Command Palette
Search for a command to run...
对话翻转:用户语言模型的训练与评估
对话翻转:用户语言模型的训练与评估
Tarek Naous Philippe Laban Wei Xu Jennifer Neville
摘要
与大型语言模型(LM)的对话涉及两个参与者:一位由人类用户主导的对话发起者,以及一个响应用户请求的LM助手。为了胜任这一特定角色,LM在预训练之后会进行进一步微调,使其成为高效、有帮助的助手——即优化为能够生成详尽、结构清晰、无歧义且语法正确的回应。相比之下,用户的发言通常并不完美,每位用户在表达请求时方式各异,有时仅投入部分精力,在对话过程中不断调整和修正自己的表述。为了在更贴近现实的场景中评估LM的性能,以往的研究通过在多轮对话中模拟用户行为来实现,通常做法是让原本训练为“有帮助助手”的LLM充当用户角色。然而,我们发现,作为助手的LM在模拟用户方面表现不佳,且令人意外的是,性能越好的助手反而作为用户模拟器的效果越差。为此,我们提出了一种专门设计的“用户语言模型”(User LM)——这类模型经过后训练,旨在真实模拟人类用户在多轮对话中的行为。通过多种评估实验,我们证明了User LM在行为模式上更贴近真实人类,且在模拟鲁棒性方面优于现有方法。当利用User LM来模拟编程与数学对话场景时,即使是最强大的助手模型(GPT-4o)的性能也从74.6%显著下降至57.4%。这一结果表明,更真实的模拟环境会使助手面临更大挑战,凸显了其在应对多轮对话中用户表达复杂性与动态变化方面的局限性。
一句话总结
来自微软研究院和佐治亚理工学院的作者提出 UserLM-8b,一种专为模拟多轮对话中人类用户而设计的用户语言模型,其在与真实用户行为的对齐性以及模拟鲁棒性方面优于基于助手的模拟器。后者因无法捕捉对话细微差别,导致在真实场景中高估助手性能。
主要贡献
- 以往工作依赖于助手语言模型(LMs)来模拟多轮对话中的人类用户,但这些模型由于训练目标是成为有帮助的助手,导致生成的用户行为过于结构化、合作性强且不真实,从而高估了助手LM的性能。
- 作者提出用户语言模型(User LMs),专为模拟真实人类用户而设计,通过生成多样化、渐进式且具有上下文细微差别的语句,反映用户在对话中逐步明确意图的真实过程。
- 评估结果表明,User LMs 更好地契合人类对话模式,并导致助手性能更真实地下降——例如,GPT-4o 在编码任务上的成功率从 74.6% 降至 57.4%,证明其在构建稳健、类人模拟环境方面的有效性。
引言
作者针对评估对话式助手语言模型(LMs)时日益增长的真实用户模拟需求展开研究。这些模型在静态基准测试中表现良好,但在与真实用户的动态、多轮交互中却表现不佳。以往方法依赖于提示助手LM扮演用户角色,但这些模型因优化目标为清晰与合作,生成的用户行为过于结构化、持续且不真实,导致性能估计被夸大。作者提出用户语言模型(User LMs),专为模拟人类用户而设计,通过生成多样化、渐进式且具有上下文细微差别的语句,反映现实对话模式。其核心贡献是一个训练与评估User LMs的框架,该框架更贴近人类行为,体现在模拟鲁棒性、意图分解和对话终止能力的提升。当用于评估 GPT-4o 在编码与数学任务上的表现时,User LMs 将其性能从 74.6% 降至 57.4%,揭示了在理想化模拟器掩盖下助手模型存在的关键缺陷。
数据集
- 数据集由 WildChat(一个大规模对话语料库)中的对话组成,并额外整合了 PRISM 数据集用于评估与训练。
- WildChat 最初通过在首轮用户提示上使用 7-gram 计数器去除近似重复对话,从原始规模中缩减;该过程消除了重复的提示模板,最终得到 384,336 条唯一对话的清洗数据集。
- 作者手动识别出高频但非自然的提示模式——例如某模板出现在超过 81,000 次对话中——认为其具有人工痕迹,可能对模型质量造成负面影响。
- 清洗后的 WildChat 数据作为训练混合数据的一部分,与其他来源(如 PRISM)结合,采用经过优化的混合比例以平衡多样性与自然性。
- 训练过程中,作者采用裁剪策略,聚焦于每条对话的前几轮,以保持连贯性并减少长对话或重复对话中的噪声。
- 每条对话的元数据基于首轮用户发言提取的意图标签构建,支持对生成响应与用户意图之间对齐性的评估。
- PRISM 数据集用于评估,尤其在对话终止和与用户意图的 n-gram 重叠方面,模型性能通过各轮的精确率、召回率和 F1 分数进行衡量。
方法
作者利用真实的人类-助手对话作为训练数据,训练一种模仿人类对话行为的用户语言模型(UserLM)。核心方法是“反转对话”,将每条对话转化为建模用户话语条件分布的训练样本。在第一轮,模型基于高层用户意图进行条件建模;在后续轮次中,则同时基于意图和不断演化的对话状态进行条件建模。该框架如以下图示所示,展示了如何将一个 K 轮对话转化为 K+1 个训练样本,每个样本均基于意图和先前对话历史,生成下一轮用户话语。

该过程始于从现有对话中生成高层用户意图。这些意图被定义为抽象的、总体的目标,捕捉用户目标而不包含具体细节,既不过于模糊也不过于具体。为生成这些意图,作者使用 GPT-4o 配合提示模板,提供完整的对话历史,并指示模型生成用户高层意图的简洁摘要。提示中包含三个手工设计的示例,以引导模型生成一致且聚焦于交互总体目的的摘要。
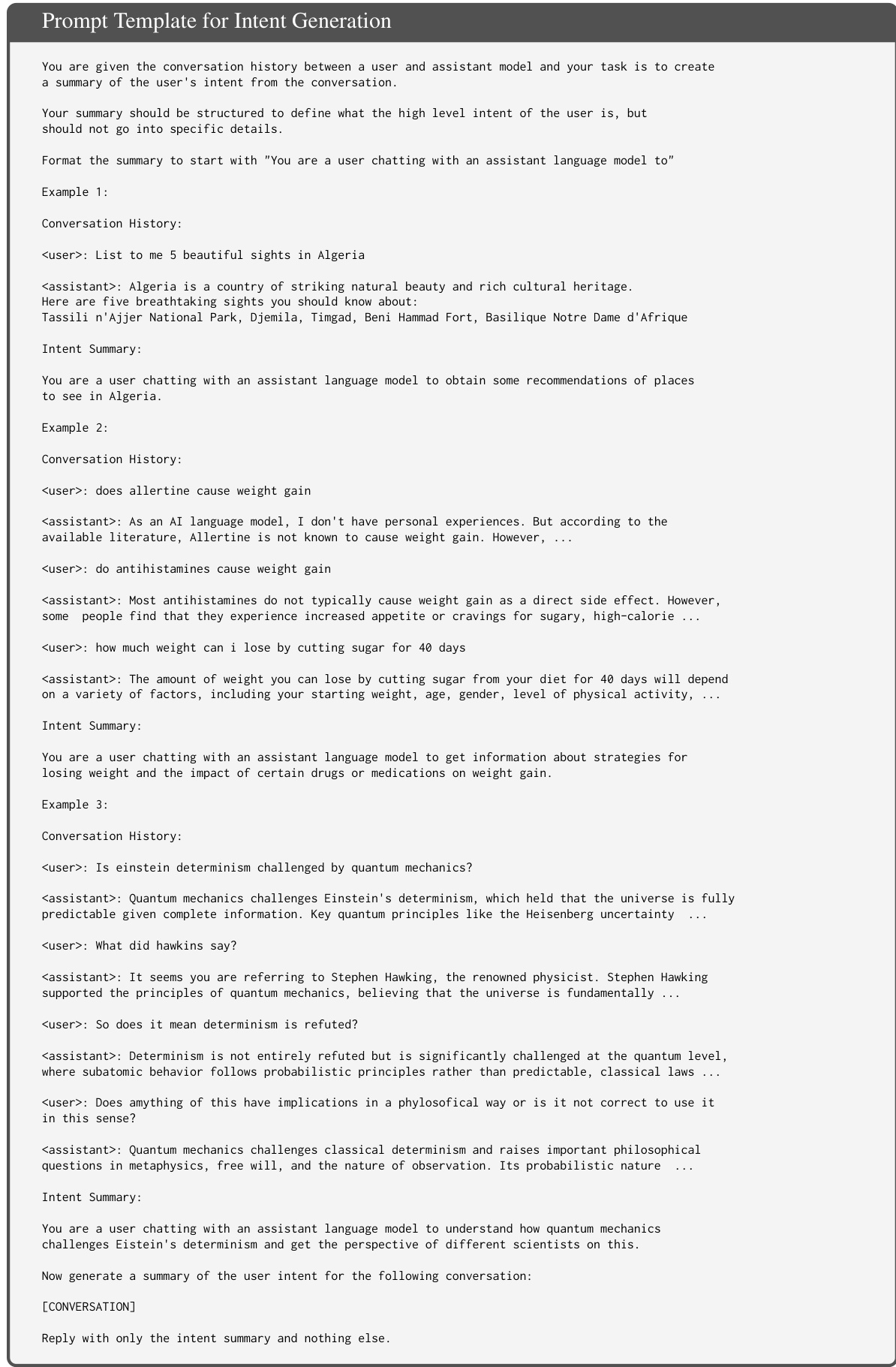
意图生成后,作者使用助手语言模型(LMs)模拟用户行为,以生成 UserLM 的训练数据。该模拟分为两个阶段:首轮和后续轮次。对于首轮,提示模板指示助手LM根据提供的意图生成初始用户话语,模拟人类用户自然开启对话的方式。提示强调真实用户行为,如拼写错误、不规范标点、信息分拆到多轮等,但避免过度夸张这些特征。

对于后续轮次,使用不同的提示模板,提供截至当前点的对话历史。随后,指示助手LM基于意图和对话状态生成下一轮用户话语。提示中特别要求,若对话目标已达成,则以特殊 <|endconversation|> 标记响应,使模型能够学习自然终止对话的时机。

为评估模型对目标意图的遵循程度,作者采用“LM作为裁判”方法。使用提示模板判断用户模拟器在对话中的响应是否符合其原始意图。提示提供包括用户初始问题、AI 拒绝内容及用户回复在内的完整对话历史,并指示裁判模型将响应分类为“REFUSED”(若重复原始问题)或“ACCEPTED”(若遵循AI建议)。该评估确保 UserLM 在整个对话过程中保持对目标的专注。
实验
- UserLM-8b 在 WildChat 和 PRISM 数据集上均取得最低困惑度(PPL),相比基线模型低达 60–70%,表明其在人类用户语言分布上的优越对齐性。
- 测试时引入意图条件可降低所有模型的 PPL,但训练时使用意图条件带来更强的敏感性和更优性能,证实意图条件训练的优势。
- UserLM-8b 在多轮交互中优于提示助手:其生成的首轮话语更具多样性(1-gram 唯一性达 94.55%,接近人类水平),意图分解更有效(与意图的 1-gram 重叠仅 2.69%),对话终止 F1 得分为 63.54,远高于助手的 3–15。
- User LMs 生成的语句更自然,Pangram 检测出 77–81% 的输出为人工撰写(而提示助手仅为 0–3%),表明其文本分布具有明显用户特征。
- User LMs 在角色与意图遵循方面表现出高鲁棒性(分别为 91–98% 和 93–97%),而提示助手在模糊情境下常回归助手行为。
- 将 UserLM 从 1b 扩展至 8b 在所有指标上均提升性能,而助手LM的扩展(如 Llama3-8b vs. 1b,GPT-4o vs. GPT-4o-mini)未带来一致收益。
- 在外生模拟中,UserLM-8b 实现更高的意图覆盖率(76–86%)、更强的信息与词汇多样性,以及更可变的对话节奏(2.1–6.7 轮),导致助手任务性能下降 17%,表明其构建了更具挑战性且更真实的评估环境。
作者使用困惑度(PPL)评估模型在用户话语中与人类语言分布的对齐程度。结果显示,UserLM-8b 在 WildChat 和 PRISM 数据集上均取得最低 PPL,显著优于所有基线模型,尤其在域外的 PRISM 集上表现突出。这表明 UserLM-8b 在建模用户语言和利用通用意图方面优于基础模型或指令微调模型。

作者使用 UserLM-8b 模拟与助手的对话,证明其相比提示助手模型能生成更丰富、更真实的交互。结果表明,UserLM-8b 实现了更高的词汇多样性、更大的轮次变异性以及更自然的用户行为,导致助手性能下降 17%,源于更具挑战性的模拟环境。

作者使用从基础检查点训练的 UserLM-8b 在多个指标上取得最佳表现,优于更小模型以及从指令微调检查点初始化的模型。结果表明,UserLM-8b 在多轮交互和模拟鲁棒性方面得分最高,尤其在意图分解、对话终止和角色遵循方面,表明其与人类用户行为具有更强的对齐性。

结果显示,UserLM-8b 在数学与编码任务中的意图覆盖率低于 GPT-4o 和 4o-mini,但其信息多样性、节奏多样性和词汇多样性显著更高。UserLM-8b 还导致助手性能更低,表明其更真实、更丰富的用户行为为助手创造了更具挑战性的环境。

作者使用困惑度(PPL)评估模型在用户话语中与人类语言分布的对齐程度。结果显示,UserLM-8b 的 PPL 显著低于其他模型,尤其在训练与测试时均应用意图条件的情况下,表明其具有更优的分布对齐性。此外,从基础检查点训练的模型始终优于从指令微调检查点训练的模型,其中从基础模型训练的 UserLM-8b 达到最低 PPL 7.42。
