Command Palette
Search for a command to run...
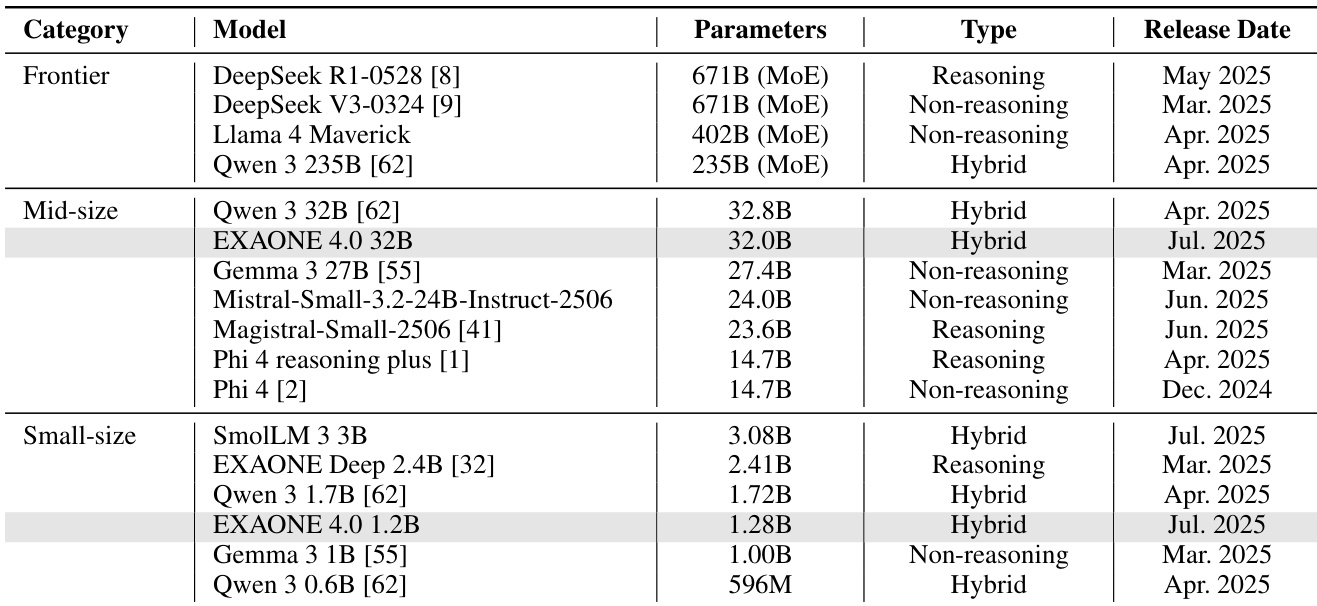
EXAONE 4.0:融合非推理与推理模式的统一型大语言模型
EXAONE 4.0:融合非推理与推理模式的统一型大语言模型
摘要
本技术报告介绍了EXAONE 4.0,该模型融合了非推理模式(Non-reasoning mode)与推理模式(Reasoning mode),在保留EXAONE 3.5卓越易用性的基础上,进一步具备EXAONE Deep所拥有的先进推理能力。为推动智能体式人工智能(agentic AI)时代的发展,EXAONE 4.0引入了关键特性,包括智能体工具调用能力,并将多语言支持扩展至西班牙语,现已支持英语、韩语和西班牙语三种语言。EXAONE 4.0模型系列包含两种规模:一款中等规模的32B参数模型,专为高性能场景优化;另一款小型1.2B参数模型,适用于设备端部署应用。实验结果表明,EXAONE 4.0在同类开源模型中展现出卓越性能,即便与前沿水平模型相比也具备较强的竞争力。目前,该系列模型已面向科研用途公开发布,可通过 https://huggingface.co/LGAI-EXAONE 免费下载使用。
一句话摘要
作者提出 EXAONE 4.0,一个包含 32B 和 1.2B 参数版本的双模式语言模型系列,融合非推理与推理能力,支持智能体工具调用和多语言(包括西班牙语),在开放模型与领先专有模型中均表现出色,其 32B 和 1.2B 版本已通过 Hugging Face 公开发布,供研究使用。
主要贡献
- EXAONE 4.0 在单一模型中统一了用于快速、用户友好交互的 非推理模式 与用于深度、精准问题求解的 推理模式,显著提升了实际应用中的可用性与高级推理能力。
- 模型引入智能体工具调用功能,并将多语言支持扩展至西班牙语,同时采用混合全局-局部注意力架构,高效处理长达 128K 标记的上下文,在文档问答与 RAG 任务中表现优异。
- EXAONE 4.0 在同规模开源模型中表现卓越,且在数学推理、编程与专家知识任务中与前沿模型保持竞争力,32B 与 1.2B 两个版本均已公开,供研究使用。
引言
作者利用 EXAONE 4.0 应对新兴智能体 AI 时代对多功能、高性能语言模型日益增长的需求。通过在单一模型中融合非推理模式(用于快速交互)与推理模式(用于复杂问题求解),该模型弥合了易用性与高级认知能力之间的鸿沟。以往工作在平衡现实适用性与深度推理方面面临挑战,常需为不同功能部署独立模型,同时在长上下文处理与多语言支持方面亦存在困难。EXAONE 4.0 通过混合注意力架构,高效处理 128K 标记上下文,集成智能体工具调用,并扩展多语言支持至西班牙语,且未牺牲英语或韩语性能。模型在推理、指令遵循与长上下文任务中达到最先进水平,同时在更大规模前沿模型中仍具竞争力。
数据集
- EXAONE 4.0 的数据集由来自网络语料库、代码仓库和领域特定文档的多样化高质量数据构成,重点提升世界知识、推理能力与多语言支持。
- 预训练使用 14 万亿标记数据——是 EXAONE 3.5 32B 所用 6.5 万亿标记的两倍——数据源自大规模网络来源,经过严格筛选以提升认知行为与后训练性能。
- 监督微调(SFT)数据分为非推理与推理模式,并按五个领域组织:世界知识、数学/代码/逻辑、智能体工具使用、长上下文、多语言性。
- 在世界知识领域,筛选具有高教育价值的网络内容,对推理任务优先采用专业性高、难度大的数据。
- 数学、代码与逻辑数据受限于真实答案验证的难度;因此,对每个唯一查询使用多种多样响应以增强训练多样性,并通过仔细筛选防止退化,尤其在长代码响应中。
- 代码领域不仅涵盖问题求解,还包含来自代码语料库的全栈软件工程数据。
- 长上下文数据由网络来源构建,并重构韩语法律、行政与技术文档以支持多样化输入格式,通过系统性变化上下文长度与关键信息位置,训练全面理解能力。
- 智能体工具使用数据包含多轮、多步骤用户-代理交互及环境反馈,旨在模拟真实世界工具调用流程与迭代推理。
- 多语言数据支持韩语与西班牙语,融入文化相关的内容、本地教育与产业主题(尤其韩语),并翻译现有样本以确保自然流畅的对话。
- 统一模式训练采用 1.5:1 的标记比例(推理 : 非推理),该比例通过消融实验确定,以防止模型过度依赖推理行为。
- 第二轮微调使用来自代码与工具使用领域的高质量推理数据,以缓解领域不平衡并进一步提升性能。
- 数据集经过处理以确保一致性,元数据用于反映领域、任务类型与上下文长度,未提及显式裁剪——数据结构化设计支持长文本、多轮与上下文丰富的交互。
方法
EXAONE 4.0 模型采用基于 Transformer 的架构,相较于前代 EXAONE 3.5 在注意力机制与归一化策略上进行了多项关键改进。主要架构创新是采用混合注意力机制,以 3:1 的比例结合局部注意力与全局注意力。该设计区别于 EXAONE 3.5 所用的全全局注意力。局部注意力组件采用滑动窗口注意力,窗口大小为 4K 标记,该设置旨在最小化对短上下文性能的负面影响,同时实现高效的长上下文处理。如图所示,滑动窗口注意力将注意力限制在每个标记周围的固定大小窗口内,从而降低计算复杂度与内存需求。相比之下,全局注意力允许每个标记关注序列中所有其他标记,保留长距离依赖关系。混合方法在两者之间取得平衡,确保模型兼具局部连贯性与全局上下文感知能力。
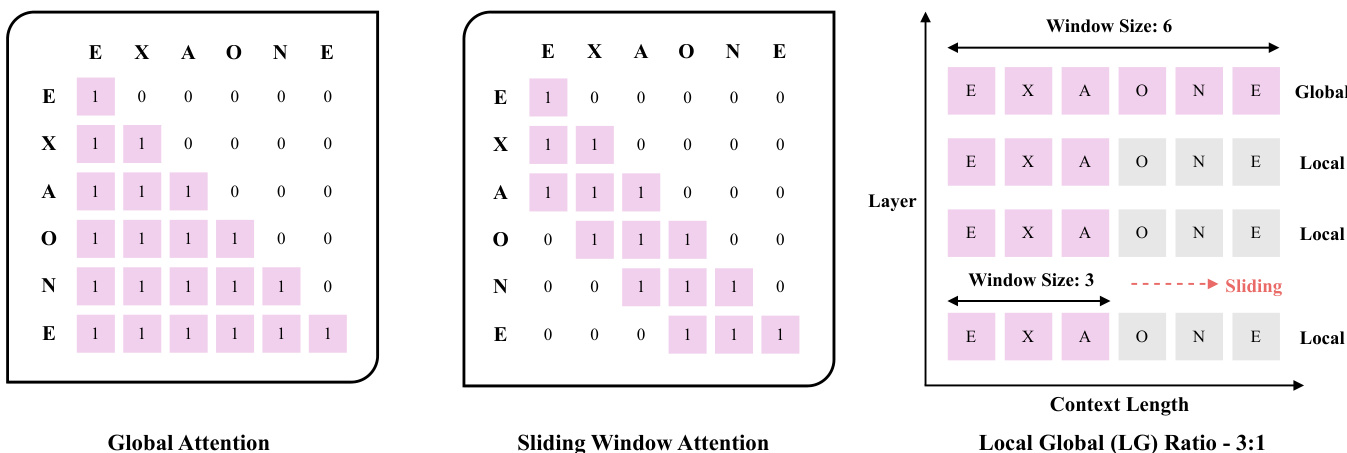
模型的注意力机制进一步优化,对全局注意力省略了旋转位置编码(Rotary Position Embedding),以防止模型对序列长度产生偏差,维持一致的全局视角。对于局部注意力机制,模型未采用分块注意力(chunked attention),而是使用滑动窗口注意力,这是一种成熟的稀疏注意力方法,以理论稳定性与开源框架广泛支持著称。此选择确保实现稳健且易于集成。为缓解长上下文微调过程中短上下文场景下的性能下降,模型采用精心设计的数据选择方法与渐进式训练策略。
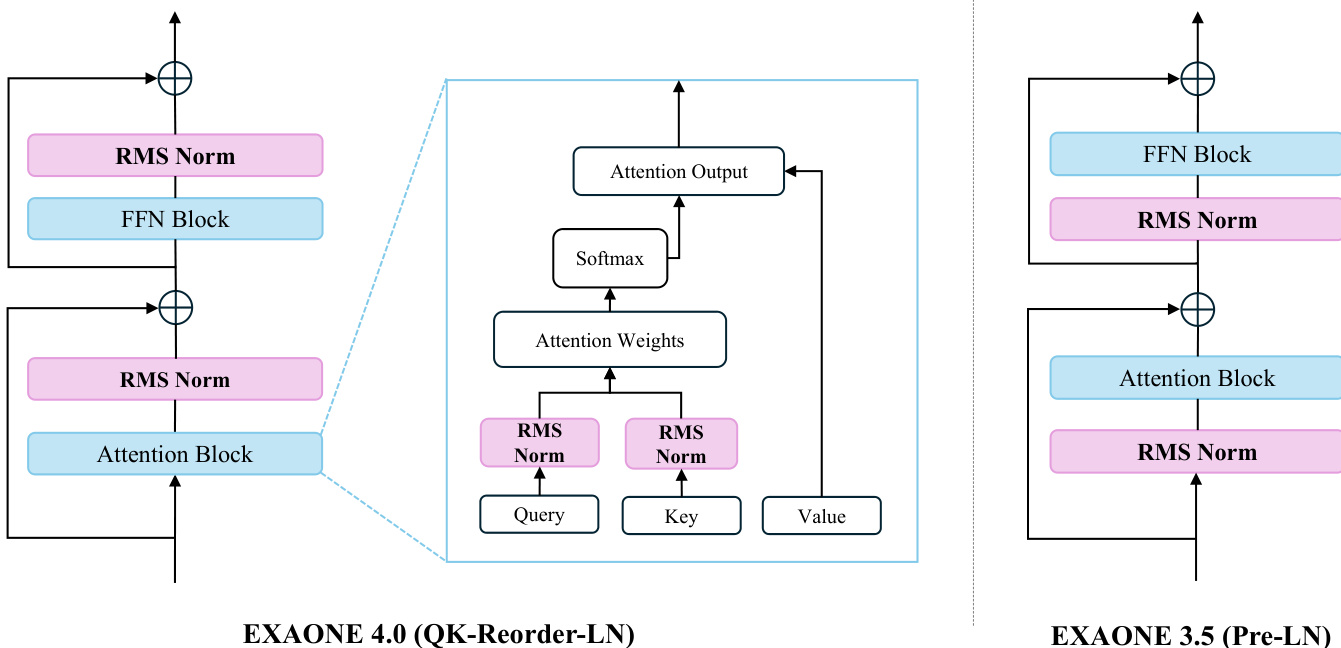
EXAONE 4.0 的另一项重要架构改进是层归一化的位置调整。模型采用 QK-Reorder-LN(查询-键重排层归一化)方法,即在输入查询与键之后应用 RMSNorm,并在注意力输出后再次应用。这与 EXAONE 3.5 所用的 Pre-LN 架构不同,后者在注意力与前馈块之前进行归一化。如框架图所示,QK-Reorder-LN 方法旨在更好地控制各层输出的方差,尽管计算成本更高,但仍能提升下游任务表现。归一化类型 RMSNorm 于 EXAONE 3.0 引入,仍在 EXAONE 4.0 中保留。
EXAONE 4.0 模型系列包含两种配置:32B 参数模型与 1.2B 参数模型。两者共享相同词汇表,由大致等量的韩语与英语标记,以及少量多语言标记组成。32B 模型的最大上下文长度通过两阶段过程扩展至 128K 标记:首先将预训练于 4K 上下文长度的模型扩展至 32K 标记,再进一步扩展至 128K 标记。每阶段均通过 Needle In A Haystack(NIAH)测试验证性能保持。对于 1.2B 模型,上下文长度扩展至 64K 标记,约为大多数 1B 参数级模型支持的典型最大长度的两倍。
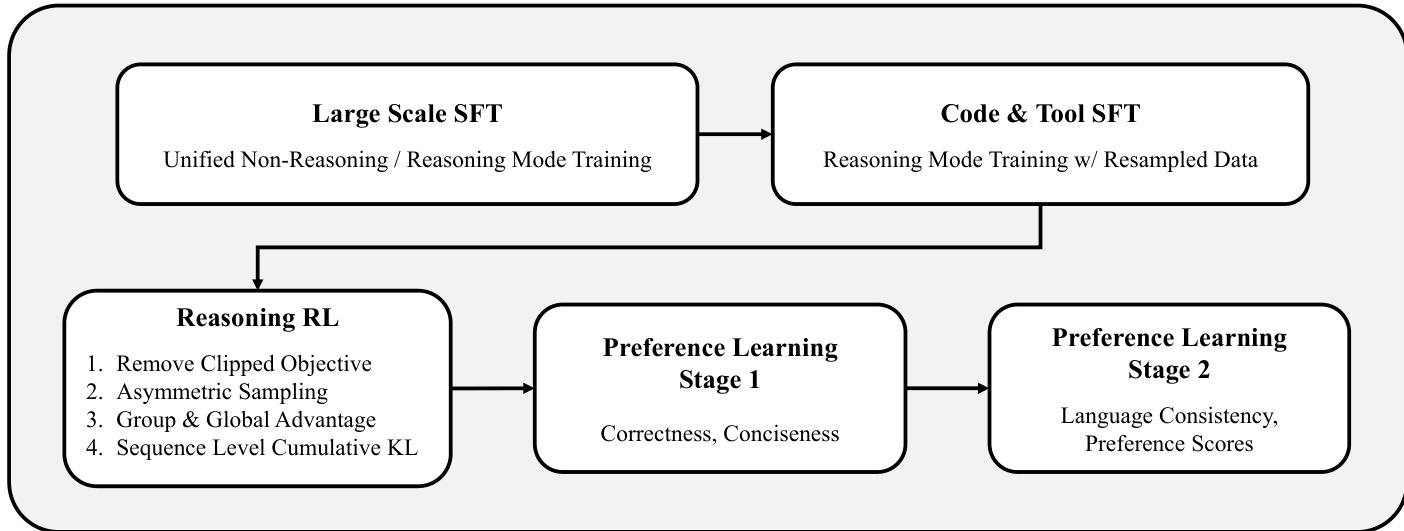
EXAONE 4.0 的后训练阶段分为三个阶段:监督微调(SFT)、推理强化学习(RL)与偏好学习。SFT 阶段通过大规模数据扩展以高效提升性能。推理 RL 阶段采用一种名为 AGAPO(非对称采样与全局优势策略优化)的新算法,以增强模型推理能力。AGAPO 移除了 PPO 的裁剪目标,采用非对称采样引入负反馈,计算组优势与全局优势,并应用序列级累积 KL 惩罚。偏好学习阶段通过两阶段过程整合非推理与推理模式,优化正确性、简洁性、语言一致性与偏好得分。
实验
- 在六个基准类别上评估 EXAONE 4.0:世界知识、数学/编程、指令遵循、长上下文、智能体工具使用与多语言性。
- 在数学/编程基准(AIME 2025、HMMT FEB 2025、LIVECODEBENCH V5/6)上,EXAONE 4.0 32B 表现优异,无论在推理还是非推理模式下均超越 Qwen3 235B;EXAONE 4.0 1.2B 在推理模式下超越所有基线模型,仅略逊于 EXAONE Deep 2.4B。
- 在 GPQA-DIAMOND 基准上,EXAONE 4.0 32B 与 1.2B 均取得第二高分,展现出强大的专家级知识水平。
- 在长上下文基准(HELMET、RULER、LONGBENCH)上,EXAONE 4.0 模型表现具有竞争力,通过 YaRN 扩展上下文支持,使小模型实现 64K 标记推理。
- 在工具使用基准(BFCL-v3、TAU-BENCH)上,EXAONE 4.0 32B 达到或超过更大规模基线;EXAONE 4.0 1.2B 在 TAU-BENCH(零售)中取得测试模型中的最高分。
- 在多语言任务中,EXAONE 4.0 在韩语(KMMLU-PRO、KSM、KO-LONGBENCH)与西班牙语(MMMLU (ES)、MATH500 (ES)、WMT24++) 上表现强劲,高质量翻译通过 LLM-as-a-judge 评估。
- 推理预算消融实验表明,即使在 32K 推理预算下,性能下降也极小(多数模型 ≤5%),保持了竞争力。
作者使用表 3 展示 EXAONE 4.0 32B 在推理模式下多个基准的评估结果。结果显示,EXAONE 4.0 32B 在数学/编程与世界知识类别中表现强劲,在 AIME 2025 与 GPQA-DIAMOND 等关键基准上超越 Qwen 3 235B 与 DeepSeek R1-0528 等更大模型。模型在指令遵循与智能体工具使用方面也表现良好,尤其在 TAU-BENCH 零售任务中,尽管其规模小于前沿模型。
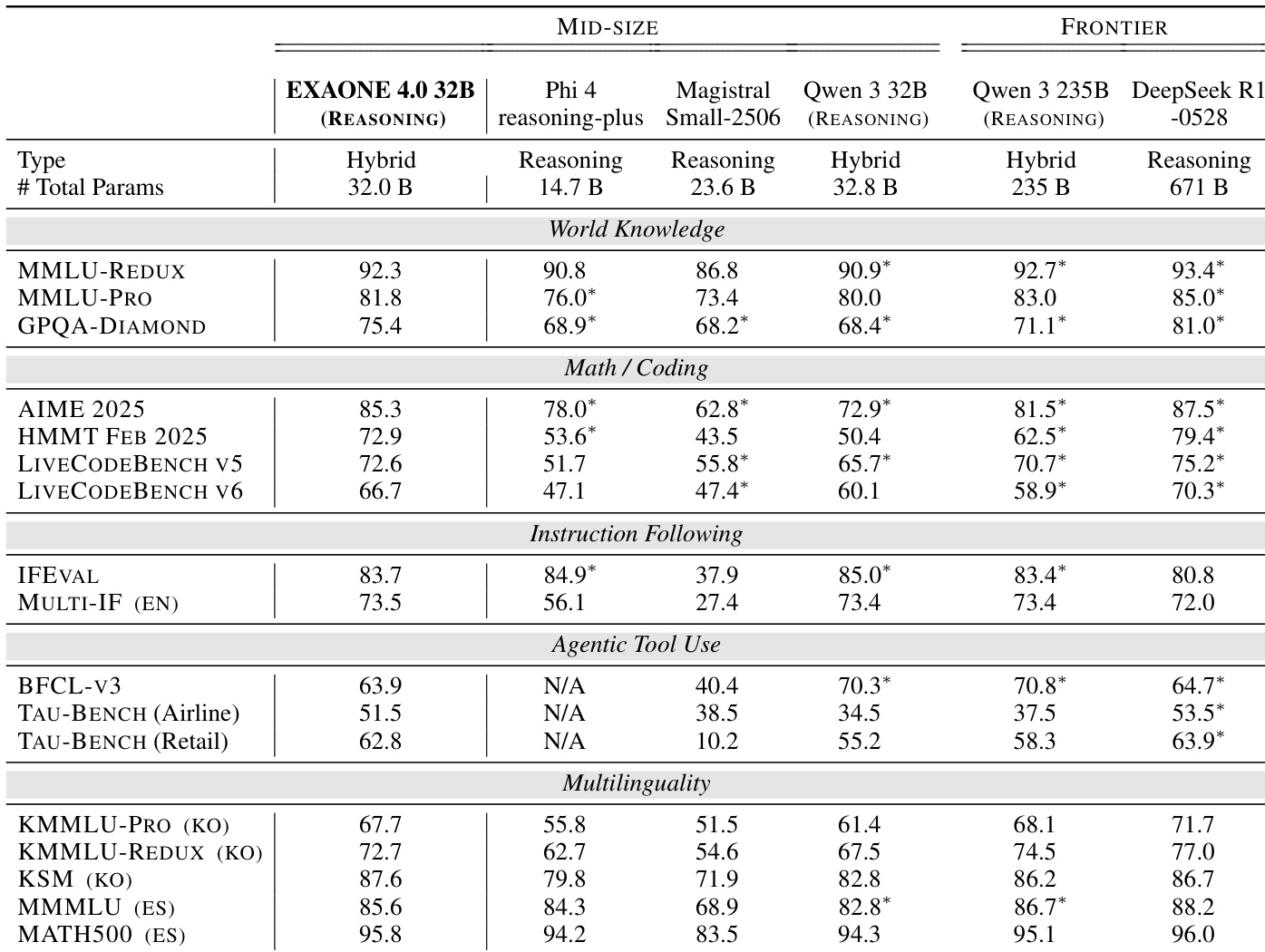
作者使用 HELMET 基准评估长上下文能力,涵盖六项任务,包括回忆、检索增强生成与摘要。结果显示,EXAONE 4.0 32B 在所有上下文长度下均达到高准确率,优于大多数中等规模模型,即使在 128K 上下文下仍表现强劲;而小规模模型如 EXAONE 4.0 1.2B 在较短长度下表现具有竞争力,但在 64K 及以上长度受限。
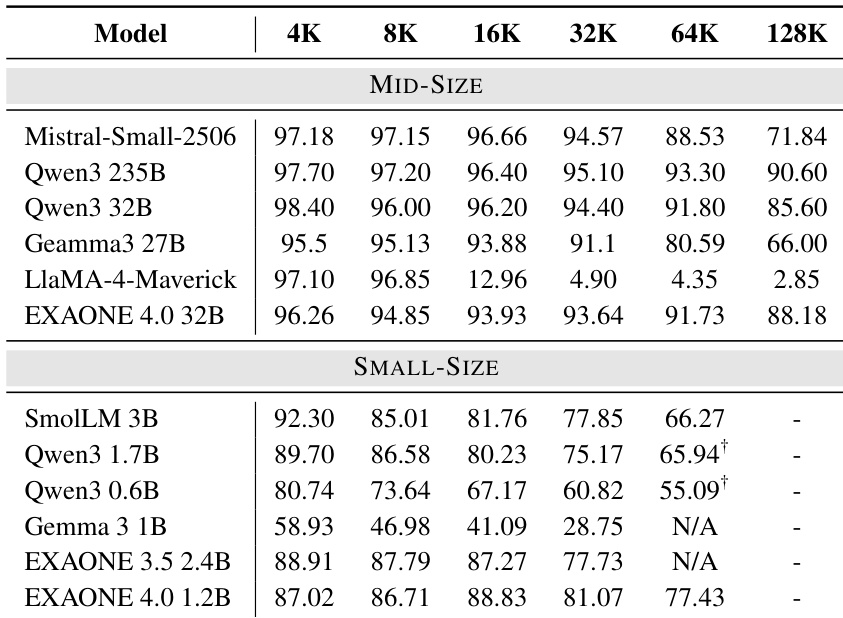
作者通过 YaRN 将上下文长度扩展至 32K 以上,评估小模型(包括 EXAONE 4.0 1.2B)在 HELMET 基准上的长上下文性能。结果显示,EXAONE 4.0 1.2B 在 32K 标记以内取得最高平均分,并在 64K 标记内保持强劲表现,优于该范围内的其他小模型。
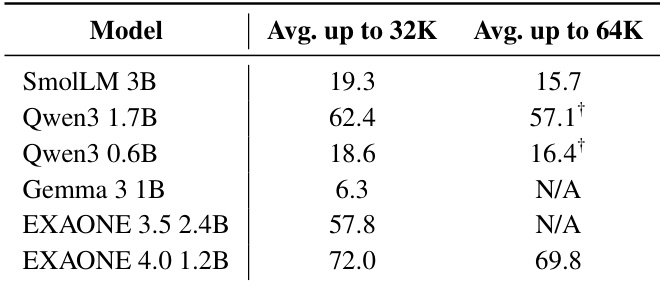
作者使用表格对比 EXAONE 4.0 1.2B 在非推理模式下与多个小规模模型在多个基准上的表现。结果显示,EXAONE 4.0 1.2B 在多数类别中表现具有竞争力,尤其在数学/编程与多语言任务中表现突出,且在长上下文与指令遵循基准上优于其他模型。
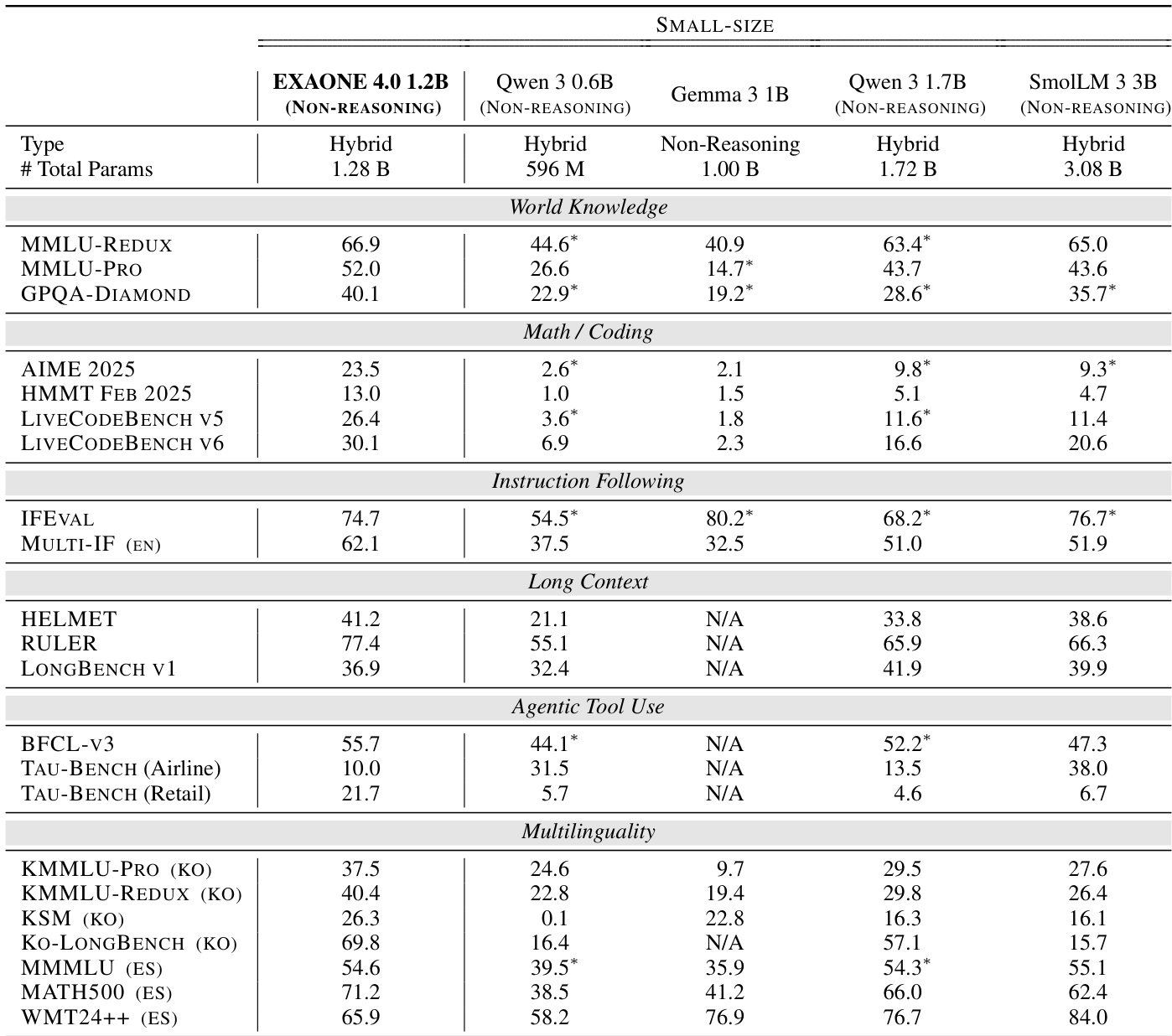
作者使用多样化的基准评估 EXAONE 4.0 在多个领域(世界知识、数学/编程、指令遵循、长上下文、智能体工具使用、多语言性)的表现。结果显示,EXAONE 4.0 模型表现具有竞争力,尤其在数学/编程与世界知识任务中表现优异,32B 模型在多个类别中超越更大规模基线。