Command Palette
Search for a command to run...
小模型,大成果:通过分解实现卓越的意图抽取
小模型,大成果:通过分解实现卓越的意图抽取
Danielle Cohen Yoni Halpern Noam Kahlon Joel Oren Omri Berkovitch Sapir Caduri Ido Dagan Anatoly Efros
摘要
从用户界面交互轨迹中理解用户意图,仍是智能代理开发中一个极具挑战性 yet 至关重要的前沿课题。尽管大规模、基于数据中心的多模态大语言模型(MLLMs)具备更强的能力来处理此类序列的复杂性,但能够在本地设备上运行、提供隐私保护、低成本且低延迟用户体验的小型模型,在准确推断用户意图方面仍面临困难。为解决这一局限,我们提出一种新颖的分解式方法:首先,对交互过程进行结构化摘要,从每一次用户操作中提取关键信息;其次,利用在聚合摘要基础上微调的模型进行意图提取。该方法显著提升了资源受限模型的意图理解能力,甚至在某些场景下超越了大型MLLMs的基础性能。
一句话总结
谷歌与巴伊兰大学的研究人员提出了一种分解式方法——先进行结构化摘要,再提取意图——使小型本地设备模型在从用户界面轨迹推断用户意图方面超越大型多模态大语言模型,从而提升隐私性、成本效益和延迟表现,适用于智能代理场景。
主要贡献
- 我们引入了一种两阶段分解方法,从用户界面轨迹中提取用户意图:首先结构化地摘要每个交互,然后聚合摘要以预测意图,使小型本地设备模型即使在资源受限的情况下也能超越大型多模态大语言模型。
- 我们的方法在摘要阶段同时利用视觉屏幕上下文和动作字符串,在意图提取阶段采用微调模型,对噪声数据具有鲁棒性,并支持工程评估与迭代改进的模块化设计。
- 在公开的用户界面自动化数据集上使用语义等价性指标评估,我们的方法在多种模型架构和输入表示下持续优于基线大型多模态大语言模型和小型模型,验证了其通用性和有效性。
引言
作者利用两阶段分解方法,借助小型本地设备模型提升从用户界面交互序列中提取意图的能力——这对于移动助手等注重隐私、成本和延迟的应用至关重要。以往工作要么依赖无法本地运行的大型多模态大语言模型,要么使用粗略提示或微调,但难以应对上下文长度和噪声数据问题。他们的方法首先将每个交互结构化地摘要为屏幕感知的片段,再聚合生成意图——在语义指标上超越小型模型和大型多模态大语言模型,同时处理噪声输入并支持模块化工程实现。
数据集

作者使用两个用户界面交互数据集——Mind2Web 和 AndroidControl——训练和评估意图提取模型。以下是其组成、处理和应用方式:
-
数据集来源与组成
- Mind2Web(CC BY 4.0):涵盖 2,350 条人类轨迹,平均每条 7.3 步。每条轨迹包含截图、动作和高层任务描述。包含验证步骤以对齐轨迹与意图,从而获得更干净的标签。
- AndroidControl(Apache 2.0):涵盖 15,283 条人类轨迹,平均每条 5.5 步。包含截图、动作和目标描述。缺少验证步骤,导致标签噪声较大(例如“删除来自 X 的邮件”,但实际不存在此类邮件)。
-
关键子集细节
- Mind2Web:训练/测试集划分遵循原始设置;由于谷歌政策按领域过滤,测试集从 1005 例减少至 681 例用于 Gemini 实验。
- AndroidControl:无领域过滤;标签通过 Gemini 1.5 Pro 提示清理以移除无关信息(如“我饿了,点披萨”),但约 30% 仍需人工修正。
-
处理与元数据构建
- 截图:Mind2Web 截图围绕交互边界框裁剪至 1280×768 像素并添加随机边距,再缩放;AndroidControl 直接缩放至 1080×2400 像素并叠加红色边界框。
- 动作:Mind2Web 动作直接使用(如“[元素] 点击”);AndroidControl 动作通过无障碍树映射为元素名称。
- 目标标签:平台特定名称(如应用/网站名)通过“应用名;意图”格式与核心意图分离,以防止评估偏差。标签清理以移除不可推断的细节。
-
模型使用
- 模型在训练集上微调;测试结果在原始测试集上报告。
- 对于 Qwen2 VL 7B:轨迹限制为 15 步;AndroidControl 图像缩小 4 倍。
- Gemini 1.5 Pro 用于标签清理;Gemini 1.5 Flash 8B 和 Qwen2 VL 7B 用作可微调基线。
-
注明的局限性
- 数据集偏向英语、美国中心化交互;缺乏多应用或自适应目标行为。Mind2Web 限于单一网站;AndroidControl 缺乏实时目标演进。通用性仅限于网页/Android 平台。
方法
作者采用分解式两阶段模型,以解决链式思维(CoT)提示和微调小型语言模型在处理完整用户轨迹时的局限性。该方法模拟 CoT 过程:首先生成交互级摘要,再聚合为会话级意图。整体框架如下图所示,第一阶段使用基于提示的方法处理单个交互,第二阶段通过微调将摘要合成为连贯的整体意图。

在第一阶段,模型对轨迹 T=(I1,…,In) 中的每个用户交互 Ii={Oi,Ai} 进行摘要,同时利用视觉和文本信息提取相关上下文和动作。摘要过程完全基于提示,因为不存在交互级摘要的标注训练数据。为增强模型解决歧义的能力,输入不仅包含当前交互 Ii,还包括前一个和后一个交互 Ii−1 和 Ii+1。这种扩展上下文使模型能通过相邻截图的视觉线索更好地解释用户动作。该阶段输出为结构化摘要,包含两个部分:(a) 当前屏幕 Oi 的显著细节列表,(b) 用户执行的中层动作列表。此外,还包含一个标记为“推测意图”的第三字段,用于捕捉模型对用户潜在目标的解释,该字段将在下一阶段被丢弃。这种结构化格式缓解了替代提示策略的问题(如摘要过于简短或过度推测),从而提升后续聚合阶段的输入质量。
在第二阶段,模型聚合交互级摘要以推断用户的整体意图。该阶段通过微调实现,输入为轨迹中所有交互的摘要,目标为对应的真实意图描述。训练数据构建时,目标意图经过精炼以排除摘要中未包含的细节,确保模型仅从提供信息中推断意图。该精炼过程使用大型语言模型完成,详见下图提示。微调模型旨在避免添加或虚构细节,从而生成更准确、更贴合实际的意图描述。作为消融研究的一部分,也评估了完全基于提示的变体(不涉及微调)。
实验
- 使用 BiFact(事实级比较)和 T5 NLI(整体蕴含)评估意图提取,发现 BiFact 更适合多组件意图。
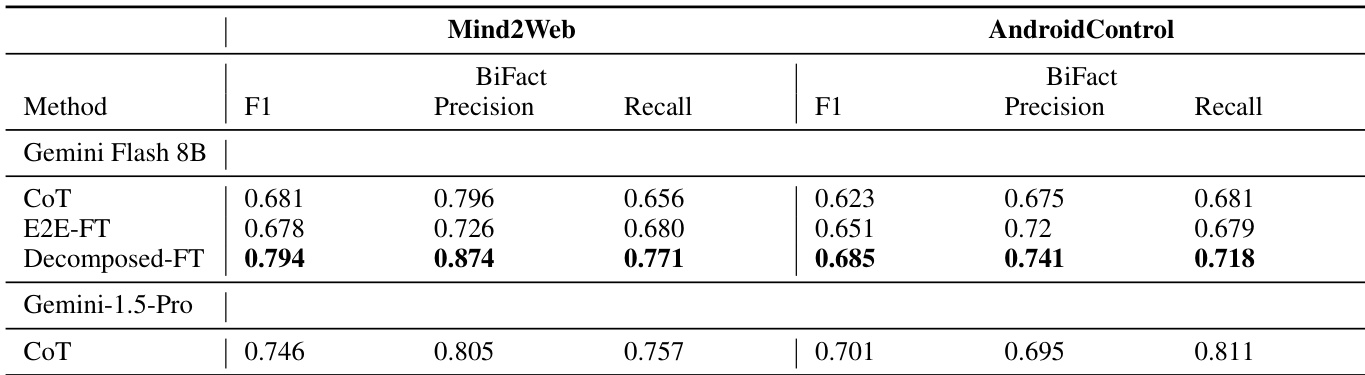
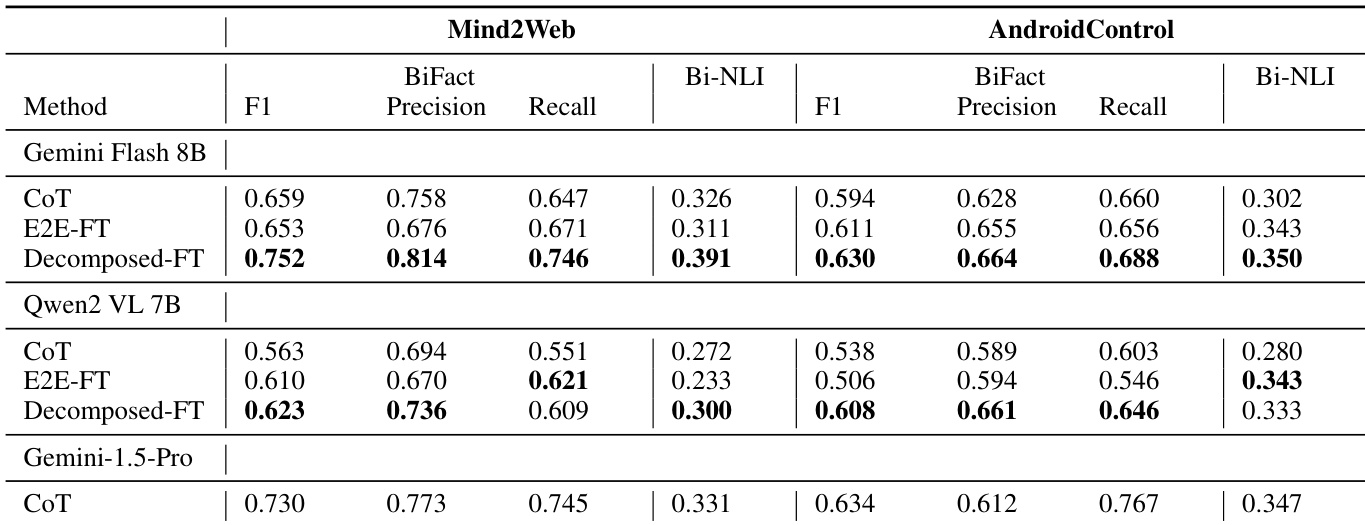
- 在 Mind2Web 上,经分解微调的 Gemini Flash 8B 优于使用 CoT 的 Gemini 1.5 Pro(BiFact F1);在 AndroidControl 上,各模型表现相当。
- 人工评估者在 20 个 Mind2Web 案例中有 12 个更偏好分解微调,证实其定性优势。
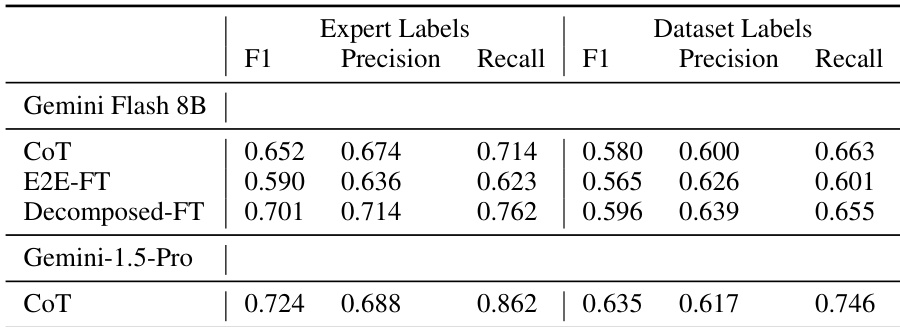
- 专家标注揭示数据集标签噪声;分解微调在专家标签上表现提升,而端到端微调(E2E-FT)因训练数据噪声而表现下降。
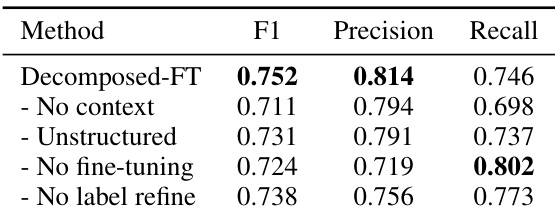
- 消融研究显示关键贡献:相邻交互上下文(↑ 召回率)、结构化摘要(↑ 精确率/召回率)、微调(↑ 精确率)和标签精炼(↑ 精确率)。
- 错误分析识别出主要失败点:交互摘要遗漏、虚构、屏幕误读,以及意图提取遗漏。
- 错误传播分析:每个阶段(摘要、意图提取)导致约 16–18% 召回率损失;因标签精炼,虚构错误率较低(8%)。
- 分解微调成本为小型模型基线的 2–3 倍,但仍低于大型模型(如 Gemini 1.5 Pro);延迟优化变体避免额外调用且无质量损失。
- 分解微调在未见领域、任务和网站上泛化性优于 CoT 或 E2E-FT,多数泛化类别中甚至超越 Gemini 1.5 Pro CoT。
- 结果在不同评估大语言模型(Gemini Pro 与 Flash 用于 BiFact)下稳健,确认结论有效性。
作者使用 BiFact 和 Bi-NLI 指标评估 Mind2Web 和 AndroidControl 数据集上的意图提取性能。结果显示,分解微调(Decomposed-FT)方法在两个数据集上均获得最高的 BiFact F1 和召回率,优于 CoT 和 E2E-FT 基线,其中 Mind2Web 上表现最佳。
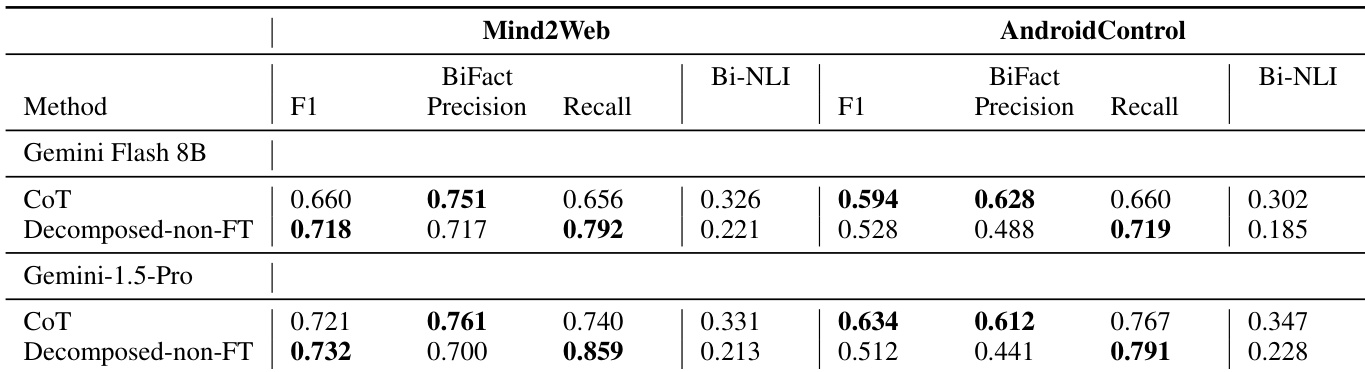
作者使用 BiFact 和 Bi-NLI 指标评估 Mind2Web 和 AndroidControl 数据集上的意图提取性能。结果显示,经微调的分解方法(Decomposed-FT)优于 CoT 和非微调变体,在所有模型和数据集上均获得更高的 F1 和召回率,其中 Gemini Flash 8B 在 Mind2Web 上表现最佳,Gemini-1.5-Pro 在 AndroidControl 上表现突出。
作者使用专家标注和数据集标签作为真实值,在 AndroidControl 数据集上比较不同意图提取方法的性能。结果显示,当使用专家标签评估时,Decomposed-FT 模型的 BiFact F1 分数高于 CoT 和 E2E-FT,表明其与人工验证意图对齐更优;而使用噪声数据集标签时,性能差距较小。
作者在两个数据集上使用多种模型评估其分解式意图提取方法与基线的对比,结果显示 Decomposed-FT 方法在所有模型和数据集上均优于 CoT 和 E2E-FT,获得更高的 BiFact F1 和 Bi-NLI 分数。在 Mind2Web 上,经微调的 Gemini Flash 8B 分解方法优于使用 CoT 的更大 Gemini 1.5 Pro 模型;在 AndroidControl 上,各方法表现相当。
作者通过消融研究评估其分解式意图提取方法中关键设计选择的影响。结果显示,移除标签精炼会导致精确率显著下降,而移除微调会导致精确率明显降低并略微提升召回率,表明这两个组件对平衡性能至关重要。