任务分解为第一阶段(通过重复动作抚平杂乱布料直至关键点显现)和第二阶段(对抚平布料进行规整折叠)。
- 舍弃无序/非结构化第一阶段演示以避免策略学习不一致。
- 采集过程中排除失败尝试。
-
模型中的数据使用:
- 完整Soft-FOLD数据集用于训练X-VLA-0.9B灵巧操作微调模型。
- 采用DAgger式迭代收集:每100段后由ACT模型识别失效模式,指导针对性补充演示。
- 混合比例遵循此优化循环,优先采用失效场景特定数据。
-
处理细节:
- 无显式裁剪操作;分割依赖两阶段任务分解。
- 元数据隐式捕获折叠过程中的关键技能(定位、抓取、放置、摆动)。
- 人类策略标准化至关重要——第一阶段需刻意抚平以降低布料动态变化,方进入第二阶段折叠。
方法
作者采用极简但可扩展的架构实现跨本体视觉-语言-动作(VLA)建模,核心是软提示Transformer模块。创新点在于引入可学习的本体特定软提示:根据硬件类型查询后早期注入模型流程,吸收异构机器人数据集的差异。这些随机初始化并端到端优化的提示向量隐式编码硬件配置信息,无需手工文本描述或破坏性投影层。如框架图所示,模型集成预训练视觉语言模型(VLM)用于高层任务推理,共享视觉Transformer(ViT)处理辅助视角,在保持预训练表征的同时确保语义对齐。多模态标记(含语言、主视角图像及可选腕部视角输入)与本体感知状态及含噪动作片段融合后,投影至统一特征空间,再由标准自注意力Transformer模块处理。该设计使模型能高效随数据与规模扩展,同时保持训练稳定性。
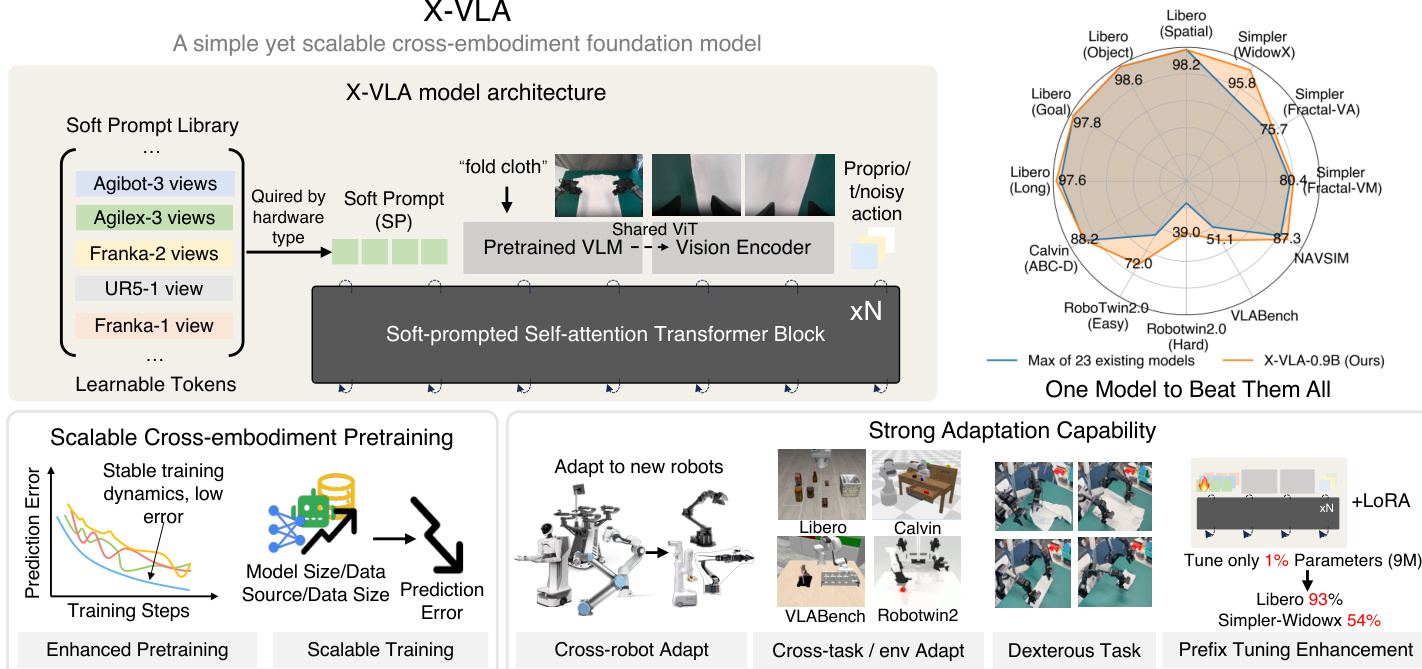
为解决跨本体异质性挑战,作者实证评估四种策略(如对比图所示)。第一种"领域特定动作投影"为每数据集设置独立输出头,但无法影响早期推理;第二种"HPT式投影"通过跨注意力重采样器将领域特定观测映射至共享空间,但可能破坏预训练VLM特征;第三种"语言提示"将机器人文本描述注入VLM编码器,却受限于可扩展性与标注依赖。而本文提出的软提示法(右侧面板)直接将可学习标记按数据集ID查询后注入Transformer输入,在不修改主干预训练结构的前提下实现本体感知推理。实证表明该方法在训练稳定性与泛化能力上显著更优。

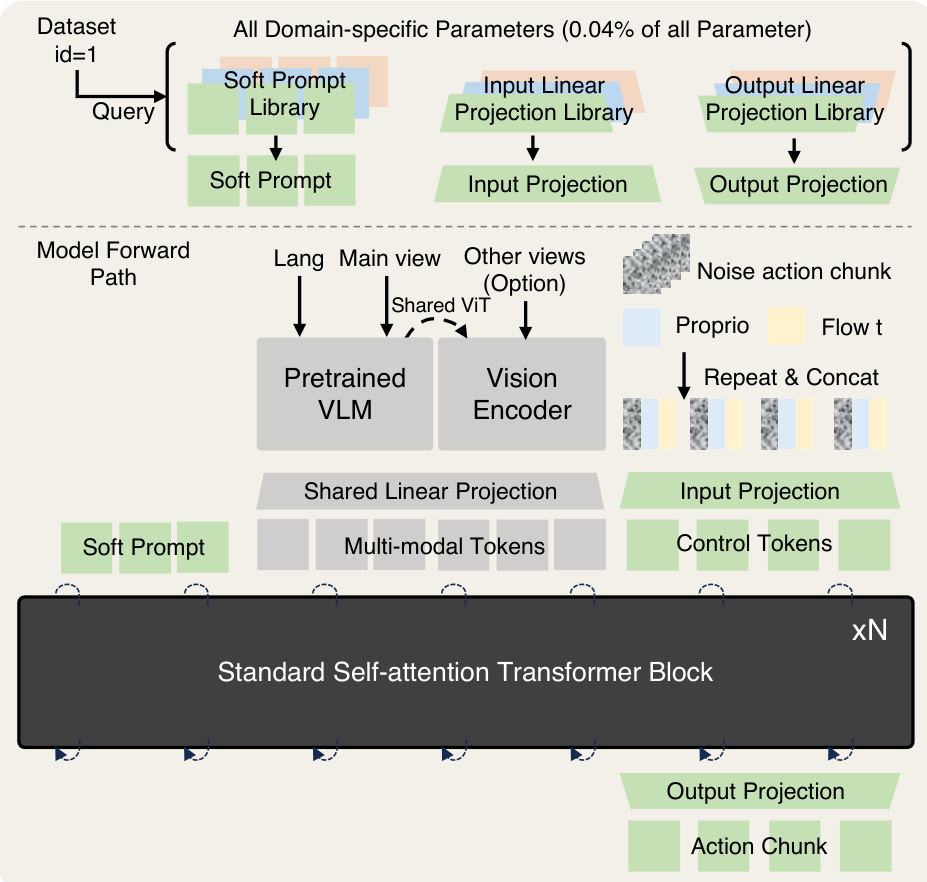
X-VLA完整前向传播始于根据数据集标识符查询软提示库,随后与语言、主视角图像(经预训练VLM处理)及可选辅助视角(通过共享ViT编码)生成的多模态标记拼接。本体感知状态与含噪动作片段融合时间嵌入后投影至相同标记空间,所有标记输入标准Transformer主干网络,通过流匹配策略生成动作片段。模型参数效率突出:领域特定组件(软提示库、输入/输出投影)仅占总参数0.04%。适配新机器人时采用两阶段流程:先冻结主干网络预热新提示,再联合微调二者。该策略通过极小参数更新实现快速专业化,适配实验已验证其有效性。
实验
- 扩展性实验验证X-VLA在模型规模(达0.9B参数)、数据多样性(7个来源)及数据量(290K片段)维度的性能增长,趋势无饱和迹象,且预训练ℓ₁验证误差与下游成功率强相关。
- 适配实验在5项仿真基准取得最先进结果(Libero成功率98%,Simpler-WidowX达96%),在真实平台(WidowX、AgileX、AIRBOT)以参数高效微调(LoRA,仅1%可调参数)实现灵巧布料折叠100%成功率,Libero达93%。
- 可解释性分析通过T-SNE聚类证实软提示捕获本体特征(与硬件配置对齐),并支持高效跨本体迁移,预训练提示使早期训练阶段适配速度提升30%。
- 数据效率测试表明在有限监督下性能稳健,仅10段演示即可在Libero保持91.1%成功率。
- 多本体联合适配(Libero、BridgeData、Calvin-ABC)维持或提升单域性能,证明存在正向跨域知识迁移。
作者在多项仿真基准评估X-VLA-0.9B,报告Libero平均98.1%、Calvin(ABC→D)平均4.43等高成功率。VLAbench结果呈现类别差异:语义指令类63.1分,跨类别评分最低25.1分,表明模型在分布内及指令对齐任务上表现更强。这些结果凸显模型在标准基准的强泛化能力,同时揭示跨类别迁移的挑战。

作者对比X-VLA与DiT、MM-DiT、π₀-Style等主干架构,以验证误差为指标。结果显示X-VLA以0.041最低验证误差超越所有基线,在异构数据集上展现更优稳定性与性能。
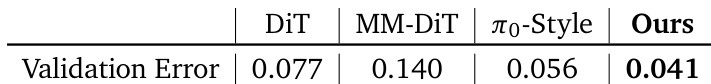
作者在Libero基准测试X-VLA-0.9B的数据效率(采用PEFT与有限演示)。结果表明即使仅10段演示,模型仍保持91.1%平均成功率(50段为92.8%),凸显其在极端数据稀缺下的高效适配能力。

作者在Simpler基准评估X-VLA-0.9B在多机器人平台及任务类型的表现,报告特定物体操作任务成功率及均值。模型在WidowX机器人任务中表现优异(平均95.8%),优于Google机器人在视觉匹配(80.4%)与视觉聚合(75.7%)场景的表现,印证论文强调的软提示本体特定调优效果。

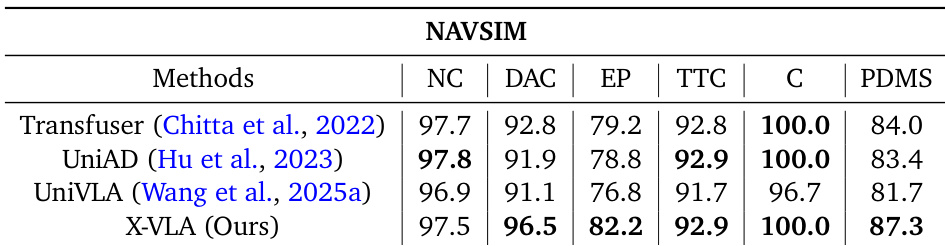
作者在NAVSIM自动驾驶基准通过闭环仿真评估X-VLA,报告五项指标聚合的PDM分数。X-VLA以87.3最高PDM分超越Transfuser、UniAD、UniVLA等方法,在可行驶区域合规性(96.5)与防碰撞(100.0)等单项指标上亦达最优。结果表明:尽管基于异构机器人数据预训练,X-VLA端到端视觉-语言-动作架构仍能有效泛化至复杂真实驾驶场景。