Command Palette
Search for a command to run...
VoxCPM:面向上下文感知语音生成与高保真声音克隆的 Tokenizer-Free TTS
VoxCPM:面向上下文感知语音生成与高保真声音克隆的 Tokenizer-Free TTS
VoxCPM Team
摘要
语音合成领域的生成式模型面临着一个根本性的权衡:离散 tokens 虽然能确保稳定性,但会牺牲表现力;而连续信号虽能保留丰富的声学特性,却会因任务耦合(task entanglement)而遭受误差累积的影响。这一挑战促使该领域转向依赖预训练语音 tokenizer 的多阶段 pipeline,但这种方式造成了语义与声学之间的脱节,限制了整体性且具表现力的语音生成。为了解决这些难题,我们提出了一种基于半离散残差表示(semi-discrete residual representations)的分层语义-声学建模方法,并推出了一种全新的无需 tokenizer 的 TTS 模型——VoxCPM。我们的框架引入了一个可微量化瓶颈(differentiable quantization bottleneck),从而诱导出自然的专业化分工:文本-语义语言模型(TSLM)负责生成语义-韵律规划,而残差声学模型(RALM)则负责恢复细粒度的声学细节。这种分层语义-声学表示引导一个基于局部 diffusion 的 decoder 来生成高保真语音 latents。至关重要的一点是,整个架构是在一个简单的 diffusion 目标函数下进行端到端训练的,从而消除了对外部语音 tokenizer 的依赖。通过在 180 万小时的海量双语语料库上进行训练,我们的 VoxCPM-0.5B 模型在开源系统中实现了最先进的(state-of-the-art)zero-shot TTS 性能,证明了我们的方法能够提供兼具表现力与稳定性的合成效果。此外,VoxCPM 展示了通过理解文本来推断并生成合适韵律与风格的能力,能够产出具有上下文感知表现力和自然流向的语音。为了促进社区驱动的研究与开发,VoxCPM 已基于 Apache 2.0 协议公开使用。
一句话总结
VoxCPM 团队提出了 VoxCPM,这是一个无需 tokenizer 的文本转语音框架。该框架利用带有半离散残差表示和可微量化瓶颈的分层语义-声学建模,通过端到端扩散训练,在上下文感知语音生成和声音克隆方面实现了最先进的 zero-shot 性能。
核心贡献
- 本文介绍了 VoxCPM,一种新型的无需 tokenizer 的文本转语音模型,它利用统一的端到端框架来解决语音表现力与稳定性之间的权衡。
- 该工作提出了一种分层语义-声学建模方法,其特点是具有一个可微量化瓶颈,将信息分离为用于内容稳定性的类离散骨架和用于声学细节的连续残差组件。
- 在 180 万小时双语语料库上进行的实验表明,该模型在可懂度和说话人相似度方面,在开源系统中实现了最先进的 zero-shot TTS 性能。
引言
现代文本转语音 (TTS) 系统力求在声学丰富性与语言稳定性之间取得平衡,这对于开发具有共情能力的虚拟助手和沉浸式数字分身至关重要。目前的基于离散 token 的方法可以确保稳定性,但受限于量化上限,会导致细粒度声学细节的丢失;而连续表示模型虽然保留了保真度,但往往难以应对误差累积和任务耦合问题。本文利用分层语义-声学建模框架,通过无需 tokenizer 的端到端架构解决了这一权衡问题。通过引入可微量化瓶颈,VoxCPM 诱导了一种自然的专业化分工:Text-Semantic Language Model 处理韵律规划,而 Residual Acoustic Model 恢复细粒度细节。
方法
本文提出了 VoxCPM,这是一种分层自回归架构,旨在根据输入的文本 tokens T={t1,...,tN} 生成连续语音潜变量序列 Z={z1,...,zM}。在此框架中,每个 zi∈RP×D 代表一个包含 D 维 VAE 潜向量的 P 帧 patch。生成过程公式化为:
\np(Z∣T)=∏i=1Mp(zi∣T,Z<i)
系统的核心是一个分层条件机制,将语义-韵律规划与细粒度声学合成分离。参考框架图:
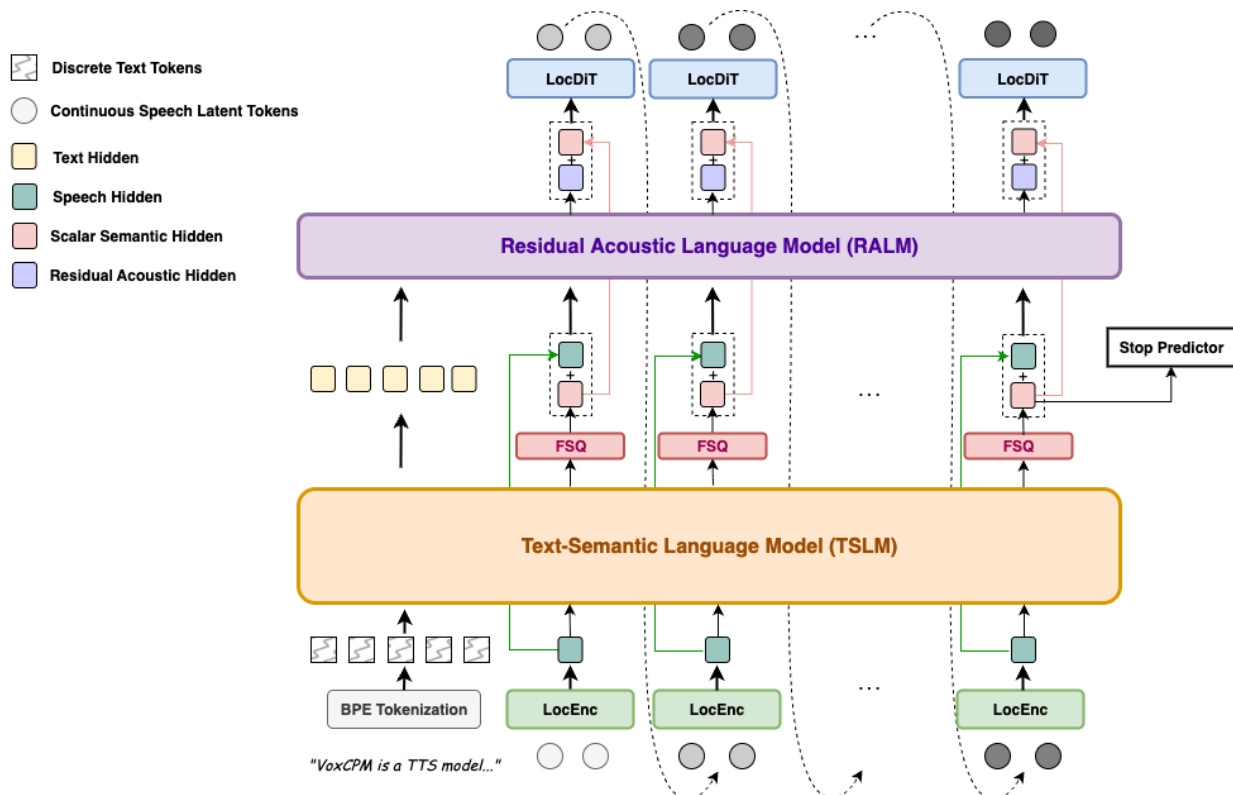
该架构由四个主要模块组成:局部音频编码器 (LocEnc)、文本语义语言模型 (TSLM)、残差声学语言模型 (RALM) 以及局部扩散 Transformer 解码器 (LocDiT)。
过程始于 LocEnc,它将历史 VAE 潜变量 patch 压缩为紧凑的声学嵌入 E<i=LocEnc(Z<i)。这些嵌入与文本 tokens 一起由 TSLM 处理。TSLM 利用预训练的文本语言模型作为骨干,以捕捉高层语言结构和韵律模式。为了确保生成过程的稳定性,TSLM 的连续隐藏状态通过有限标量量化 (FSQ) 层投影到结构化晶格上。此 FSQ 操作产生一种半离散表示,定义为:
hi,jFSQ=Δ⋅clip(round(ΔhTSLM),−L,L)
其中 Δ 是量化步长,L 是裁剪范围。该 FSQ 层作为一个瓶颈,捕捉粗略的语义-韵律骨架。
为了恢复量化过程中丢失的声学细节,采用了 RALM。它通过以 TSLM 隐藏状态、半离散 FSQ 表示和历史声学嵌入为条件,重建细微的语音特征:
hiresidual=RALM(HtextTSLM,H<iFSQ⊕E<i)
最终的条件信号 hifinal 是稳定的语义骨架与残差声学细节之和:
zi∼LocDiT(hifinal),hifinal=stable skeletonFSQ(TSLM(T,E<i))+residual detailsRALM(⋅)
该信号引导 LocDiT,这是一个执行去噪扩散过程以生成当前潜变量 patch zi 的双向 Transformer。为了提高一致性,前一个 patch zi−1 被包含在内作为额外的上下文。
模型使用条件流匹配 (conditional flow-matching) 目标进行端到端训练,以优化语音潜变量的质量:
LFM=Et,zi0,ϵ[∣vθ(zit,t,hifinal,zi−1)−dtd(αtzi0+σtϵ)∣2]
此外,使用二元交叉熵损失训练一个停止预测器 (stop predictor),以确定语音序列的终点。这种统一的训练方法确保了 TSLM、FSQ、RALM 和 LocDiT 都在朝着连贯且高保真语音合成的方向进行优化。
实验
实验通过全面的客观和主观基准测试(包括 SEED-TTS-EVAL 和 CV3-EVAL)对 VoxCPM 进行评估,以验证其相对于最先进开源 TTS 系统的性能。结果表明,分层架构有效地将语义规划与声学渲染解耦,通过其半离散瓶颈和残差声学建模实现了卓越的可懂度和说话人相似度。消融研究和视觉分析进一步证实,该模型的设计促进了稳定的学习、高效的数据利用以及上下文感知的韵律生成。
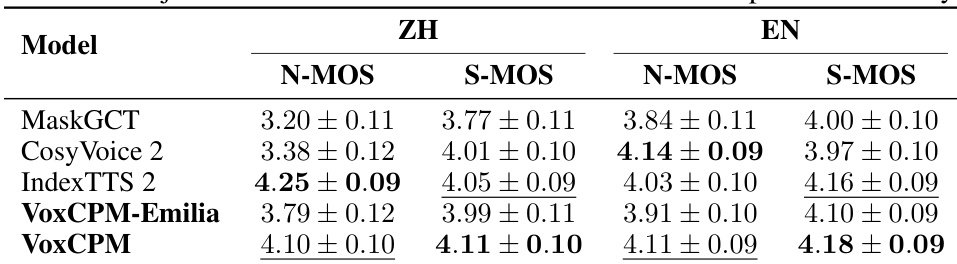
通过将 VoxCPM 及其变体与几种最先进的模型进行主观评估对比,结果显示 VoxCPM 在中文和英文语言中均在自然度和说话人相似度方面获得了高分。与评估的基准模型相比,VoxCPM 在中英文方面均实现了卓越的说话人相似度。在中文评估中,VoxCPM 显示出很高的自然度得分,尽管在这一特定指标上略逊于 IndexTTS 2。尽管 VoxCPM-Emilia 变体是在较小的数据集上训练的,但仍保持了具有竞争力的性能水平。
使用两阶段 Warmup-Stable-Decay 学习率调度方案对不同的训练阶段和模型变体进行了比较。训练配置因模型类型、总迭代次数和所使用的硬件资源而异。与 Emilia 变体和消融模型相比,VoxCPM 模型经历了更长的训练过程。在 terms of tokens 方面,衰减阶段比稳定阶段使用了更大的 batch size。训练 VoxCPM 模型比所示的其他配置需要更多的 GPU 资源。

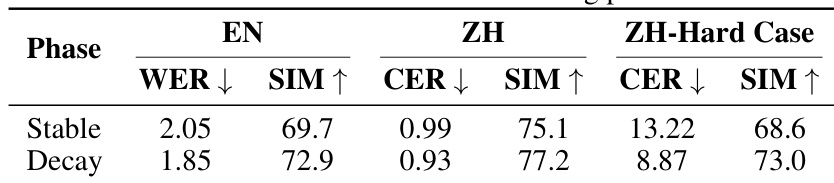
评估了两阶段 Warmup-Stable-Decay 学习率调度对模型性能的影响。结果显示,从稳定阶段过渡到衰减阶段会导致中英文所有测量指标的持续提升。与稳定阶段相比,衰减阶段降低了中英文的错误率。在衰减阶段,所有测试语言的说话人相似度得分均有所提高。模型在衰减阶段后,在具有挑战性的中文案例上表现出增强的鲁棒性。
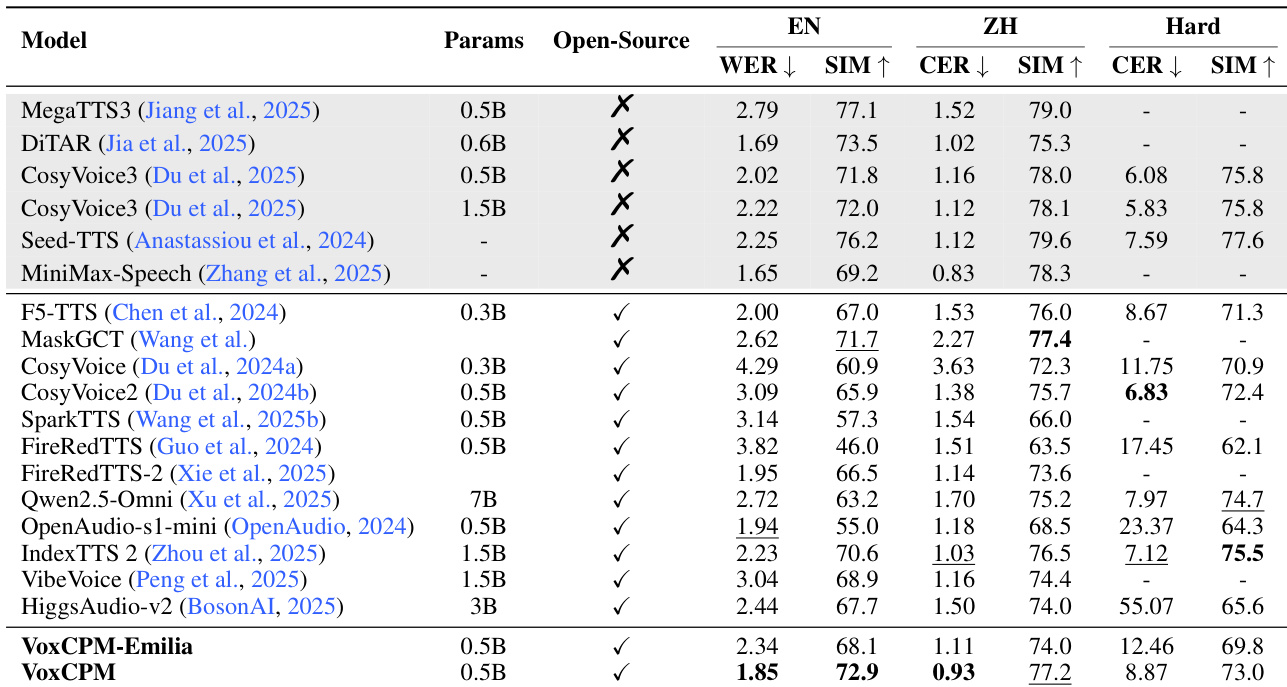
使用英文和中文基准测试,将 VoxCPM 及其 Emilia 变体与几种最先进的开源和闭源 TTS 模型进行了比较。结果显示,VoxCPM 在标准和挑战性测试集中,在可懂度和说话人相似度方面均取得了具有竞争力的性能。与大多数列出的开源模型相比,VoxCPM 展示了卓越的英文可懂度和说话人相似度。在具有挑战性的 Hard 测试集中,VoxCPM 在中文字符错误率和说话人相似度方面均保持了高性能。尽管 VoxCPM-Emilia 变体是在较小的数据集上训练的,但仍显示出具有竞争力的结果,表明了架构的鲁棒性。
使用专注于表现力和自然场景性能的 CV3-EVAL 基准测试,将 VoxCPM 与几种最先进的 TTS 模型进行了对比。结果表明,与大多数基准模型相比,VoxCPM 在中英文基准测试的可懂度方面均实现了更优的性能。在标准的 CV3-EVAL 基准测试中,VoxCPM 在中英文方面均实现了最低的错误率。在更具挑战性的 CV3-Hard-EN 子集中,VoxCPM 在词错误率方面优于几种具有竞争力的模型。虽然 VoxCPM 显示出强大的可懂度,但其他模型(如 CosyVoice3 变体)表现出更高的说话人相似度得分。
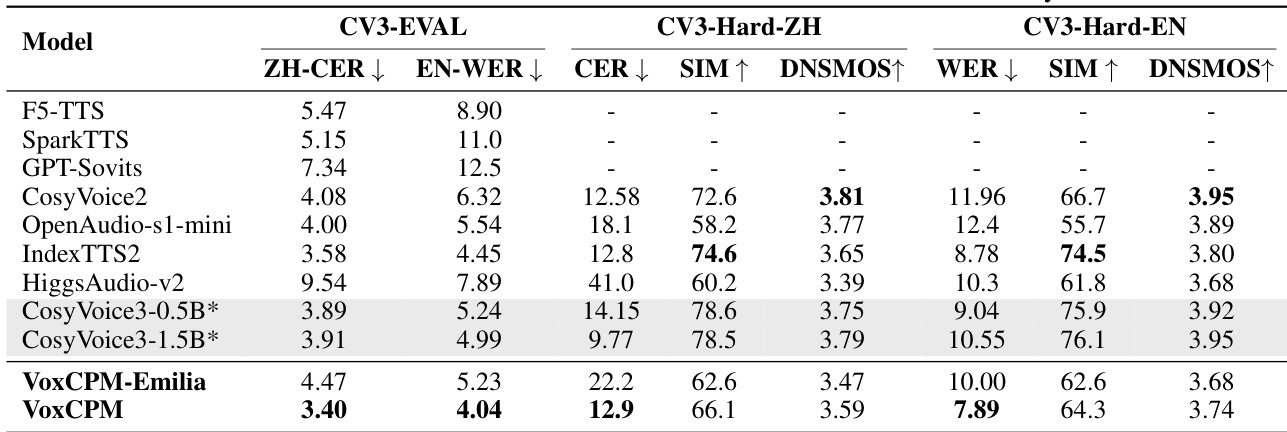
通过主观和客观评估,在英文和中文基准测试中将 VoxCPM 及其变体与各种最先进模型进行了比较。实验验证了 VoxCPM 即使在挑战性数据集上进行测试或使用更高效的 Emilia 变体时,也能实现卓越的说话人相似度和高可懂度。此外,结果表明,实施两阶段学习率衰减调度可以显著增强模型在所有测试语言中的鲁棒性和性能。