Command Palette
Search for a command to run...
语言模型能否发现缩放定律?
语言模型能否发现缩放定律?
摘要
揭示可用于预测大规模模型性能的缩放定律,是一个基础性且开放性极强的挑战,目前主要依赖于缓慢且高度依赖具体案例的人工实验。为探究大语言模型(LLM)在自动化该过程中的潜力,我们从现有文献中收集了超过5000项实验,并精心构建了八个多样化的缩放定律发现任务。尽管现有智能体在生成准确的定律公式方面表现不佳,本文提出了一种基于进化机制的智能体——SLDAgent,该智能体能够协同优化缩放定律模型及其参数,从而实现对变量间复杂关系的自主探索。首次地,我们证明了SLDAgent能够在所有任务中自动发现的定律,其外推性能始终显著优于已有的、由人类总结的基准定律。通过全面的分析,我们阐明了这些发现定律为何更具优越性,并验证了其在预训练与微调应用中的实际价值。本研究建立了一种新型的智能体驱动科学发现范式,表明人工智能系统不仅能够理解自身的缩放行为,还能向科研社区回馈新颖且实用的知识。
一句话总结
来自北京大学、斯坦福大学、Wizard Quant 和清华大学的研究人员提出了 SLDAgent,这是一种基于进化的智能体,能够自主发现比人工推导更精确的缩放定律,从而实现更优的大语言模型预训练与微调外推,开创了 AI 驱动科学发现的新范式。
主要贡献
- SLDAgent 是一种基于进化的 LLM 智能体,通过协同优化符号表达式及其参数,自主发现缩放定律,克服了先前智能体在外推精度上无法匹敌人工成果的局限。
- 在 SLDBench —— 一个涵盖八个多样化任务、包含 5000 多项实验的精选测试平台 —— 上评估,SLDAgent 持续优于人类专家与基线智能体,在未见测试集上获得更高的 R² 分数,且无需依赖学习到的奖励模型。
- 所发现的定律在预训练与微调中展现实用价值,可实现近似最优的超参数选择与检查点识别,同时引入更严谨的数学结构,如统一的缩放指数和渐近合理的行为。
引言
作者利用大语言模型自动化发现缩放定律——即预测模型性能随规模变化的数学关系——这对于基础模型开发中的高效模型设计、超参数调优与资源分配至关重要。先前工作依赖人类专家缓慢的手动实验,在庞大且开放的符号表达式空间中常难以取得最优或稳健的定律。其主要贡献是 SLDAgent,一种基于进化的智能体,可协同优化缩放定律的函数形式与参数,在其新基准 SLDBench 的八个多样化任务上实现最先进的外推精度,并生成比人工推导定律更精确且更具概念严谨性的规律。
数据集

作者使用 SLDBench,一个用于缩放定律发现的精选基准,包含八个来自近期文献和调查的真实任务。每个任务需从观测实验数据中预测符号缩放定律,输入特征(如模型规模、数据集规模、学习率)、目标值(如损失、Brier 分数)和控制索引(如模型架构或数据集领域)以支持按设置拟合参数。
关键子集及其细节:
- 并行缩放定律:36 个训练点 / 12 个测试点。特征:模型规模与并行度。测试:8 路并行(相对于训练的 1–4 路外推 2 倍)。
- 词汇量缩放定律:1080 个训练点 / 120 个测试点。特征:非词汇参数、词汇量、字符数。测试:词汇量固定为 96,300(比训练最大值大 1.5 倍)。
- 监督微调 (SFT):504 个训练点 / 42 个测试点。特征:每模型-数据集对的 SFT 数据规模。测试:固定 819,200 个 token(比训练最大值 410,000 外推 2 倍)。
- 领域混合:80 个训练点 / 24 个测试点。特征:四个模型规模下的五个领域比例。划分遵循原始仓库。
- 专家混合 (MoE):193 个训练点 / 28 个测试点。特征:密集参数、专家数量。测试:1.31B 密集参数(比训练最大值 368M 大 3.6 倍)。
- 数据受限:161 个训练点 / 21 个测试点。特征:模型规模、token 数、唯一 token 数。测试:最大与第二大 N 或 D 值。
- 学习率与批量大小:共 2,702 个点。特征:学习率、批量大小、数据规模、非嵌入参数。无明确训练/测试划分;用于完整拟合。
- U 形缩放定律:389 个训练点 / 127 个测试点。特征:log FLOPs。测试:来自原始论文的最终上升阶段,用于检验双重下降行为。
作者使用训练划分通过 LLM 驱动的智能体系统进化符号表达式与优化例程。每个任务要求智能体输出一个 Python 函数,根据输入与控制组预测目标值,函数形式固定但参数按组调整。测试集始终保留用于外推评估——通常选择更大的模型规模、更大的数据集或更极端的超参数。
所有任务均在预装 scikit-learn、pandas 和数据集的沙盒环境中评估。智能体生成两个文件:包含缩放函数的 law.py 和包含公式、推理与拟合参数的 explain.md。最终指标为测试集上的 R²,完美性能接近 1.0。
元数据与处理按任务标准化:特征与目标明确界定,参数限制强制执行(如最多 4–7 个参数)。缩放定律函数中不允许输入依赖特征(如最小值、最大值)。系统测试跨控制组的泛化能力与训练范围外的外推能力,使 SLDBench 特别适合评估代理式科学发现。
方法
作者利用进化框架通过两个核心子程序的协同进化发现缩放定律:表达式函数与优化例程。如框架图所示,系统从初始化阶段开始,建立基线程序对,通常由幂律表达式与标准 BFGS 优化器组成。该初始程序被执行并连同其适应度分数(在训练数据上计算的 R2 系数)存储于进化数据库中。
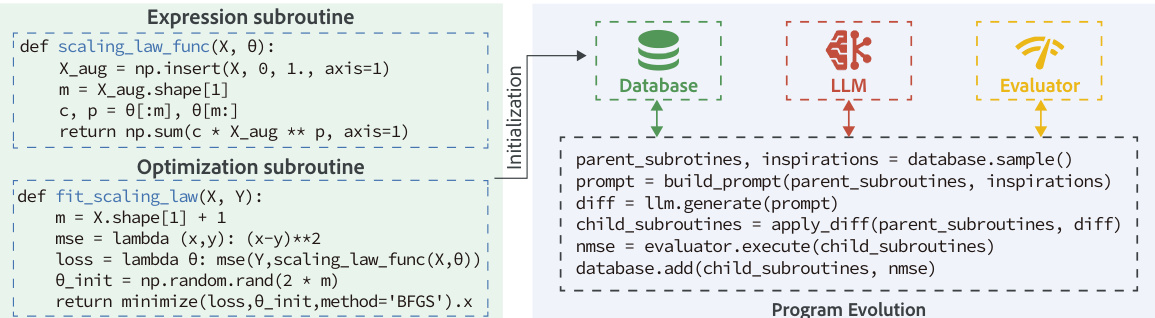
表达式子程序定义为 fθ:x↦y^,实现一个将输入特征 x 映射至预测值 y^ 的函数,使用参数 θ。优化子程序则负责寻找最优参数 θ^=argminθL(y,fθ(x)),针对给定损失函数 L,从而生成可用于外推的参数化缩放定律。在每轮进化中,从数据库中按概率混合选择父程序,强调高分程序(利用,70%)、多样性(20%)和顶级表现者(精英,10%)。该父程序与若干高性能“灵感”程序被构造成结构化提示。大型语言模型(LLM)随后生成对父程序代码的修改,例如改变定律形式、更换优化器或调整全局变量。生成的子程序被执行,其优化例程在给定数据集上拟合表达式,并计算训练数据上的 R2 分数。新子程序及其分数随后加入数据库供后续世代使用。进化循环在固定迭代预算后终止,最终数据库中得分最高的程序作为提议定律返回。整个进化过程中测试集始终未被触及。
实验
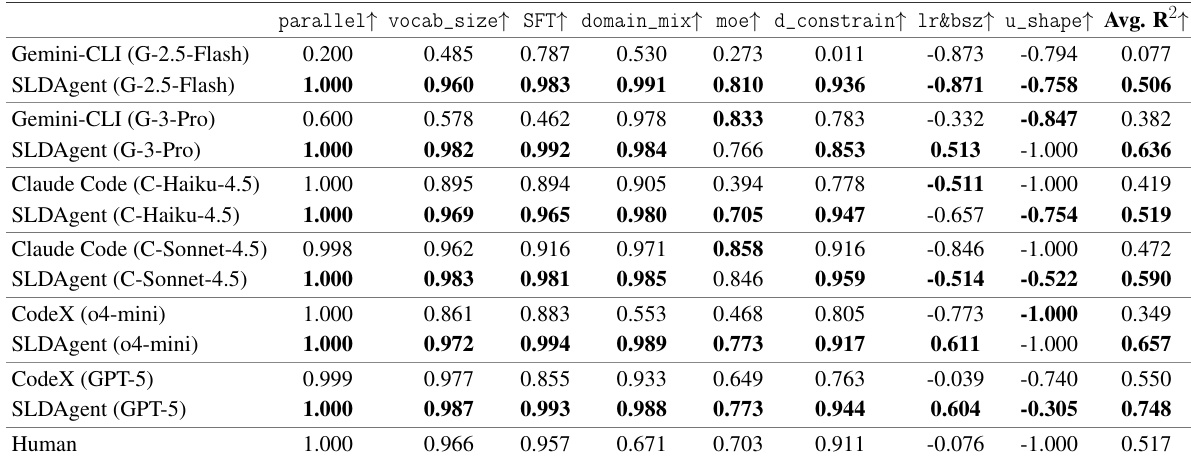
- SLDAgent 在 SLDBench 上优于 8 个基线智能体(包括 Aider、Terminus、OpenHands、Codex、OpenCode、Goose、Mini-SWE-Agent 和人类专家),搭配 GPT-5 时取得 R²=0.748,超越人类基线(R²=0.517),除 lr&bsz 外在所有任务上匹配或超越人类表现。
- 与多个 LLM(Gemini-2.5-Flash、Gemini-3-Pro、Claude-Haiku-4.5、Claude-Sonnet-4.5、GPT-5、o4-mini)搭配时,SLDAgent 持续优于原生 CLI 智能体,R² 提升 +0.100 至 +0.429,小模型上提升最显著。
- 任务难度方面:SLDAgent 在简单任务(并行,R²=1.000)和中等任务(moe)上表现优异,在困难任务(lr&bsz、u_shape)上有所改进,但部分仍低于人类表现,揭示模型容量限制。
- SLDAgent 发现更有效的缩放定律:例如,SFT 任务中其定律使用量纲一致的 (D/θ₃) 缩放以更清晰解释;MoE 任务中发现可分离且渐近稳定的表达式(R²=0.891 对比人类的 0.732)。
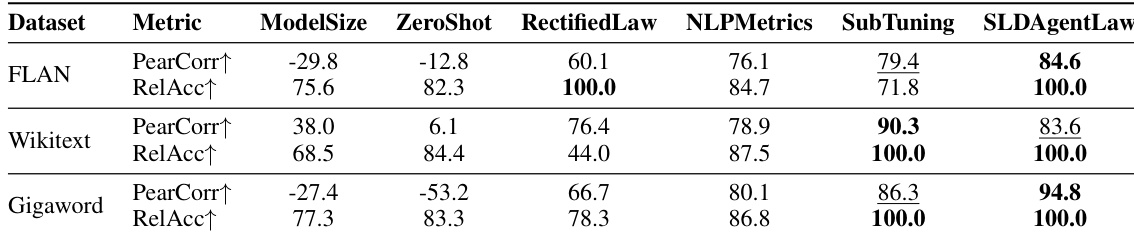
- 在 LLM 选择(第 4.5 节)中,SLDAgent 发现的定律在 3 个数据集上实现 100.0% RelAcc 和 87.7% PearCorr,优于包括 RectifiedLaw、NLPMetrics、SubTuning、ModelSize 和 ZeroShot 在内的 5 个基线。
- 消融实验证实协同优化符号表达式与拟合过程至关重要:完整 SLDAgent(R²=0.848)优于仅优化定律的变体(R²=0.775),尤其在 lr&bsz 任务上(0.194 对比 -0.224)。
- 进化搜索(50 次迭代,5 个岛屿)稳健提升性能,未出现过拟合,在简单/中等任务上趋于稳定,在困难任务上持续上升。
结果表明,SLDAgent 在多个模型家族中均优于基线智能体与原生 CLI 系统,平均 R2 分数持续高于各供应商专属智能体。搭配 GPT-5 时,该智能体在所有任务上匹配或超越人类表现,证明其设计即使在模型容量受限时也能实现稳健的缩放定律发现。
结果表明,SLDAgentLaw 在所有数据集和指标上均取得最高性能,优于包括 ZeroShot、RectifiedLaw、NLPMetrics 和 SubTuning 在内的所有基线。在 FLAN 数据集上,SLDAgentLaw 实现 100.0% 的相对准确率与 84.6% 的皮尔逊相关性;在 Wikitext 与 Gigaword 上持续取得最高分,展示其在微调中选择最优 LLM 的卓越能力。
作者使用 SLDAgent 发现缩放定律,并与仅进化定律表达式的消融变体对比。结果表明,完整 SLDAgent 的平均 R² 分数(0.848)高于仅定律变体(0.775),在 lr&bsz 等挑战性任务上改进显著,表明协同优化符号表达式与拟合过程对成功至关重要。

结果表明,SLDAgent 搭配 GPT-5 时取得最高平均 R2 分数 0.748,优于所有基线智能体,在简单并行任务上匹配人类表现,其余任务均超越人类。在不同模型家族中,SLDAgent 持续优于原生 CLI 系统,R2 提升幅度为 +0.100 至 +0.429,搭配 GPT-5 时在所有任务上匹配或超越人类表现。
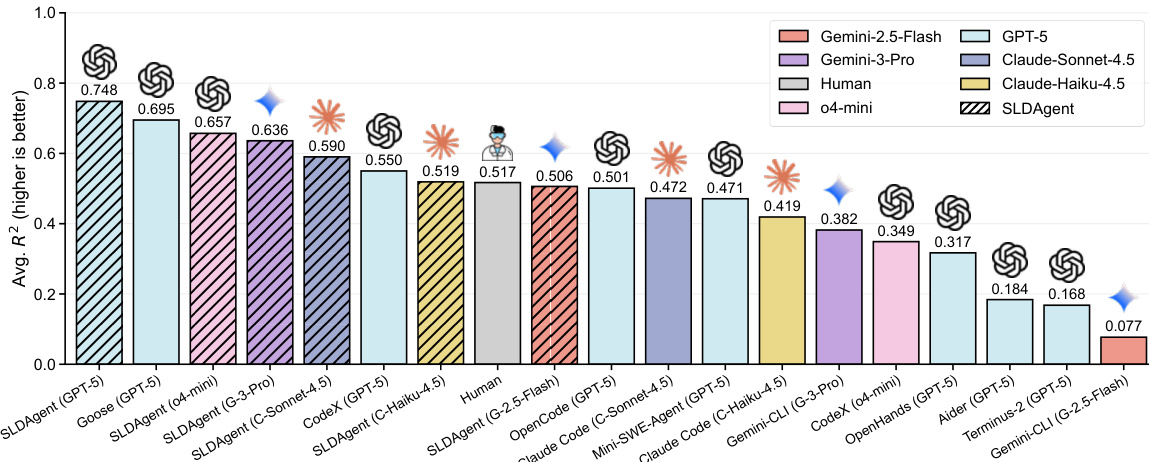
结果表明,SLDAgent 在所有模型家族中持续优于原生 CLI 系统,在大多数任务上取得更高的平均 R2 分数。搭配 GPT-5 时,SLDAgent 在所有任务上匹配或超越人类表现,实现最高整体平均 R2 0.748。