Command Palette
Search for a command to run...
PUSA V1.0:通过向量化时间步自适应,以500美元训练成本超越Wan-I2V
PUSA V1.0:通过向量化时间步自适应,以500美元训练成本超越Wan-I2V
摘要
视频扩散模型的快速发展受到时间建模基础性瓶颈的制约,尤其是传统标量时间步长变量所强加的刚性帧演化同步机制。尽管任务特定的优化方法与自回归模型试图应对这些挑战,但仍受限于计算效率低下、灾难性遗忘问题或适用范围狭窄等缺陷。在本工作中,我们提出Pusa,一种开创性的范式,通过引入向量化时间步长自适应(Vectorized Timestep Adaptation, VTA),在统一的视频扩散框架内实现了细粒度的时间控制能力。此外,VTA是一种非破坏性适配方法,能够完整保留基础模型的原有能力。通过在当前最先进的Wan2.1-T2V-14B模型上采用VTA进行微调,我们实现了前所未有的高效性:在训练成本上仅需Wan-I2V-14B的1/200(500美元 vs. ≥10万美元),数据集规模仅需其1/2500(4K样本 vs. ≥1000万样本)。Pusa不仅为图像到视频(I2V)生成树立了新标准,取得VBench-I2V总评分为87.32%(优于Wan-I2V-14B的86.86%),更实现了多种零样本多任务能力,如起始帧与终止帧控制、视频扩展等,且无需针对特定任务进行额外训练。与此同时,Pusa仍具备文本到视频生成能力。机制分析表明,该方法在保留基础模型生成先验的基础上,精准注入时间动态特性,有效避免了向量化时间步长固有的组合爆炸问题。本工作建立了一种可扩展、高效且多功能的下一代视频合成范式,为科研与产业界实现高质量视频生成的普惠化提供了坚实基础。代码已开源,地址为:https://github.com/Yaofang-Liu/Pusa-VidGen
一句话总结
来自香港城市大学、华为研究院、腾讯PCG等机构的作者提出Pusa,一种统一的视频扩散框架,通过向量化的时序适应(VTA)实现细粒度的时间控制,同时不牺牲基础模型的能力。与以往受限于固定时序或任务特定训练的方法不同,Pusa在仅使用2500×更少的数据和200×更低的训练成本下实现了SOTA的图像到视频性能,同时支持零样本多任务生成,包括视频扩展和文本到视频,为高保真视频合成提供了一种可扩展、高效且多功能的解决方案。
主要贡献
- 传统的视频扩散模型依赖标量时序变量,强制帧之间同步、刚性的演化,限制了其在图像到视频(I2V)生成等任务中对复杂时间动态的建模能力。
- 作者提出Pusa,一种基于向量化时序适应(VTA)的新框架,能够在保留基础模型生成先验的前提下,实现细粒度、独立的帧演化。
- Pusa在图像到视频任务中达到SOTA性能(VBench-I2V得分为87.32%),训练数据量减少超过2500倍,训练成本降低200倍,同时支持零样本多任务能力,如视频扩展和起止帧生成。
引言
作者利用向量化时序适应(VTA)克服了视频扩散模型中的一个关键限制:由标量时序控制的刚性、同步帧演化。传统模型由于这种不灵活的时间结构,在图像到视频(I2V)生成和编辑等任务中表现受限,而先前的解决方案——如任务特定微调或自回归设计——则面临高计算成本、灾难性遗忘或适用性有限的问题。作者的主要贡献是Pusa V1.0,一种对SOTA Wan2.1-T2V-14B模型的非破坏性适应,将标量时序替换为向量化时序,从而实现独立的帧演化。这使得单一统一模型在仅需2500×更少数据和200×更低训练成本(500vs.100,000)的情况下,实现SOTA的I2V性能,同时支持零样本能力,如起止帧生成、视频扩展和文本到视频,且无需重新训练。机制分析表明,Pusa通过针对性修改保留了基础模型的生成先验,避免了组合复杂性,实现了可扩展、高效且多功能的视频合成。
方法
作者基于流匹配框架开发Pusa模型,旨在实现具有细粒度时间控制的视频生成。核心方法建立在连续归一化流之上,目标是学习一个依赖时间的向量场 vt(zt,t),以控制数据从先验分布到目标数据分布的变换。这通过训练神经网络 vθ(zt,t) 来近似目标向量场 ut(zt∣z0,z1) 实现,该向量场由连接数据样本 z0 与先验样本 z1 的指定概率路径导出。对于线性插值路径,目标向量场简化为与中间状态 zt 和标量时序 t 无关的常数差 z1−z0。训练目标是最小化预测向量场与目标向量场之间的期望平方欧几里得距离。
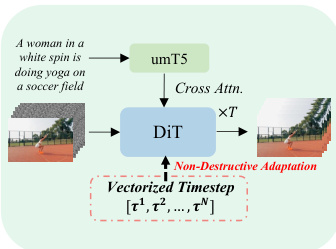
为将此框架扩展至视频生成,模型引入向量化时序变量 τ∈[0,1]N,其中 N 为视频片段中的帧数。这使得每帧可沿其独立的概率路径演化,由帧特定的进展参数 τi 定义。在给定向量化时序 τ 下的视频状态通过帧级线性插值得到:Xτ=(1−τ)⊙X0+τ⊙X1。整个视频的目标向量场 U(X0,X1) 为先验视频与数据视频之差 X1−X0,在所有时序上保持恒定。模型学习一个单一的神经网络 vθ(X,τ),根据当前视频状态 X 和向量化时序 τ 预测整个视频的速度场。
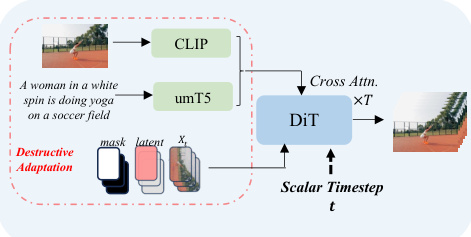
Pusa模型通过适配预训练的文本到视频(T2V)扩散Transformer实现,具体为DiT(Diffusion Transformer)架构。关键的架构修改称为向量化时序适应(VTA),重新设计了模型的时间条件机制。模型不再处理标量时序 t,而是处理向量化时序 τ。这通过修改时序嵌入模块以生成一系列帧特定的嵌入 Eτ 实现。这些嵌入随后被投影以生成DiT架构中每个模块的帧级调制参数(缩放、偏移和门控)。这使得模型能够根据每帧的独立时序 τi 条件化其潜在表示 zi 的处理,从而能够同时处理处于不同生成路径上的多帧。该适应方式为非破坏性,保留了基础模型的T2V能力。
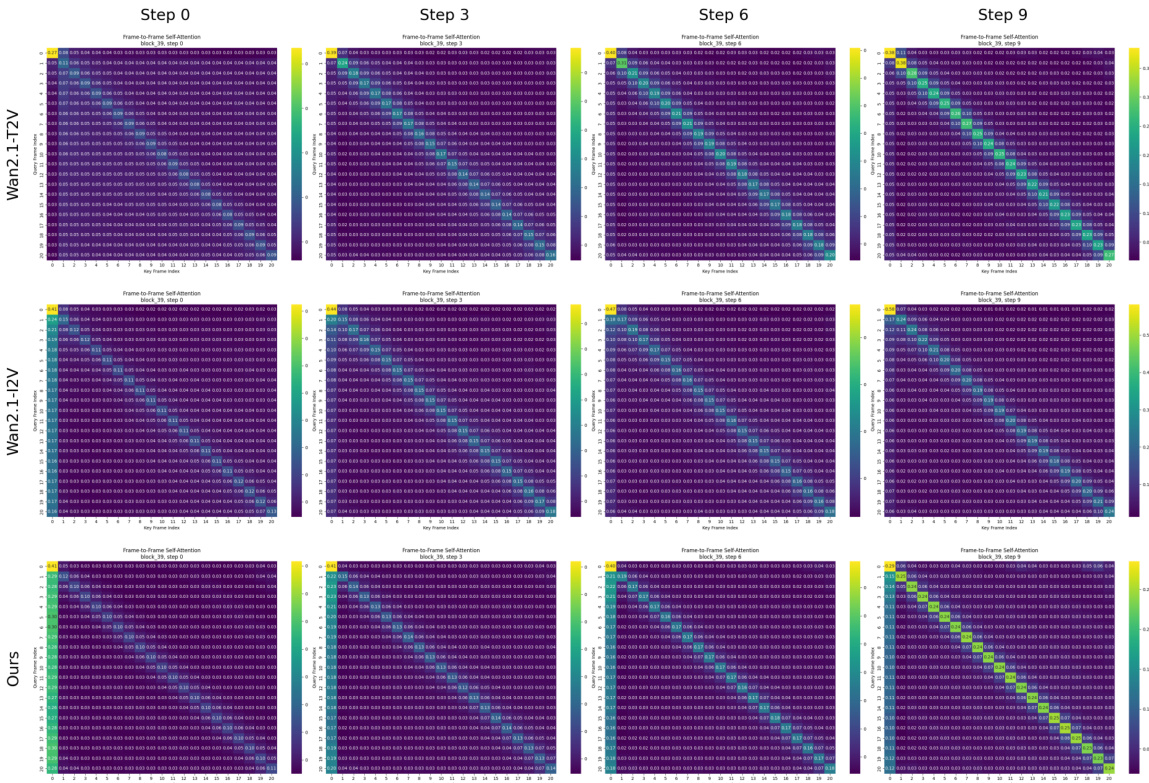
训练过程通过最小化帧感知流匹配(FAFM)目标函数来优化模型参数 θ,该函数是标准流匹配损失在向量化时序设置下的推广。目标是最小化预测速度场 vθ(Xτ,τ) 与目标场 X1−X0 之间的平方Frobenius范数。训练中的一个关键方面是采用概率时序采样策略(PTSS),用于采样向量化时序 τ,以使模型暴露于同步和异步帧演化场景。作者采用简化的训练方案,设 pasync=1,即 τ 的每个分量独立地从均匀分布中采样,从而最大化训练过程中模型遇到的时间状态多样性。该方法使模型能够在无需复杂采样策略的情况下学习细粒度的时间控制。
实验
- 工业级效率:Pusa通过在大型基础模型上进行轻量级LoRA微调,实现了前所未有的数据效率(≤Wan-I2V数据集大小的1/2500)和计算效率(≤Wan-I2V训练成本的1/200),实现了大模型的实际适应。
- 多任务泛化:Pusa支持无需额外训练的多样化视频任务零样本生成——包括I2V、T2V、起止帧、视频扩展和补全——得益于灵活的向量化时序条件。
- 质量-吞吐量权衡:在Vbench-I2V上,Pusa总得分为87.32%,超过Wan-I2V的86.86%,在主体一致性(97.64 vs. 96.95)、背景一致性(99.24 vs. 96.44)和动态运动(52.60 vs. 51.38)方面表现更优,且仅使用10次推理步骤。
结果表明,当LoRA秩为512、alpha为1.7时,模型达到最优性能,更高秩在各项指标上均持续提升质量。模型收敛迅速,峰值性能在900次训练迭代时达到,进一步训练带来的收益逐渐减小。推理质量在10步内显著提升,之后增益趋于边际,表明10步在速度与输出质量之间提供了最佳平衡。
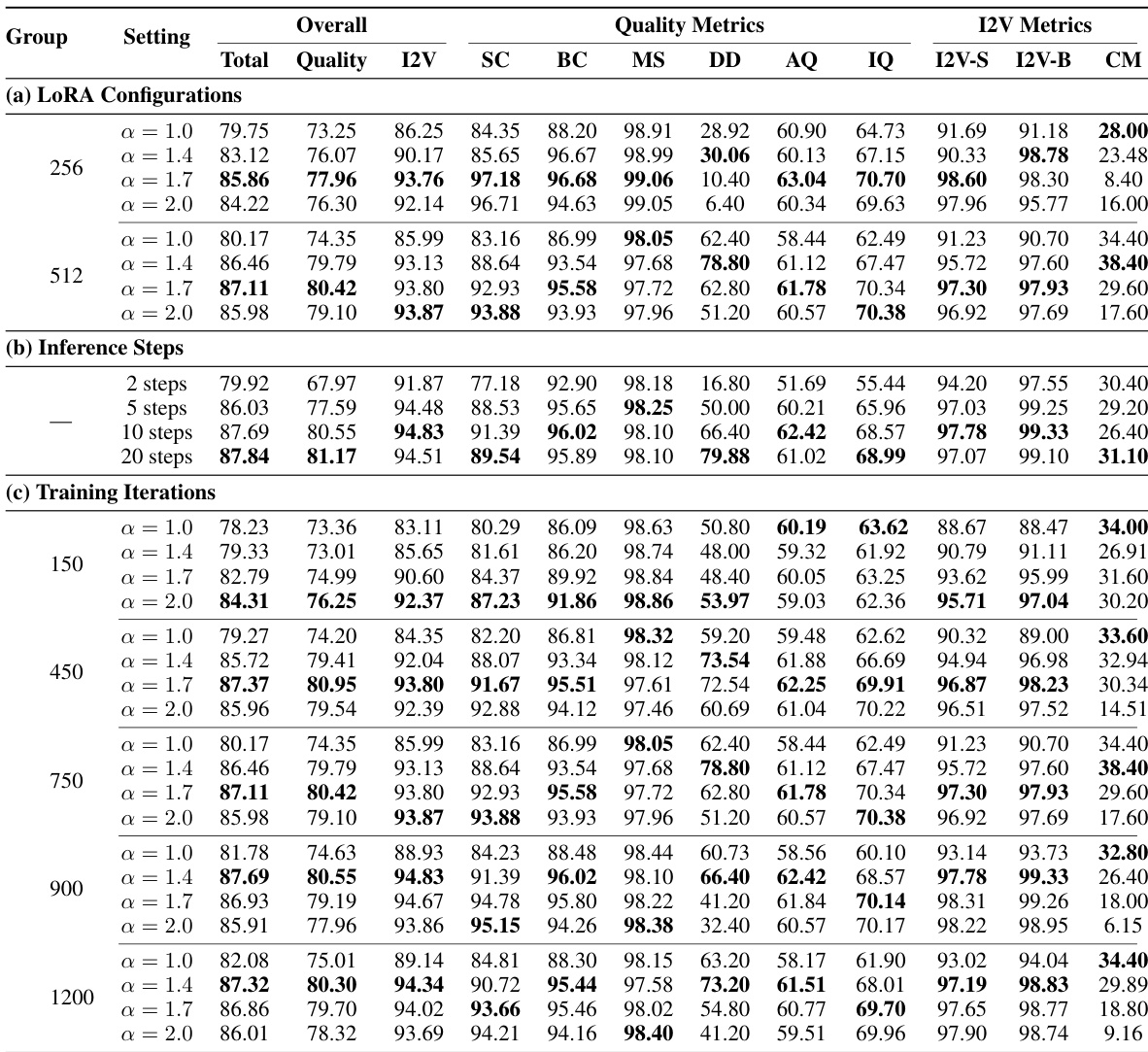
结果表明,所提模型总得分为87.32,超过Wan-I2V基线的86.86,同时仅使用不到1/2500的训练数据和1/200的计算成本。模型在关键指标上表现更优,包括I2V背景一致性(99.24 vs. 96.44)和I2V主体一致性(97.64 vs. 96.95),表明其对输入图像条件具有强遵循能力。