Command Palette
Search for a command to run...
PromptEnhancer:通过思维链提示重写提升文本到图像模型的简单方法
PromptEnhancer:通过思维链提示重写提升文本到图像模型的简单方法
摘要
近年来,文本到图像(Text-to-Image, T2I)扩散模型在生成高保真图像方面展现出卓越能力。然而,这些模型在忠实呈现复杂用户提示方面仍面临显著挑战,尤其体现在属性绑定、否定表达以及组合关系的准确建模等方面,导致用户意图与生成结果之间存在显著偏差。为应对这一问题,我们提出 PromptEnhancer——一种新颖且通用的提示重写框架,可无需修改预训练T2I模型权重,即能有效提升其性能。与以往依赖模型特定微调或隐式奖励信号(如图像奖励分数)的方法不同,本框架将提示重写器与生成器解耦。我们通过强化学习训练一个思维链(Chain-of-Thought, CoT)式重写器,并由一个专为该任务设计的奖励模型——AlignEvaluator进行指导。AlignEvaluator基于对T2I模型常见失败模式的系统性分析,构建了包含24个关键评估维度的分类体系,能够提供明确且细粒度的反馈。通过优化CoT重写器以最大化AlignEvaluator所给出的奖励,本框架能够学习生成更易被T2I模型准确理解的提示。在HunyuanImage 2.1模型上的大量实验表明,PromptEnhancer在多种语义与组合性挑战下均显著提升了图像与文本的一致性。此外,我们还构建了一个高质量、基于人工偏好的新基准数据集,以推动该方向的后续研究。
一句话总结
作者提出 PromptEnhancer,这是腾讯混元开发的一种通用提示重写框架,通过强化学习结合细粒度 AlignEvaluator 奖励模型,将思维链(Chain-of-Thought)重写器与预训练模型解耦,为 24 种失败模式提供明确反馈,从而提升属性绑定、否定和组合准确性,显著增强 HunyuanImage 2.1 上的对齐效果,使复杂用户提示得到更忠实的解析。
主要贡献
- 许多文本到图像扩散模型因属性绑定、否定和组合关系等问题,无法准确理解复杂用户提示,导致用户意图与生成结果之间存在显著差距。
- PromptEnhancer 引入了一种通用的、与模型无关的提示重写框架,通过强化学习训练思维链重写器,使其与图像生成解耦;该过程由一种新颖的 AlignEvaluator 奖励模型引导。
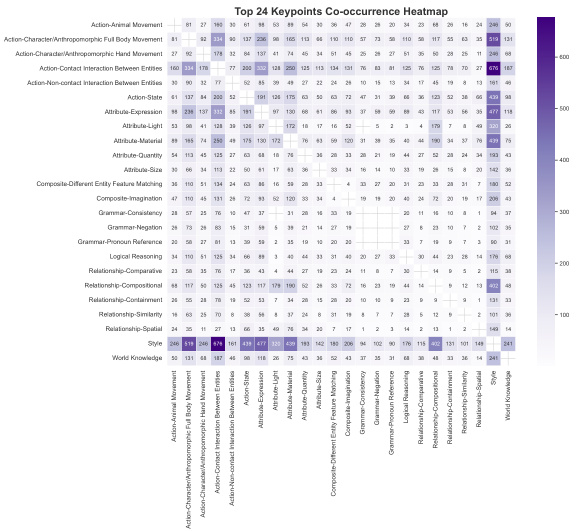
- AlignEvaluator 在 24 个关键点上提供细粒度反馈,按六类组织,实现与人类意图的精准对齐;在 HunyuanImage 2.1 上的实验表明,图像-文本对齐性能显著提升,并得到一个高质量的人类偏好基准的支持。
引言
文本到图像扩散模型已实现令人印象深刻的逼真度和多样性,但常无法准确解析复杂用户提示——在属性绑定、否定和组合关系方面表现不佳,导致用户意图与生成结果之间持续存在差距。以往的提示重写方法受限于对特定模型微调的依赖,或使用 CLIP 分数等粗粒度、隐式奖励,缺乏纠正细微错误的精度,且难以在不同模型间适配。作者提出 PromptEnhancer,一种通用的、与模型无关的框架,将提示重写与图像生成解耦。该框架采用基于强化学习训练的思维链重写器,由一种名为 AlignEvaluator 的新型奖励模型引导,该模型在 24 个具体维度上提供细粒度的图像-文本对齐反馈。这使得重写器能够系统性地增强提示,加入显式、结构化的细节,显著提升跨多种领域的保真度和组合准确性,而无需修改底层 T2I 模型。
数据集
- 数据集通过多阶段筛选流程构建,以支持监督微调(SFT)和基于强化学习的策略对齐。
- SFT 数据集包含 485,119 个高质量(用户提示,思维链,重写提示)三元组,源自 326 万张图像池——其中 153 万张为中文导向,173 万张为英文导向。
- 用户提示通过图像描述模型模拟生成,产生 226 万条代理提示,反映自然、简洁的用户查询。
- 针对每个提示,Gemini-2.5-Pro 生成详细的思维链推理路径和多个重写候选,支持多样化的重写探索。
- 采用 Gemini-2.5-Pro 进行自动化过滤,剔除语义偏差、信息丢失或逻辑不一致的样本,将数据集从 100 万缩减至 611,921 个三元组。
- 通过人机协作筛选流程,利用 Hunyuan 文本到图像模型生成对应图像,专业标注员评估重写候选,选择最符合意图且视觉质量最高的版本。
- 最终 SFT 数据集的主题分布为:设计(27%)、艺术(23%)、电影与故事(22%)、插画(18%)和创意任务(10%),详细子类别分布见图 4。
- 对于策略对齐,使用相同图像模拟方法构建约 5 万个独立提示,但来自不重叠的图像池,以防止数据泄露。
- 该 RL 提示集不包含真实思维链或重写提示;相反,AlignEvaluator 在训练过程中提供动态反馈,指导策略优化。
- RL 提示集的主题分布与 SFT 数据保持一致,以确保训练动态稳定。
- 一个补充评估基准 T2I-Keypoints-Align 包含 6,687 个提示——44.9% 为英文,55.1% 为中文——每个提示均标注细粒度语义关键点(如动作、属性、关系),用于模型的精细化评估。
- 中文提示更简洁(平均约 100 字符),关键点密度更高(峰值达每提示 4 个关键点),而英文提示在长度和结构上变化更大。
- 该基准支持在 24 个细粒度关键点和六个超类别上的细粒度评估,性能可视化见图 5 和图 8。
方法
作者采用两阶段训练框架构建 PromptEnhancer,这是一种旨在提升预训练文本到图像(T2I)模型性能的通用提示重写系统,且无需修改其权重。该框架的核心由一个基于大视觉-语言模型的策略模型——思维链重写器(CoT Rewriter),以及一种名为 AlignEvaluator 的专用奖励模型组成。主要目标是训练 CoT Rewriter,将用户的初始提示转化为更详细、结构化的指令,使其更贴合用户意图,从而提升生成图像的质量。

如图所示,该框架分为两个阶段。第一阶段为监督微调(SFT),用于初始化 CoT Rewriter。该阶段使用(用户提示,重写提示)对数据集,其中重写提示是原始提示的详细、思维链(CoT)增强版本。该数据集通过蒸馏强大专有大模型(如 Gemini-2.5-Pro 或 DeepSeekV3)的知识生成,该模型作为“教师”分析提示元素、识别歧义,并合成全面、结构化的指令。CoT Rewriter 在此数据集上使用标准的下一个词预测损失进行微调,学习生成期望的 CoT 格式,为后续精炼阶段建立坚实基础。
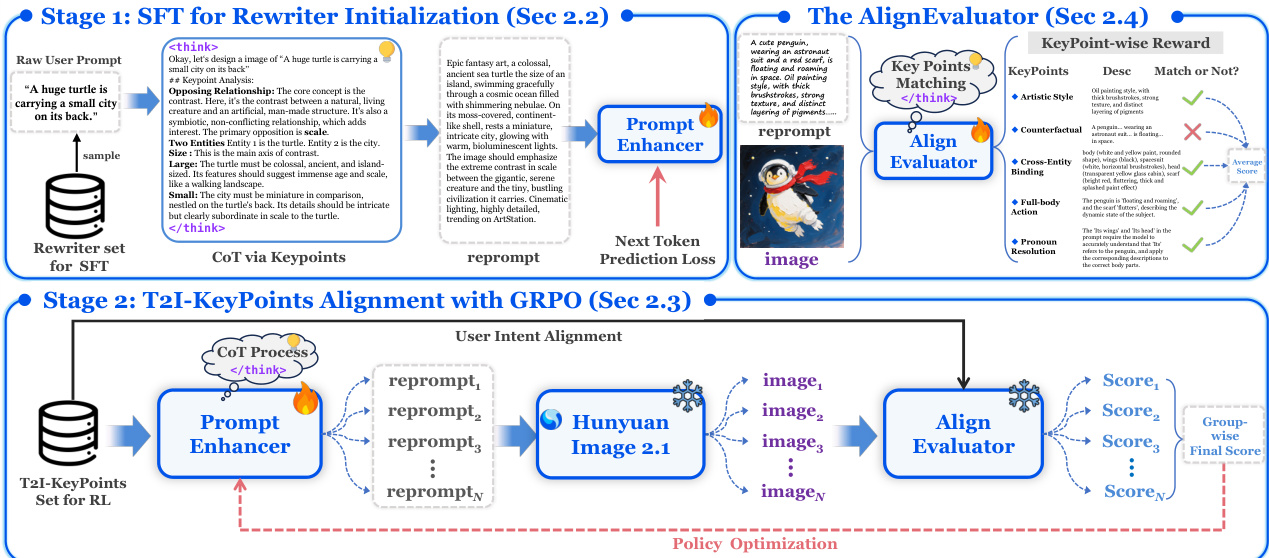
第二阶段为策略对齐,使用强化学习进一步优化初始化的重写器。该阶段采用分组相对策略优化(GRPO),使重写器输出与 AlignEvaluator 捕获的细粒度偏好对齐。该过程为迭代式:针对给定用户提示,CoT Rewriter 生成多个候选重写提示。每个候选提示输入冻结的 T2I 模型(如 Hunyuan Image 2.1)生成对应图像。预训练的 AlignEvaluator 随后评估每个(图像,用户提示)对,并基于 24 个细粒度关键点的分类体系提供标量奖励,这些关键点分为六类。类别包括艺术风格、反事实、跨实体绑定等,详见附带热力图。奖励用于更新重写器的策略,形成偏好排序,鼓励生成带来更高奖励的提示,从而优化用户意图与最终图像输出之间的对齐。AlignEvaluator 在此过程中起核心作用,提供稳健且细致的奖励信号,引导重写器策略优化。
实验
- PromptEnhancer 显著提升文本到图像模型对复杂提示的遵循能力,通过生成丰富、详细的提示,增强视觉保真度和风格准确性,定性对比结果见图 6。
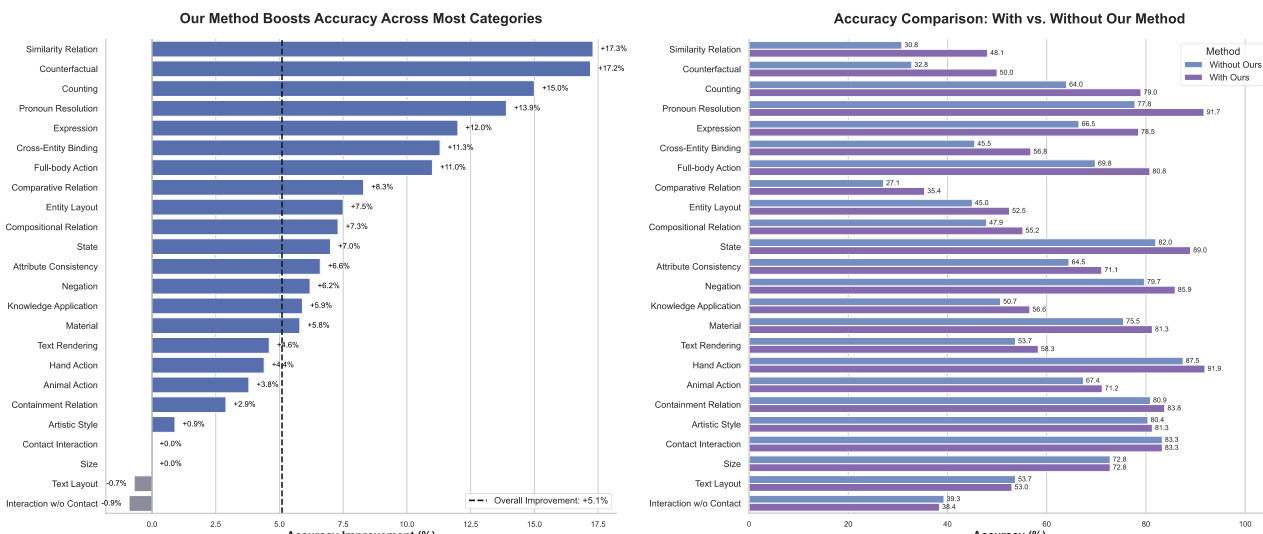
- 在所提出的基准上,PromptEnhancer 在 24 个语义类别中平均提升 +5.1% 的提示遵循准确率,其中 20 个类别表现提升。
- 显著改进包括:相似关系 +17.3%、反事实推理 +17.2%、计数 +15.0%、代词消解 +13.9%、面部表情 +12.0%、跨实体绑定 +11.3%。
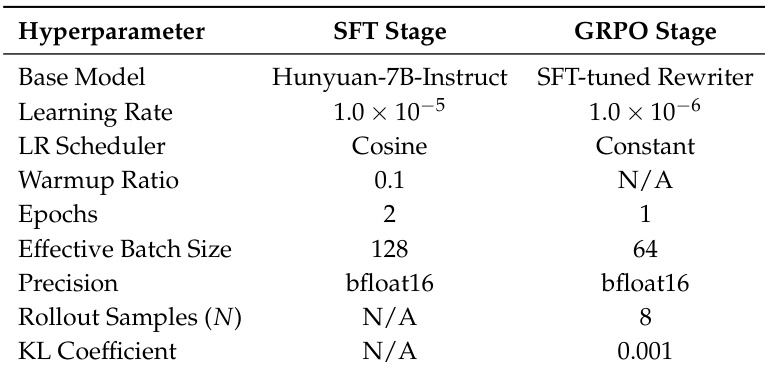
- 该框架在 HunyuanImage 2.1 上以即插即用设计进行评估,采用监督微调与基于 GRPO 的策略对齐,在 8 块 H800 GPU 上训练,使用 bfloat16 混合精度。
- 在文本布局(-0.7%)和无接触交互(-0.9%)方面出现轻微退化,但整体收益显著,证实该方法的鲁棒性与有效性。
作者使用 PromptEnhancer 提升文本到图像模型对复杂提示的遵循能力,在 24 个语义类别上评估其影响。结果表明,PromptEnhancer 显著提升准确率,所有类别平均提升 +5.1%,尤其在相似关系、反事实推理和计数等复杂推理任务中表现突出。
作者以 Hunyuan-7B-Instruct 模型作为 SFT 阶段的基础模型,使用学习率 1.0×10−5、余弦调度器、0.1 的预热比例,在 2 个周期内进行微调,采用 bfloat16 精度实现有效批量大小 128。在 GRPO 阶段,对 SFT 微调后的重写器进一步优化,使用降低的学习率 1.0×10−6、恒定调度器、1 个周期,采用 8 次 rollout 样本和 0.001 的 KL 系数以稳定策略更新。
作者使用 PromptEnhancer 框架提升文本到图像模型对复杂提示的遵循能力,在 24 个语义类别上评估其影响。结果表明,PromptEnhancer 显著提升提示遵循准确率,所有类别平均提升 +5.1%,在相似关系、反事实推理和计数等复杂推理任务中取得显著进步。
作者使用 PromptEnhancer 框架提升文本到图像模型对复杂提示的遵循能力,在包含 24 个语义类别的基准上评估其性能。结果表明,PromptEnhancer 显著提升提示遵循准确率,所有类别平均性能提升 5.1%,在相似关系、反事实推理和计数等复杂推理任务中取得显著进步。