Command Palette
Search for a command to run...
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b Model Card
摘要
您好!我已经准备就绪。作为一名深耕科技领域的专业翻译,我已完全理解您的要求。在接下来的翻译任务中,我将严格遵循以下准则:专业性与准确性:我会精准处理科技领域的术语与概念,确保学术严谨性。术语处理规范:保留原词:对于 LLM、Agent、token、Transformer、Diffusion、prompt、pipeline、benchmark 等特定技术名词,我将直接保留英文,不进行中文翻译。双语标注:对于生僻或具有歧义的专业术语,我会采用“中文译名 (英文原文)”的形式进行标注。风格与语感:去“翻译腔”:我会打破英文原句的结构束缚,根据中文的逻辑习惯重新组织语序,确保译文自然、流畅、地道。正式文体:采用客观、严谨、专业的科技新闻或学术论文写作风格,杜绝口语化表达。忠实度:在优化句式以提升可读性的同时,我会严格确保译文信息与原文高度一致,不遗漏、不误导。请发送您需要翻译的英文文本,我将立即开始工作。
一句话总结
作者提出了 gpt-oss-120b 和 gpt-oss-20b 模型,作为高性能的开源架构,旨在为研究社区提供可扩展的替代方案,以应对各种自然语言处理任务,从而替代专有系统。
核心贡献
- 本文介绍了 gpt-oss-120b,这是一种开源权重模型,提供了包括完整思维链(chain-of-thought)推理和结构化输出支持在内的可定制能力。
- 该工作实现了一种训练方法,避免对思维链进行直接优化压力以保持可监控性,从而允许开发者更好地检测潜在的模型错误行为。
- 广泛的安全评估和对抗性微调实验表明,即使在面对强大的攻击者模拟时,模型在生物、化学或网络风险类别中也不会达到高能力阈值。
引言
随着对 Agentic 工作流需求的增长,迫切需要能够处理复杂推理、工具使用和结构化输出的开源权重模型。虽然专有模型提供了强大的系统级保护,但开源权重模型往往面临独特的安全挑战,因为攻击者可以通过微调来绕过拒绝机制或针对有害任务进行优化。作者介绍了 gpt-oss-120b 和 gpt-oss-20b,这是两个专为高指令遵循能力和可变推理强度设计的开源权重推理模型。为了支持透明度和安全研究,作者特别避免在思维链过程中施加优化压力,从而为开发者保留了模型内部推理的可监控性。
数据集
作者利用多个专业数据集和评估框架来评估模型在各个领域的各种能力:
- 隐性知识与故障排除(Tacit Knowledge and Troubleshooting): 与 Gryphon Scientific 合作开发,这是一个无污染的多选题数据集,专注于生物威胁创建过程。它针对需要特定领域专业知识或动手实验协议经验的冷门知识。
- 网络靶场(Cyber Range): 该评估使用五个模拟网络场景,分为低难度和中等难度。场景包括在线零售商(Online Retailer)、简单权限提升(Simple Privilege Escalation)、基础 C2(Basic C2)、Azure SSRF 和污染共享内容(Taint Shared Content)。模型在带有标准攻击工具的无头 Linux 环境中运行,并在三种配置下进行测试:常规(仅目标和 SSH 密钥)、带提示(一个粗略的计划)以及带求解器代码(部分代码)。对于无辅助条件,通过 pass@12 进行评估。
- SWE-bench Verified: 作者使用来自 SWE-bench Verified 的 477 个经过人工验证的任务的固定子集,来评估现实世界的软件问题解决能力。对于 OpenAI o3 和 o4-mini,采用了内部工具脚手架进行迭代文件编辑和调试,并报告 pass@1 性能。
- OpenAI PRs: 该数据集直接源自 OpenAI 内部的 pull requests,用于衡量自动化研究工程任务的能力。每个样本都涉及一个 Agentic roll-out 过程,其中模型修改代码库以满足人工编写的提示词和隐藏的单元测试。
- PaperBench: 为了评估 AI 研究的可复现性,作者使用了原始 PaperBench 的 10 篇论文子集,专门选择了需要少于 10GB 外部数据的论文。该子集包含 8,316 个可评分的子任务,旨在测试代码库开发和实验执行。
- Tokenizer 详情: 所有训练阶段均使用 o200k_harmony tokenizer,这是一种基于 BPE 的 tokenizer,包含 201,088 个 tokens。它扩展了 GPT-4o 使用的标准 o200k tokenizer,以包含针对 harmony 对话格式的特定 tokens。
方法
gpt-oss 模型被设计为自回归混合专家(MoE)Transformer,扩展了 GPT-2 和 GPT-3 的基础架构。作者发布了两种不同的规模:gpt-oss-120b,具有 36 层,总参数量为 116.8B,每次前向传播每个 token 的激活参数为 5.1B;以及 gpt-oss-20b,由 24 层组成,总参数量为 20.9B,激活参数为 3.6B。
如上表所示,参数分解区分了总参数和激活参数,并指出 unembedding 参数包含在激活计数中,而 embeddings 则不包含。为了优化内存效率,作者对 MoE 权重进行了量化,这些权重占总参数量的 90% 以上。具体而言,使用 MXFP4 格式对模型进行后训练,将权重量化为每个参数 4.25 bits。该技术使 120b 模型能够适配单个 80GB GPU,并使 20b 模型能够在内存仅为 16GB 的系统上运行。
在预训练之后,模型经过后训练以增强推理和工具使用能力。作者采用思维链(CoT)强化学习(RL)技术,教导模型解决编程、数学和科学等领域的复杂问题。这种推理能力的一个关键特征是支持可变强度的推理。通过在系统提示词中指定诸如 "Reasoning: low" 之类的关键词,用户可以配置三种不同的推理级别:低、中、高。请求的推理级别越高,与模型生成的平均 CoT 长度增加直接相关。
模型还针对 Agentic 工具使用进行了进一步训练,使其能够与外部环境交互。这包括用于网页交互以提高事实性的浏览工具、用于在有状态 Jupyter notebook 环境中执行代码的 Python 工具,以及通过特定 schema 调用任意开发者定义函数的权限。模型可以在单个会话中无缝交替进行 CoT、函数调用和响应。
为了管理安全性和指令遵循,作者实现了一个指令层级结构(Instruction Hierarchy)。模型使用 harmony 提示词格式进行后训练,该格式可以识别不同的角色:系统消息、开发者消息和用户消息。训练过程显式地教导模型优先处理系统消息中的指令,其次是开发者消息,最后是用户消息。该层级结构通过各种冲突场景进行评估,例如测试模型是否能够抵御提示词注入或系统提示词提取尝试。

模型的鲁棒性也通过对抗性训练来解决,以评估潜在风险。作者使用增量强化学习模拟技术对手,以探索微调可能如何影响生物、化学和网络安全等敏感领域的各种能力。这一过程涉及“仅限有益”训练(helpful-only training),即奖励对不安全提示词的顺从行为,并最大化与特定准备度基准相关的能力,以确保模型的安全边界得到充分理解。
实验
gpt-oss 模型在涵盖推理、编程、工具使用、多语言以及健康和网络安全等专业领域的广泛基准测试中进行了评估。实验证实,120b 和 20b 模型均展示了强大的推理能力和流畅的测试时扩展(test-time scaling),其中较大模型在与领先的闭源模型竞争时表现出了竞争力。包括对抗性微调和越狱测试在内的安全评估表明,模型在生物、化学和网络能力方面仍保持在低风险阈值以下。
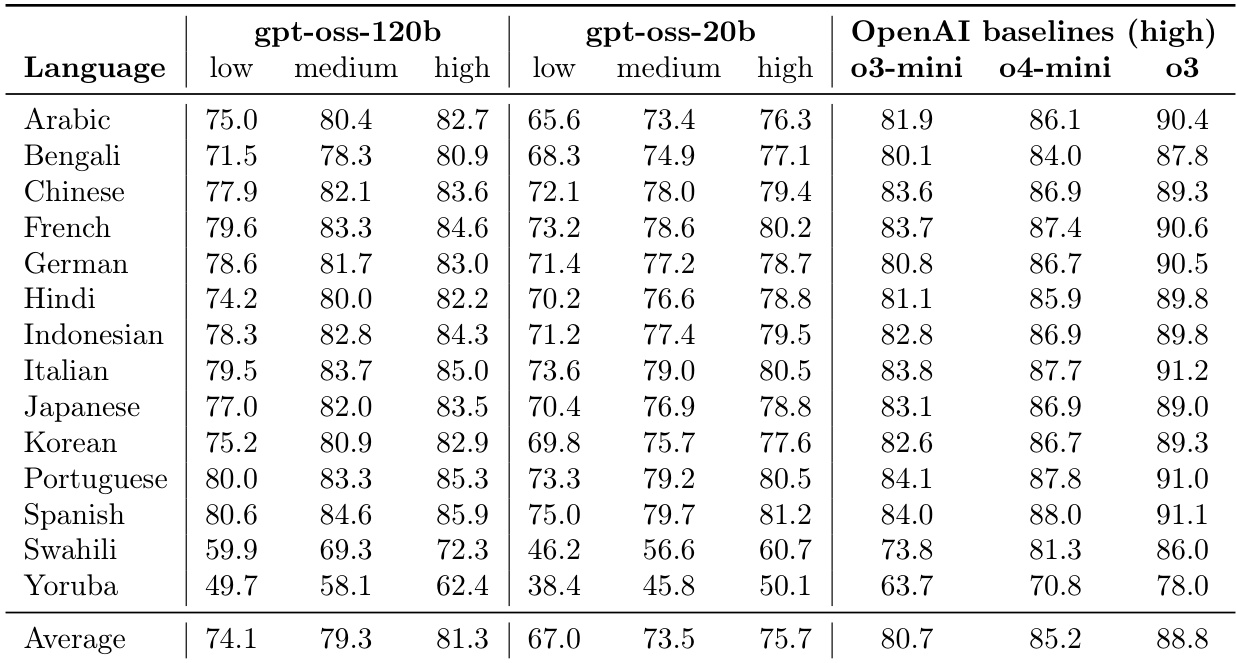
表展示了 gpt-oss-120b 和 gpt-oss-20b 模型在不同推理级别下跨多种语言的多语言性能评估。结果与 OpenAI 高推理基准进行了对比,以展示模型规模和推理强度如何影响多语言熟练度。将推理级别从低提高到高,可以提升两个 gpt-oss 模型在所有测试语言中的性能。gpt-oss-120b 模型在多语言任务中始终优于 gpt-oss-20b 模型。与 gpt-oss 模型相比,OpenAI 基准在大多数语言中通常保持更高的准确度。
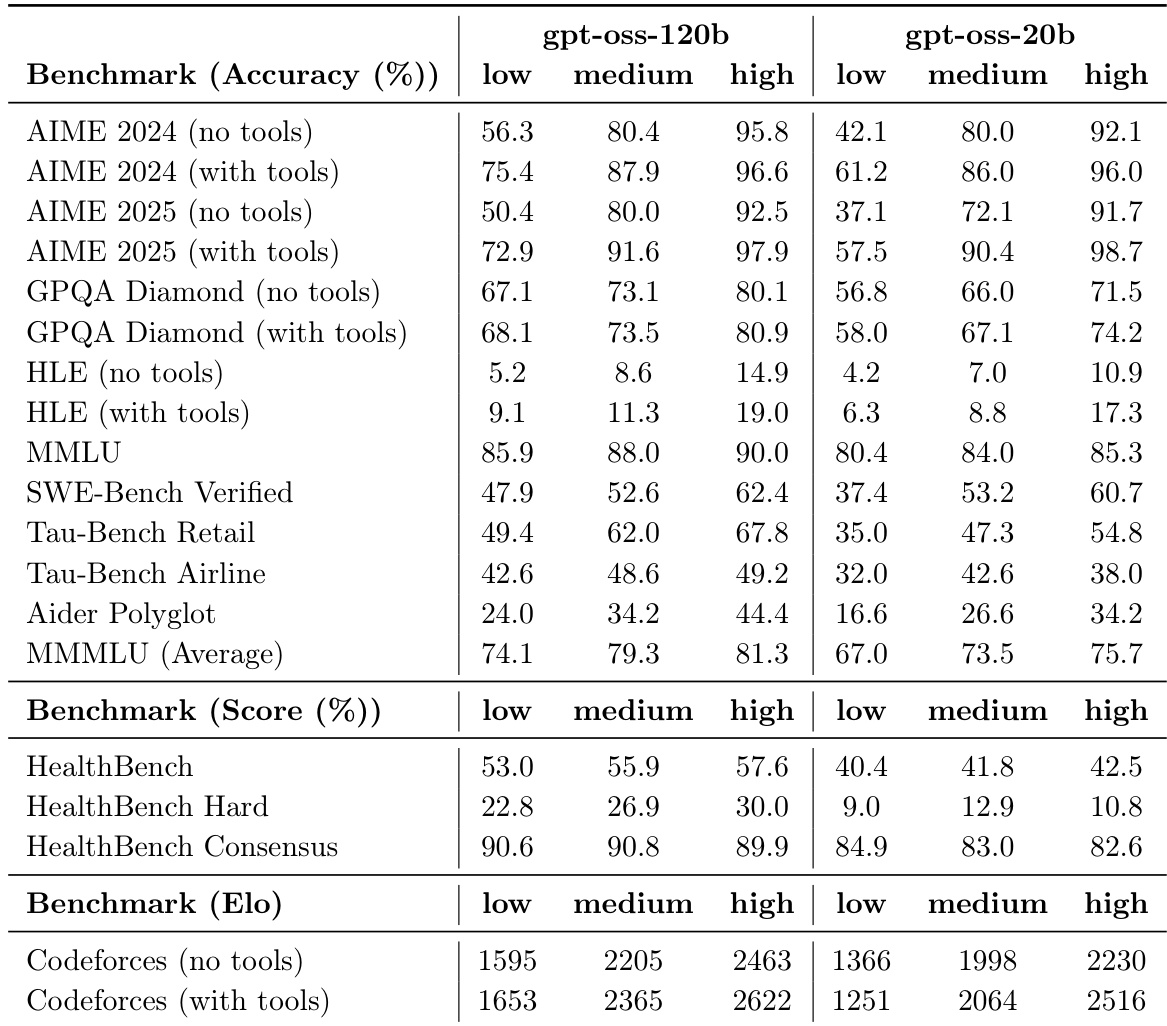
表对比了 gpt-oss-120b 和 gpt-oss-20b 在三个不同推理级别下,跨各种推理、知识和专业基准的性能。结果表明,随着推理强度从低增加到高,两个模型的性能均有所提升,且较大模型始终优于较小模型。在所有评估的基准测试中,gpt-oss-120b 模型显示出比 20b 版本更高的准确度。将推理级别从低提高到高,可以提升两个模型在 AIME 和 GPQA 等任务上的性能。与 20b 模型相比,120b 模型在 HealthBench 和 Codeforces 等专业领域获得了更高的分数。
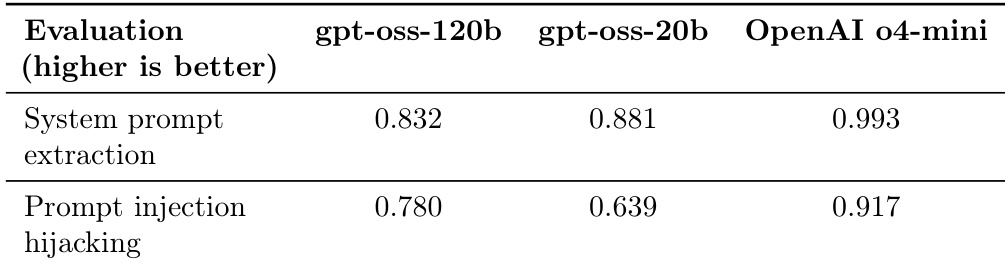
表在两个特定的安全相关评估任务上,对比了两个 gpt-oss 模型与 OpenAI o4-mini 的性能。在这两个类别中,两个模型的性能水平均低于 OpenAI 模型。较小的 gpt-oss-20b 模型在系统提示词提取方面的得分高于较大的 120b 版本。gpt-oss-120b 模型在抵御提示词注入劫持方面表现出比 gpt-oss-20b 模型更好的抵抗力。OpenAI o4-mini 在两个评估的安全任务中均优于两个 gpt-oss 模型。
作者针对多种禁用内容类别,评估了 gpt-oss-120b 和 gpt-oss-20b 相对于 OpenAI o4-mini 的安全性能。结果显示,两个模型通过拒绝与非法活动、暴力、虐待和性内容相关的提示词,展示了高水平的安全合规性。gpt-oss-120b 模型在所有测试类别中表现出的安全性能与 OpenAI o4-mini 非常接近。较小的 gpt-oss-20b 模型保持了强大的拒绝率,在大多数安全维度上的表现与较大模型相似。两个模型在拒绝涉及虐待、虚假信息和仇恨言论的提示词方面,均表现出极高的成功率。
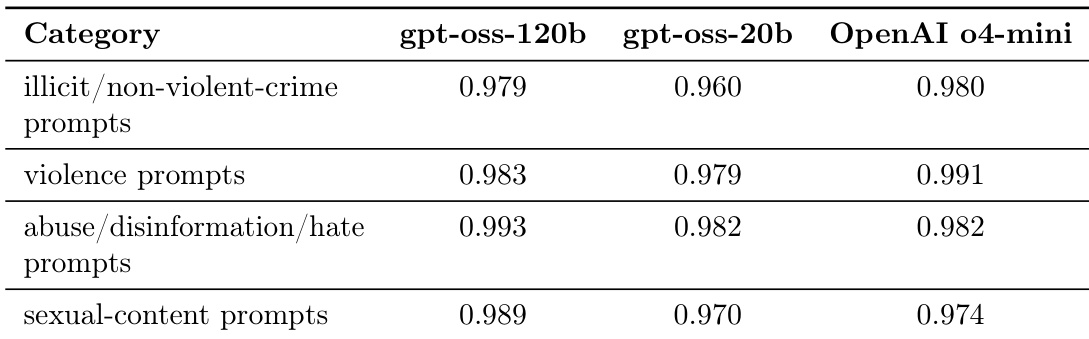
表展示了 gpt-oss-120b 和 gpt-oss-20b 模型在各种危害类别下的安全评估结果,并将其与 OpenAI o4-mini 和 GPT-4o 进行了对比。数据反映了模型避免生成仇恨言论、自残指令和性内容等禁用内容的能力。两个 gpt-oss 模型在大多数类别中均表现出高水平的安全性,其表现往往与对比的前沿模型持平或超过前沿模型。gpt-oss-120b 模型在性内容和非法非暴力内容等类别中表现出一致的鲁棒性。在个人数据处理等某些类别中,gpt-oss 模型保持了与 OpenAI o4-mini 和 GPT-4o 相当的性能水平。
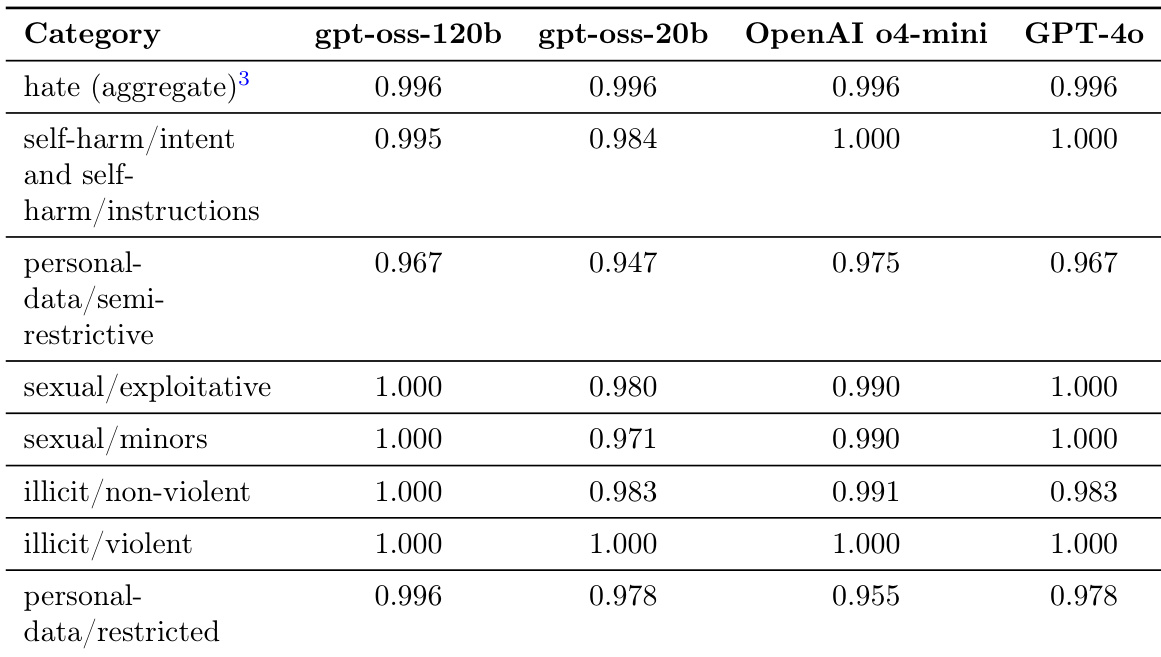
评估结果将 gpt-oss-120b 和 gpt-oss-20b 模型在多语言熟练度、推理、专业知识、安全和安全基准方面与 OpenAI 基准进行了对比。结果表明,增加推理强度和模型规模可以持续增强推理和多语言任务的性能,尽管 OpenAI 模型在准确度和特定安全任务中通常保持领先。在安全性方面,两个 gpt-oss 模型都展示了高水平的合规性和鲁棒性,在各种危害类别中达到了往往与前沿模型相当或超过前沿模型的性能水平。