Command Palette
Search for a command to run...
Ovis-U1 技术报告
Ovis-U1 技术报告
摘要
在本报告中,我们介绍了Ovis-U1——一款拥有30亿参数的统一多模态模型,集成了多模态理解、文本到图像生成以及图像编辑能力。基于Ovis系列模型的技术基础,Ovis-U1引入了一种基于扩散机制的视觉解码器,并搭配双向标记精炼器(bidirectional token refiner),使其在图像生成任务上的表现可与GPT-4o等领先模型相媲美。与以往部分模型采用冻结的多模态大语言模型(MLLM)进行生成任务不同,Ovis-U1采用了一种全新的统一训练范式,从语言模型出发进行端到端联合训练。相比仅在理解或生成任务上单独训练的模型,统一训练策略显著提升了整体性能,充分验证了将理解与生成任务深度融合所带来的优势。在OpenCompass多模态学术基准测试中,Ovis-U1取得了69.6分的成绩,超越了近期的先进模型如Ristretto-3B和SAIL-VL-1.5-2B。在文本到图像生成任务中,其在DPG-Bench和GenEval基准上的得分分别为83.72和0.89,表现优异。在图像编辑方面,Ovis-U1在ImgEdit-Bench和GEdit-Bench-EN两个基准上分别取得了4.00和6.42的得分,展现出强大的编辑能力。作为Ovis统一模型系列的首个版本,Ovis-U1在多模态理解、生成与编辑能力方面均实现了新的突破,推动了该领域的技术边界。
一句话总结
作者提出 Ovis-U1,这是阿里巴巴集团 Ovis 团队开发的一款 30 亿参数的统一模型,通过一种新颖的统一训练方法,结合基于扩散的视觉解码器和双向标记精炼器,实现了多模态理解、文本到图像生成和图像编辑的融合——在关键基准测试中超越了 Ristretto-3B 和 SAIL-VL-1.5-2B 等先前模型,为学术与创意应用提供了先进的多模态能力。
主要贡献
- Ovis-U1 是一款 30 亿参数的统一多模态模型,集成了文本到图像生成、图像编辑和多模态理解功能,通过一种基于扩散的视觉解码器和双向标记精炼器,解决了单一模型同时具备视觉感知与生成能力的挑战。
- 模型采用六阶段统一训练策略,使用多样化的多模态数据,联合提升理解与生成性能,证明了协同训练可使能力超越专用任务模型。
- Ovis-U1 在关键基准测试中取得最先进成果,OpenCompass 得分为 69.6,DPG-Bench 得分为 83.72,GenEval 得分为 0.89,ImgEdit-Bench 得分为 4.00,GEdit-Bench-EN 得分为 6.42,尽管模型规模紧凑,仍优于 Ristretto-3B 和 SAIL-VL-1.5-2B 等近期模型。
引言
作者利用多模态大语言模型(MLLM)的最新进展,特别是 GPT-4o,以应对日益增长的对统一系统的需求——该系统既能理解又能生成视觉内容。以往工作通常依赖于针对图像生成或视觉理解等不同任务的专用模型,导致流程碎片化且跨任务协同能力有限。核心挑战在于设计一个能与语言模型无缝集成的视觉解码器,并训练一个统一架构,以联合优化理解与生成能力。为克服这一难题,作者提出 Ovis-U1,一款 30 亿参数的统一模型,采用基于扩散的 Transformer 视觉解码器和双向标记精炼器,强化文本与图像的交互。模型通过六阶段统一策略,使用多样化多模态数据进行训练,使其在文本到图像生成、图像编辑和视觉理解方面表现卓越,尽管规模紧凑,仍超越部分专用模型。本工作表明,协同训练显著提升了两种模态的能力,为更高效、通用的多模态人工智能系统铺平了道路。
数据集
- Ovis-U1 的数据集由三类主要多模态数据构成:多模态理解数据、文本到图像生成数据,以及图像+文本到图像生成数据。
- 多模态理解数据结合了公开来源(COYO、Wukong、Laion、ShareGPT4V 和 CC3M)与内部数据。通过自定义预处理流程,过滤噪声样本,提升描述质量,并平衡数据比例以实现最佳训练效果。
- 文本到图像生成数据来自 Laion5B 和 JourneyDB。从 Laion5B 中筛选美学评分高于 6 的样本,并使用 Qwen 模型生成详细图像描述,形成 Laion-aes6 数据集。
- 图像+文本到图像生成数据包含四种子类型:
- 图像编辑:使用 OmniEdit、UltraEdit 和 SeedEdit。
- 参考图像驱动生成:利用 Subjects200K 和 SynCD 进行主体驱动任务,使用 Style-Booth 进行风格驱动任务。
- 像素级控制生成:包括 Canny 到图像、深度到图像、图像修复(inpainting)和图像外推(outpainting),数据来自 MultiGen_20M。
- 内部数据:补充公共数据源,提供风格驱动生成、内容移除、风格迁移、去噪、去模糊、着色和文本渲染等定制化数据。
- 模型使用这些数据子集的混合进行训练,通过精心调校的比例平衡任务覆盖度与训练稳定性。
- 数据处理包括美学筛选、通过 Qwen 自动生成描述,以及构建元数据以对齐图像与文本模态。未提及显式裁剪,但所有数据均经过标准预处理,以确保一致性和质量。
方法
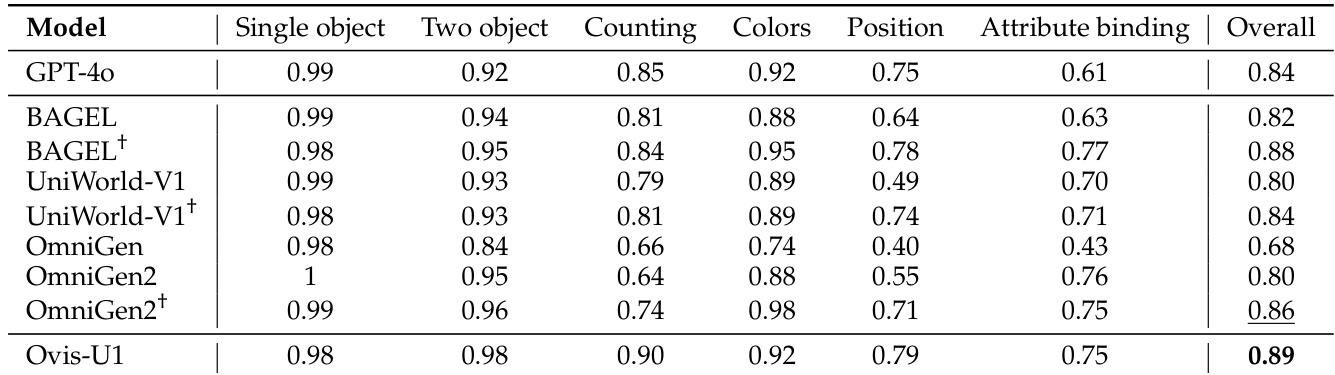
作者为 Ovis-U1 设计了统一架构,这是一款 30 亿参数的模型,旨在整合多模态理解、文本到图像生成与图像编辑。整体框架如图 1 所示,基于大语言模型(LLM)主干,并集成了用于视觉处理与生成的专用模块。该模型架构旨在实现文本与视觉模态在理解与生成任务中的无缝交互。
模型的核心是一个多模态大语言模型(MLLM),可同时处理文本与视觉嵌入。文本输入首先由文本分词器进行分词,生成文本嵌入并输入 MLLM。对于视觉输入,视觉编码器处理图像,其输出通过视觉适配器生成视觉语义嵌入。这些嵌入随后与文本嵌入在 MLLM 内部融合。视觉适配器采用像素洗牌操作进行空间压缩,再通过线性头和 softmax 函数将特征映射到视觉词汇的概率分布。最终的视觉嵌入基于该分布,从可学习的嵌入表中以加权平均方式获得。MLLM 生成一串标记,再经由文本反分词器处理,输出最终文本。在图像生成中,MLLM 的输出传递给视觉解码器,用于重建图像。
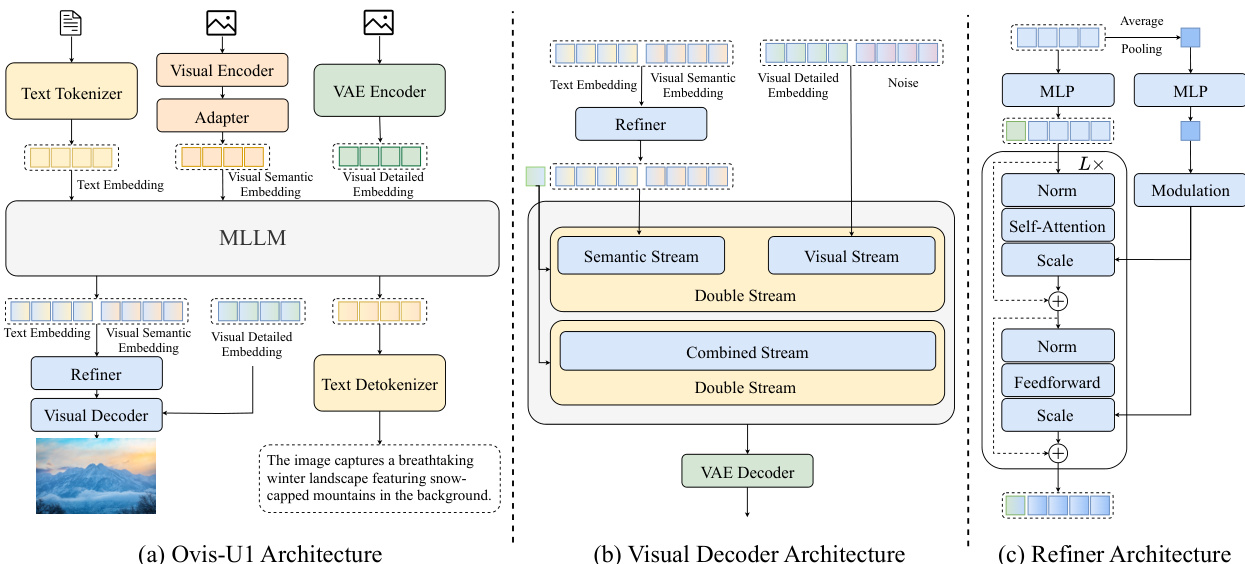
视觉解码器为一种扩散 Transformer,具体为修改版的 MMDiT 架构,作为图像生成的主干。如图所示,解码器采用双流架构,分别处理语义流与视觉流。语义流接收文本嵌入与视觉语义嵌入,二者拼接形成条件输入。视觉流处理由 VAE 编码器从上下文图像中提取的视觉细节嵌入,以及噪声输入。这两条流在合并流中融合,再由解码器处理,生成最终图像。解码器随机初始化并从头训练,层数与注意力头数量较其大型版本减少,以实现 10 亿参数规模。采用 SDXL 的 VAE 模型进行图像编码与解码,训练期间冻结以保留其生成能力。
为增强视觉与文本信息之间的交互,作者引入双向标记精炼器。该模块如图所示,由两个堆叠的 Transformer 块与调制机制构成。精炼器输入 MLLM 最后两层的特征,捕捉不同粒度的信息。通过拼接这些特征,精炼器可促进视觉与文本嵌入之间的更丰富交互。精炼器还包含一个可学习的 [CLS] 标记,与 MLLM 输出嵌入拼接,以捕获全局信息,有效替代外部 CLIP 模型。精炼器输出再反馈至 MLLM,以优化嵌入,提升生成质量。
实验
- 在图像理解、文本到图像生成和图像编辑任务上,使用标准化基准进行评估:OpenCompass 多模态学术基准、CLIPScore、DPG-Bench、GenEval、ImgEdit-Bench 和 GEdit-Bench-EN。
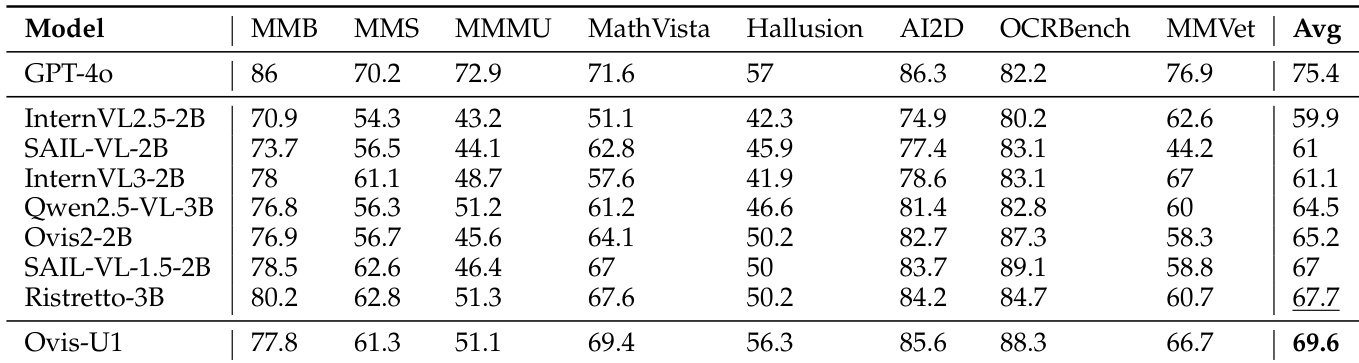
- 在 OpenCompass 基准测试中,Ovis-U1 的平均得分超越所有 30 亿参数模型,包括 InternVL2.5-2B、SAIL-VL-2B 和 Qwen2.5-VL-3B,尽管其理解部分仅约 20 亿参数。
- 在 GenEval 和 DPG-Bench 上,Ovis-U1 超越 OmniGen2 及其他开源模型,以 10 亿视觉解码器实现具有竞争力的结果,展现出强大的文本到图像生成能力。
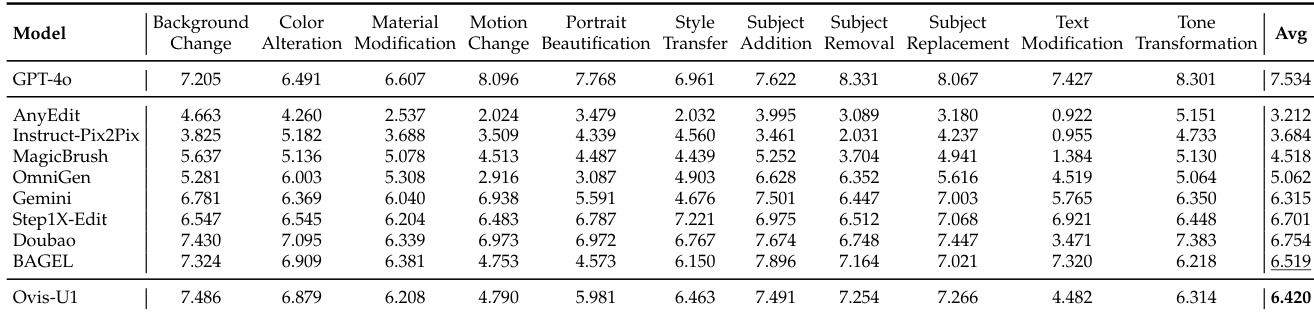
- 在 ImgEdit-Bench 和 GEdit-Bench-EN 上,Ovis-U1 达到最先进性能,超越 Instruct-Pix2Pix、MagicBrush 和 UltraEdit 等专用图像编辑模型。
- 消融实验验证了标记精炼器设计的有效性,基于 [CLS] 的精炼器表现更优,并凸显了统一训练在提升理解与生成能力方面的优势。
- 统一训练使 OpenCompass 理解能力提升 1.14 分,通过引入图像编辑数据,使文本到图像生成能力在 DPG-Bench 上提升 0.77 分。
- 无分类器引导(CFG)实验显示在不同 CFG 设置下均表现稳健,最优配置在 ImgEdit-Bench 上取得 4.13 分(CFG_img=2, CFG_txt=7.5),超越所有基准线。
- 定性结果展示了强大的推理能力、细粒度细节识别能力,以及高保真图像合成,实现精确、无伪影的编辑。
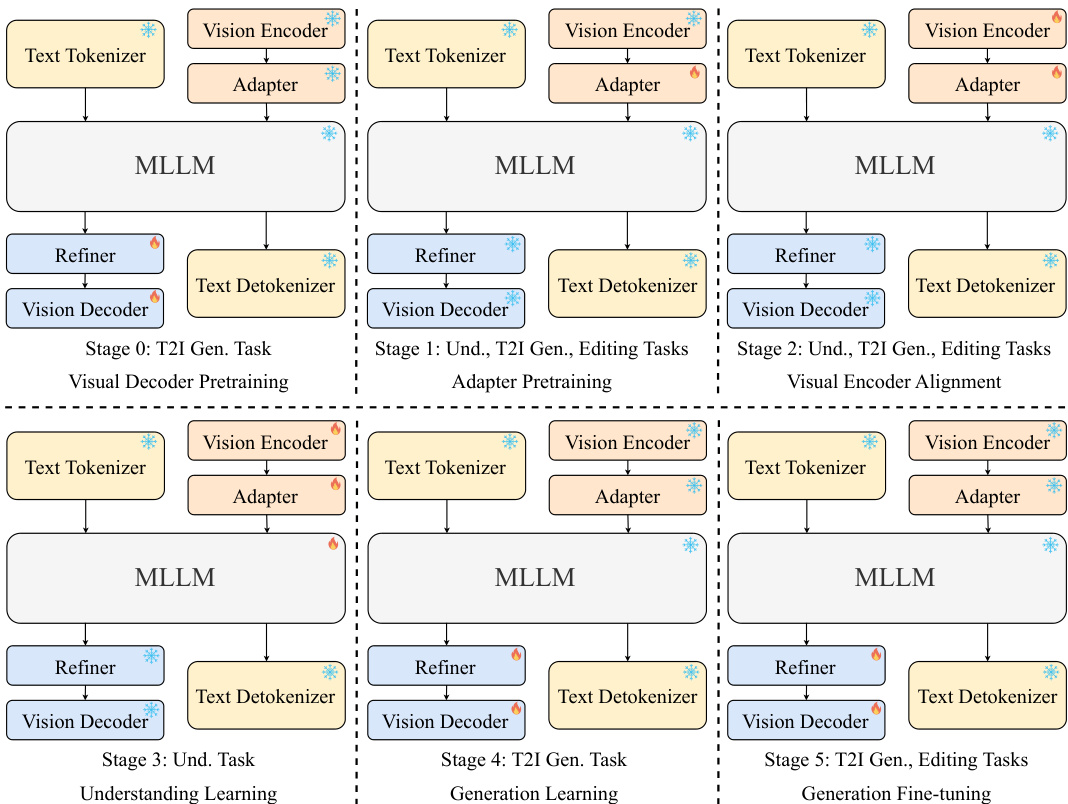
作者采用模块化架构,总参数量为 36.4 亿,其中 LLM 与视觉解码器为主要组件。模型在多个阶段进行训练,视觉编码器与精炼器在第 2、3、4、5 阶段训练,而 LLM 仅在第 3 阶段训练。

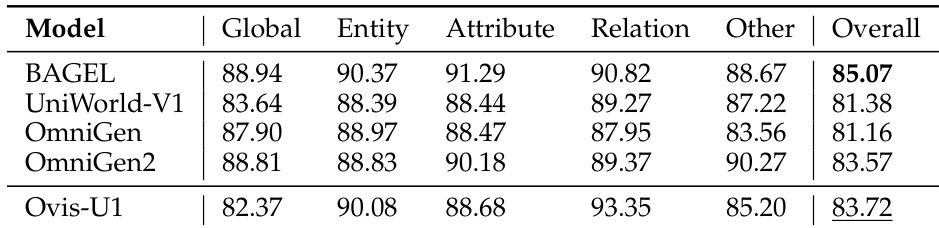
作者使用 OpenCompass 多模态学术基准评估各模型(包括 Ovis-U1)的理解能力。结果显示,Ovis-U1 总得分为 83.72,优于 BAGEL 和 UniWorld-V1,但略逊于得分为 83.57 的 OmniGen2。
作者使用 OpenCompass 多模态学术基准评估各模型(包括 Ovis-U1)的理解能力。结果显示,Ovis-U1 在所有基准上取得最高平均分 69.6,超越 GPT-4o 等更大模型,为 30 亿参数量级模型树立了新标杆。
作者使用 GEdit-Bench 与 ImgEdit 基准评估图像编辑能力,将 Ovis-U1 与多个最先进模型进行对比。结果显示,Ovis-U1 在所有编辑任务上取得最高平均分 6.420,超越 GPT-4o 和 BAGEL,展现出在处理多样化图像编辑指令方面的强大性能。
作者使用 OpenCompass 多模态学术基准评估各模型(包括 Ovis-U1)的理解能力。结果显示,Ovis-U1 在所有子任务上取得最高总分 0.89,超越 GPT-4o 和 OmniGen2。