Command Palette
Search for a command to run...
用于长序列生成高效推理的解码器-混合解码器架构
用于长序列生成高效推理的解码器-混合解码器架构
摘要
近年来,语言建模领域的进展表明,状态空间模型(State Space Models, SSMs)在高效序列建模方面具有显著优势。尽管混合架构如 Samba 以及解码器-解码器结构 YOCO 已在性能上超越了 Transformer 模型,但先前的研究尚未探索 SSM 层之间表示共享所带来的效率潜力。本文提出一种简单而高效的机制——门控记忆单元(Gated Memory Unit, GMU),用于实现跨层间的高效记忆共享。我们将该机制应用于构建 SambaY,这是一种解码器-混合-解码器架构,在跨解码器模块中引入 GMU,以共享基于 Samba 的自解码器所产生的记忆读出状态。SambaY 在显著提升解码效率的同时,保持了线性的预填充时间复杂度,并显著增强了长上下文建模能力,且无需显式的位置编码。通过大规模扩展实验,我们证明该模型相较于强基线 YOCO,展现出更低的不可约损失(irreducible loss),表明其在大规模计算资源环境下具备更优的性能可扩展性。我们所构建的最大规模模型,结合微分注意力(Differential Attention)机制,其在数学推理任务(如 Math500、AIME24/25 和 GPQA Diamond)上的表现显著优于 Phi4-mini-Reasoning,且无需任何强化学习训练。在 vLLM 推理框架下,对于 2K 长度的提示(prompt)和 32K 生成长度,SambaY 的解码吞吐量最高可达 Phi4-mini-Reasoning 的 10 倍。相关训练代码库已基于开源数据在 GitHub 上发布,地址为:https://github.com/microsoft/ArchScale。
一句话总结
微软与斯坦福大学的研究人员提出 SambaY,一种解码器混合解码器架构,引入门控记忆单元(GMU)以实现状态空间模型中跨层高效记忆共享,无需位置编码即可实现卓越的解码效率与长上下文性能,优于 YOCO,在长提示场景下推理吞吐量最高可达 10 倍提升,同时在 Math500、AIME24/25 和 GPQA Diamond 上提升推理准确率。
主要贡献
-
本文提出门控记忆单元(GMU),一种用于 SSM 层间高效表示共享的新机制,从而构建 SambaY 架构——一种解码器混合解码器模型,将一半的交叉注意力层替换为 GMU,以共享基于 Samba 的自解码器的内部状态,从而在保持线性预填充复杂度的同时降低解码成本,并消除对显式位置编码的需求。
-
SambaY 展现出优越的可扩展性,在高达 34 亿参数和 6000 亿 token 的规模下,其不可约损失显著低于 Samba+YOCO 基线,即使在仅 256 的小滑动窗口下,也能在 Phonebook 和 RULER 等长上下文任务中表现优异,表明其在大规模计算环境下具有强大的性能可扩展性。
-
基于 SambaY 与差分注意力构建的 Phi4-mini-Flash-Reasoning 变体,在无需强化学习的情况下,优于 Phi4-mini-Reasoning 在 Math500、AIME24/25 和 GPQA Diamond 等推理基准上的表现,同时在 vLLM 推理框架下,长提示场景的解码吞吐量最高提升 10 倍,展示了长链推理中的实际效率优势。
引言
作者针对大语言模型中高效长序列推理的挑战展开研究,传统 Transformer 在生成阶段面临二次方复杂度的内存与计算开销。尽管近期混合架构如 YOCO 通过引入单个全注意力层并复用其键值缓存来提升效率,但在响应生成过程中,交叉注意力操作仍带来高昂的 I/O 成本——尤其在长链思维(Chain-of-Thought)推理中尤为突出。为克服此问题,作者提出门控记忆单元(GMU),一种轻量级机制,用于在新型解码器混合解码器架构 SambaY 中实现 SSM 层间的高效表示共享。通过将一半的交叉注意力层替换为 GMU,SambaY 在降低昂贵注意力操作的同时,保持线性预填充复杂度,并消除对位置编码的需求。该方法展现出优越的可扩展性与长上下文检索性能,在 vLLM 推理框架下,长提示场景的解码吞吐量最高提升 10 倍,且在 Math500 和 GPQA Diamond 等基准上取得优异结果,无需依赖强化学习。
数据集
- 数据集由部分开源数据构成,作者在论文第一页脚注中提供了代码。
- 论文引用了现有数据集与代码库,均采用 CC-BY 4.0 许可,注明原始来源并说明所用版本。
- 每个使用数据集均标明许可类型,提供可用 URL,并遵守原始数据服务条款,尤其针对爬取数据。
- 数据在模型训练过程中通过子集混合使用,训练阶段应用特定比例以平衡多样性与性能。
- 未明确描述裁剪策略,但通过构建元数据确保子集间一致性,包括标签对齐与格式统一。
- 作者确认所有资产均已获得适当授权,且论文讨论部分已涵盖同意相关考虑。
- 为支持可复现性,数据集与代码已公开,提供结构化文档以指导主要实验结果的复现。
方法
作者提出门控记忆单元(GMU),一种旨在实现序列模型层间高效记忆共享的机制。该单元通过使用基于当前层输入的门控机制,调节前一层执行的 token 混合操作。形式上,GMU 输入当前层隐藏状态 Xl∈Rn×dm 与前一层 l′ 的混合表示 M(l′)∈Rn×dp,通过可学习门控过程输出 Yl∈Rn×dm,其操作定义为 Yl=(M(l′)⊙σ(XlW1T))W2,其中 σ 为 SiLU 激活函数,⊙ 表示逐元素乘法,W1,W2 为可学习权重矩阵。该门控机制有效重加权前一层的 token 混合算子,实现对记忆的细粒度再校准。作者还引入 GMU 的归一化版本(nGMU),在逐元素乘法后应用 RMSNorm,他们认为这一设计对训练稳定性至关重要,尤其当记忆源自线性注意力机制时。
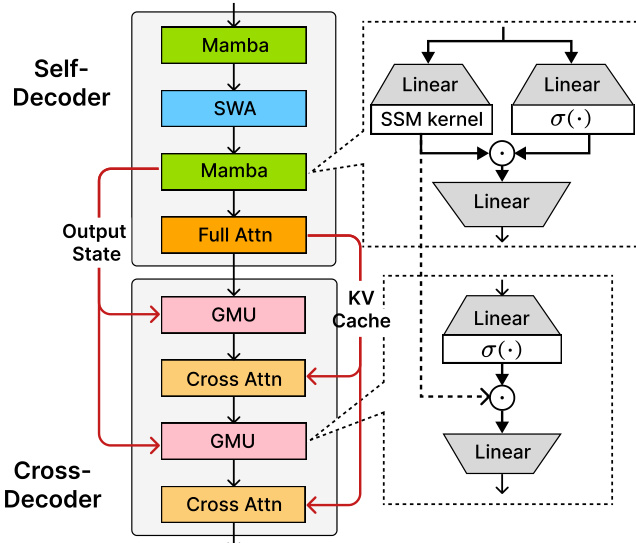
所提出架构的核心 SambaY 是一种解码器混合解码器框架,利用 GMU 提升效率。如框架图所示,模型由自解码器与交叉解码器组成。自解码器处理输入序列,基于 Samba 层构建,Samba 层是一种状态空间模型(SSM)。该自解码器包含一个最终的全注意力层,用于生成键值(KV)缓存。交叉解码器负责生成输出,是交叉注意力层与 GMU 的混合体。作者将交叉解码器中一半的交叉注意力层替换为 GMU。这些 GMU 被设计为共享自解码器中最后 SSM 层的记忆读出状态,特别是最终 Mamba 层的输出状态。这一设计使模型在预填充阶段保持线性时间复杂度,因为 KV 缓存仅由自解码器的全注意力层在预填充阶段计算一次。在解码阶段,GMU 将一半交叉注意力层的内存 I/O 复杂度从 O(dkvN) 降低至常数 O(dh),从而在长序列场景下带来显著效率提升。
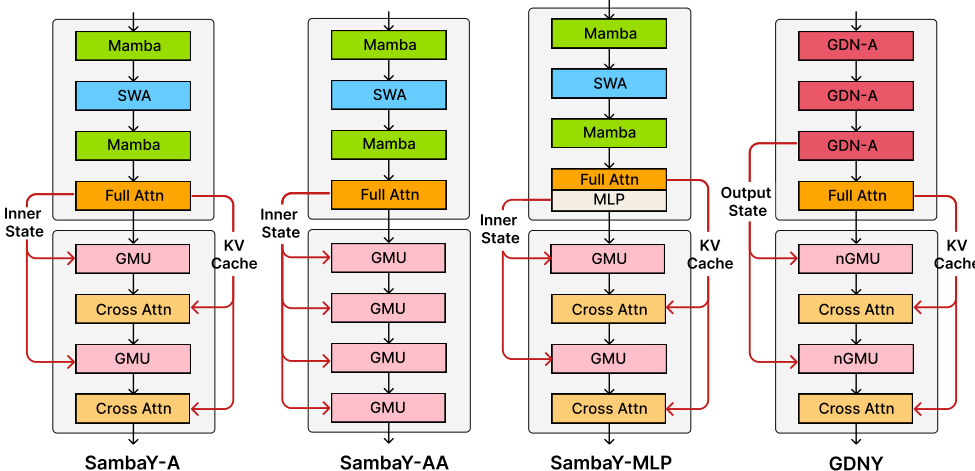
论文展示了 SambaY 架构的多个变体,如图所示,以探索不同设计选择。SambaY-A 为基线架构,其交叉解码器由一系列 GMU 与交叉注意力层组成。SambaY-AA 将标准交叉注意力层替换为使用线性核的注意力机制,旨在进一步提升效率。SambaY-MLP 将交叉注意力层替换为多层感知机(MLP),以探究不同 token 混合机制的影响。GDNY 架构为更复杂的变体,其自解码器使用门控 DeltaNet(GDN)层,并在交叉解码器中采用归一化 GMU(nGMU)。图中突出了这些模型内部结构的关键差异,尤其是自解码器组成与交叉解码器中具体层类型。作者主要关注 SambaY 架构,其在解码效率与长上下文性能方面相比基线 YOCO 显著提升。
实验
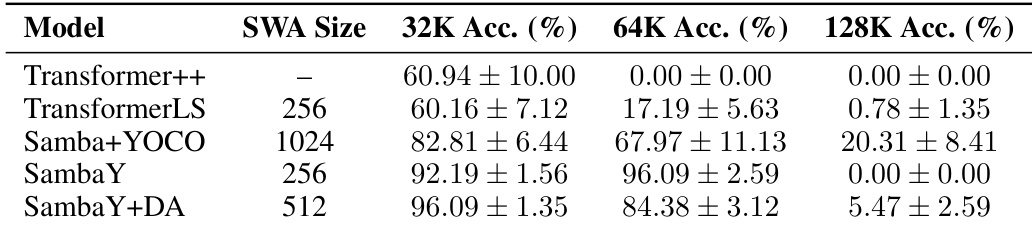
- SambaY 与 SambaY+DA 混合模型在小滑动窗口尺寸(如 128–512)下,于 Phonebook(32K)与 RULER 基准上实现强劲的长上下文检索性能,尽管注意力范围缩小,仍优于纯 Transformer 模型。在 Phonebook 上,SambaY+DA 在 512 窗口下达到 83.6% 准确率,而 Samba+YOCO 需 2048 才达峰值性能,表明其效率更优。
- 在 RULER 基准上,SambaY 变体在单针(S: 92.1%)与多键(MK: 88.4%)检索任务中取得最佳结果,超越 Transformer++ 与 TransformerLS,后两者在超过 32K 上下文后性能显著下降。
- 在 5T token 上训练的 Phi4-mini-Flash(38 亿)采用 SambaY+DA 架构,在 8 个下游任务中的 7 个上优于 Phi4-mini 基线,包括 MMLU(+4.2%)与 MBPP(+12.3%),同时在长生成场景下实现最高 10 倍吞吐量提升。
- 从 Phi4-mini-Flash 通过蒸馏得到的 Phi4-mini-Flash-Reasoning,在 AIME24/25(68.8% Pass@1)、Math500(72.1%)与 GPQA Diamond(54.3%)上达到 SOTA 水平,尽管采用更高效的 SambaY 架构且长上下文处理速度提升 4.9 倍,仍超越 Phi4-mini-Reasoning。
- 消融实验确认,nGMU 与门控后归一化对长上下文检索至关重要,若替换为标准 GMU 或调整归一化位置,Phonebook 上性能最高下降 56.3 分。
- 使用 ProLong-64K 数据集与变长训练显著提升长上下文性能,尤其对 SSM 基模型,SambaY+DA 在较小窗口下即达竞争性结果。
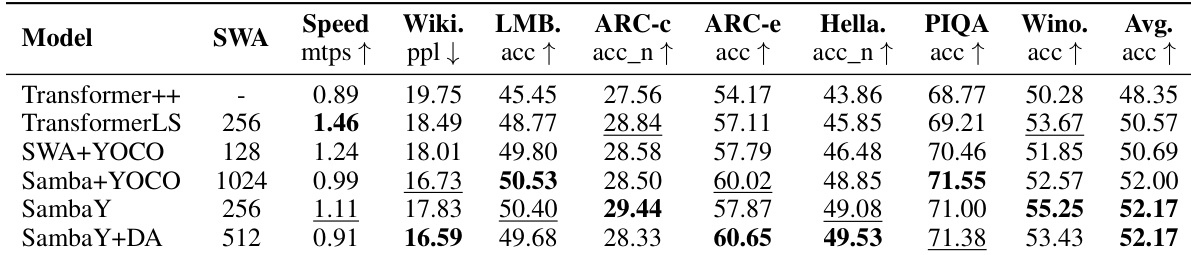
- 基于 SambaY 的模型在短上下文任务上表现出色(如 WikiText-103: 14.2 困惑度,ARC-Easy: 85.1%),在 10 亿参数模型上以 128 MTPS 训练速度,使用 64 块 A100-80GB GPU 仍保持高效率。
- 所有实验均可复现,超参数、训练细节与计算资源均完整披露,统计显著性由多次运行的误差条支持。
作者使用 Phonebook 基准评估不同模型与滑动窗口注意力(SWA)尺寸下的长上下文检索性能。结果显示,SambaY 与 SambaY+DA 在 32K 上下文长度下达到最高准确率,其中 SambaY+DA 进一步提升性能,而 SWA 尺寸更大的模型如 Samba+YOCO 在更长上下文下出现收益递减且准确率下降。
作者采用结合 Mamba 与 Transformer 组件的混合架构,评估长上下文检索与下游性能。结果表明,SambaY 与 SambaY+DA 在 Phonebook 与 RULER 等长上下文任务中表现强劲,SambaY+DA 在多查询与多键检索中优于其他模型。这些模型在短上下文任务中也保持竞争力,SambaY 变体相比基于 Transformer 的模型展现出更高的训练速度与效率。
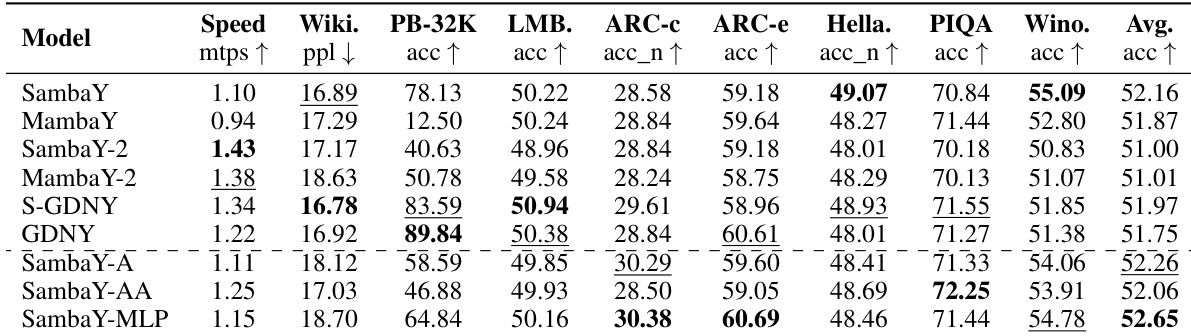
作者使用 10 亿参数模型评估多种混合架构在长上下文检索与下游任务上的表现。结果表明,SambaY 及其变体在 Phonebook 基准上达到最高检索准确率,SambaY-2 与 SambaY-MLP 在多个短上下文任务中表现优异,而 SambaY-A 与 SambaY-AA 在长上下文检索中出现显著退化,表明交叉注意力与特定记忆源在混合架构中的重要性。
作者使用表 6 比较标准参数化(SP)、μP 与 μP++ 的关键差异。结果显示,μP++ 将输出 logits 与学习率按 1/w 比例缩放,对标量或向量类参数使用零权重衰减,并将每层输出除以 √(2d),相比 SP 与 μP 显著提升训练稳定性和性能。

作者使用多种模型架构,包括 Transformer++、SambaY 与 Samba+YOCO,评估不同设计选择对长上下文检索与下游性能的影响。结果表明,包含 SSM 的混合模型始终优于纯 Transformer 架构,SambaY 变体在长上下文检索中表现强劲,同时在短上下文任务中保持竞争力。