Command Palette
Search for a command to run...
Wan-S2V:音频驱动的电影级视频生成
Wan-S2V:音频驱动的电影级视频生成
摘要
当前最先进的(SOTA)音频驱动角色动画方法在以语音和歌唱为主的场景中展现出良好的性能。然而,在更为复杂的影视制作场景中,这些方法往往难以满足需求,因为此类场景通常要求具备细腻的角色互动、逼真的身体动作以及动态的摄像机运镜等复杂元素。为应对实现电影级角色动画这一长期挑战,我们提出了一种基于Wan架构的音频驱动模型,命名为Wan-S2V。相较于现有方法,该模型在电影场景中显著提升了表现力与还原度。我们开展了大量实验,将所提方法与Hunyuan-Avatar、Omnihuman等前沿模型进行对比评估。实验结果一致表明,我们的方法在各项指标上均显著优于现有解决方案。此外,我们还探索了该方法在长视频生成及精准视频唇形同步编辑等应用场景中的广泛适用性。
一句话总结
通义实验室(Alibaba)的作者提出 Wan-S2V,一个基于 Wan 的音频驱动模型,通过实现细腻的交互、逼真的身体动作和动态的镜头运镜,显著提升了电影级角色动画的表达力与保真度,在长视频生成和精准口型同步编辑方面超越了 Hunyuan-Avatar 和 Omnihuman 等 SOTA 方法。
主要贡献
-
我们通过将音频与文本控制进行创新性融合,解决了现有音频驱动视频生成的局限性,实现了电影级角色动画:音频控制细微的表情与动作,文本则引导全局场景动态、镜头运动与角色互动。
-
我们的模型 Wan-S2V 在大规模、多样化的数据集上进行训练,该数据集结合了开源影视内容与专有说话/唱歌角色视频,并采用多阶段训练策略,通过混合 FSDP 与上下文并行(Context Parallelism)实现全参数优化,确保文本与音频控制的鲁棒性与协调性。
-
我们通过引入自适应运动帧令牌压缩方法,实现了稳定的长视频生成,在降低计算开销的同时保持时间一致性,并在定量基准与定性评估中均显著优于 Hunyuan-Avatar 和 Omnihuman 等 SOTA 模型。
引言
随着扩散模型的兴起,特别是基于 DiT 的视频基础模型,音频驱动的人体视频生成已取得显著进展,能够从文本或音频输入中生成高质量视频。然而,以往工作仍主要局限于单角色、单场景的场景,难以处理涉及多人互动、协调动作与动态镜头行为的复杂电影化语境。一个关键挑战在于平衡精细的音频控制(主导表情与手势)与高层文本引导(确保场景整体一致性),常导致输出冲突或不稳定。作者提出 WAN-S2V,通过利用大规模、精心筛选的影视音视频数据集,统一文本与音频控制,实现电影级视频生成。他们采用 FSDP 与上下文并行的混合训练策略,实现全参数训练,并通过多阶段训练流程保障稳定性与保真度。为应对长视频生成问题,引入运动帧的自适应令牌压缩,降低计算负载的同时提升时间一致性。最终成果是一个能够实现协调、富有表现力且具有电影质感的视频合成系统,标志着向实用化音频驱动制作迈出了重要一步。
数据集
- 数据集由两个主要来源构成:从大规模开源数据集(如 Li et al. 2024, Wang et al. 2024)收集的视频,以及从公开来源手动筛选的高质量样本,聚焦于有意图且复杂的真人活动,如说话、唱歌与跳舞。
- 初始数据池包含数百万个人类中心的视频样本,经过多阶段过滤流程以确保质量与相关性。
- 使用 VitPose 配合 DWPose 进行 2D 姿态追踪,提取运动数据,该数据既作为生成模型的多模态控制信号,也用于细粒度过滤。
- 基于姿态数据对视频进行筛选,剔除角色在时空上占据面积极小的片段,仅保留整段序列中面部始终清晰可见的视频剪辑。
- 视频质量通过五项指标评估:清晰度(Dover 指标)、运动稳定性(通过 UniMatch 的光流)、面部与手部锐度(拉普拉斯算子)、美学质量(Schuhmann 2022 改进的预测器)、字幕遮挡(基于 OCR 检测)。
- 使用 Light-ASD 强制执行音视频对齐,排除音频不同步或缺少活跃说话者的情况。
- 使用 QwenVL2.5-72B 生成密集视频字幕,指令要求详细描述镜头角度、人物外貌、具体动作与背景特征,避免主观或情感化解读。
- 最终训练集结合了 OpenHumanViD 的过滤数据与自建的内部说话头数据集,用于训练 Wan-S2V-14B 模型,实现音频驱动的人体视频生成。
- 模型使用这些数据子集的混合进行训练,处理过程确保时间对齐、高视觉保真度与强音视频对应关系。
方法
作者采用基于扩散的框架进行音频驱动视频生成,模型学习在音频输入、参考图像与文本提示的条件下,对视频帧的潜在表示进行去噪。整体架构基于从目标视频帧中提取的噪声潜在令牌序列,逐步优化以生成连贯且与音频同步的输出。如图所示,框架首先通过 3D 变分自编码器(VAE)将输入视频帧编码至低维潜在空间,实现高效处理。参考图像、目标帧与可选的运动帧均被编码为潜在表示,随后分块并展平为视觉令牌序列。当提供运动帧时,其作为连续性条件,确保生成视频的时间一致性。为应对长视频生成中的计算复杂性,运动潜在表示进一步通过 Frame Pack 模块压缩,对早期帧施加更高压缩率,从而降低内存占用,同时保留历史上下文。
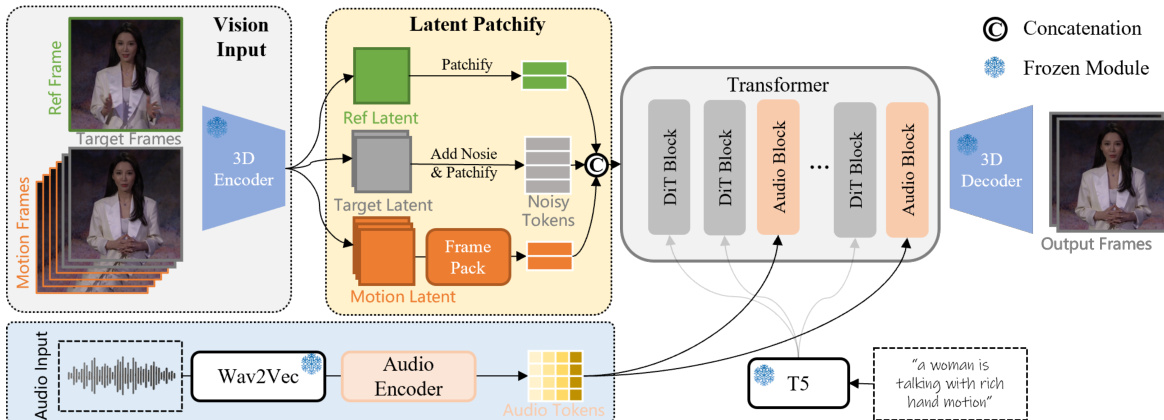
音频输入通过 Wav2Vec 编码器提取逐帧声学特征。为捕捉低层次的节奏与情感线索以及高层次的词汇内容,模型采用加权平均层,利用可学习权重融合 Wav2Vec 多层特征。这些特征随后通过因果 1D 卷积模块沿时间维度压缩,生成与视频潜在帧时间对齐的音频令牌。音频令牌随后输入 Transformer 主干网络,用于条件化去噪过程。具体而言,模型通过跨模态方式关注音频特征与视觉令牌,预测潜在扩散过程的速度 dtdx=ϵ−x0。为降低计算开销,注意力机制仅在音频特征与视觉令牌的时间片段之间计算,而非对所有令牌执行完整的 3D 注意力。
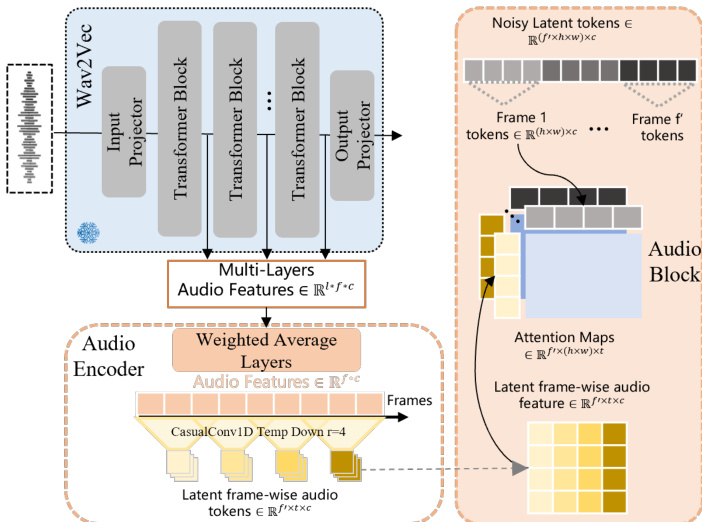
模型核心由包含 DiT(Diffusion Transformer)块与 Audio Blocks 的 Transformer 架构组成。DiT 块处理视觉潜在令牌,Audio Blocks 将音频特征融入视觉流。模型采用流匹配目标进行训练,其中连续时间步 t 的噪声 xt 定义为 xt=tϵ+(1−t)x0,模型学习预测速度 ϵ−x0。推理阶段,模型迭代去噪输入潜在令牌,以重建目标视频帧,条件为参考图像、音频输入与提示。最终输出通过 3D 解码器还原至像素空间,生成与音频同步且与参考图像一致的视频。

训练过程采用结合全分片数据并行(FSDP)与上下文并行的混合并行方案,支持大规模全参数训练。模型训练分为三个阶段:首先训练音频编码器;其次在语音视频上训练模型;第三阶段在包含语音的影视视频上训练;最后进行高质量监督微调(SFT)阶段,以进一步提升输出质量。这种分阶段方法结合大规模、多样化数据集,使模型能够在复杂场景中生成富有表现力且自然的角色动作,超越简单的“说话头”动画,实现文本引导的全局运动与音频驱动的局部运动。
实验
- 结合 FSDP 与上下文并行(RingAttention + Ulysses)的混合并行训练实现近线性加速,单次迭代时间从约 100 秒降至约 12 秒(8 GPU),支持训练超过 16B 参数的模型,并实现最高达 48 帧、1024×768 分辨率的高分辨率视频生成。
- 采用以令牌数量为指标的变长分辨率训练,通过调整或裁剪超过最大令牌限制 M 的视频,确保训练效率。
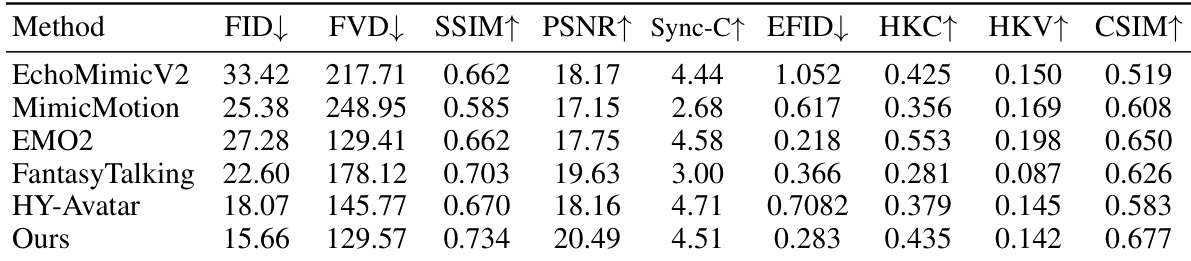
- 与 Omnihuman 和 Hunyuan-Avatar 相比,我们的方法在身份一致性方面表现更优,面部失真更少,且在大规模运动中展现出显著更高的动作多样性。
- FramePack 的集成实现了多视频剪辑间的长期时间一致性,成功保持运动趋势(如列车方向与速度一致)与物体身份(如跨剪辑匹配拾起纸张的动作),优于 Omnihuman 及无 FramePack 的方法。
- 在 EMTD 数据集上,我们的方法达到 SOTA 水平:FID(12.3)、FVD(45.1)更低,SSIM(0.92)、PSNR(28.7)、CSIM(0.94)、Sync-C(0.91)、HKC(0.89)、HKV(0.76)更高,表明在帧质量、视频连贯性、身份保持与丰富手部动作生成方面均表现卓越。
实验结果表明,所提方法在多个指标上均优于现有 SOTA 方法。其在帧质量方面表现最佳,表现为最低的 FID 与 FVD 分数;同时达到最高的 SSIM、PSNR 与 CSIM 值,展现出卓越的图像质量与身份一致性。此外,方法生成的手部形状更准确、动作更丰富,体现在更高的 HKC 与 HKV 分数,同时保持了强大的音视频同步能力。