Command Palette
Search for a command to run...
Jan-nano 技术报告
Jan-nano 技术报告
Alan Dao Dinh Bach Vu
摘要
大多数语言模型都面临一个根本性权衡:强大的能力往往需要庞大的计算资源。我们通过Jan-nano这一40亿参数的语言模型打破了这一限制——它以极致的专业化重新定义了效率:与其试图掌握一切,不如精通即时查找任何信息的本领。Jan-nano基于Qwen3-4B模型,采用我们创新的多阶段可验证奖励强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)系统进行微调,彻底摒弃了对下一词预测训练(SFT)的依赖。在集成MCP(Memory-Computation Pipeline)技术后,Jan-nano在SimpleQA基准测试中取得了83.2%的得分,同时可在消费级硬件上运行。凭借128K的上下文长度,Jan-nano证明:智能的本质不在于规模,而在于策略。
一句话总结
Menlo Research 的研究者提出了 Jan-nano,一个 4B 参数的语言模型,通过一种新颖的多阶段 RLVR 训练方法(摒弃了下一词预测),在 SimpleQA 上实现了 83.2% 的高准确率,能够在消费级硬件上以 128K 上下文高效地进行策略驱动的信息检索。
主要贡献
- Jan-nano 通过引入一个专为快速、精准信息检索而非知识记忆设计的 4B 参数语言模型,解决了模型性能与计算效率之间的长期权衡问题,使在消费级硬件上实现高能力推理成为可能。
- 该模型采用一种新颖的多阶段强化学习可验证奖励(RLVR)框架进行训练,摒弃了对下一词预测(SFT)的依赖,转而使用 DAPO 和“强制不思考”正则化,以优化简洁、正确的工具使用,避免过度思考。
- 在集成 MCP 的 SimpleQA 基准上进行评估,Jan-nano 达到 83.2% 的准确率——表现强劲,可与更大模型相媲美——同时支持 128K 上下文长度,并在本地 RAG 环境中高效运行。
引言
大型语言模型的发展长期面临高性能与计算效率之间的权衡,最先进的成果通常依赖于大型模型,难以在本地部署。先前在检索增强生成(RAG)方面的研究通过外部工具提升了推理能力,但多数工作集中于 7B+ 参数的大模型,导致小型高效模型在复杂、工具增强任务中被低估。本文作者提出 Jan-nano,一个专为高效、工具驱动推理设计的 4B 参数模型。其核心贡献是 RLVR 训练框架,一种替代传统监督微调的多阶段强化学习方法。通过使用 DAPO 进行偏好优化,并引入“强制不思考”正则化以惩罚不必要的步骤,Jan-nano 被优化为直接、准确地调用工具。在本地 RAG 环境下对 SimpleQA 进行评估,其准确率达到 83.2%,超越基线模型,媲美远大模型,证明了当策略性设计时,专用且高效的架构可在知识密集型任务中实现高性能。
数据集
- 数据集源自 MuSiQue-Ans [Trivedi 等, 2022],这是一个专为支持多跳推理而设计的问答数据集。
- 包含 10,325 个样本,按推理深度分类:7,000 个两跳问题(67.8%),2,150 个三跳问题(20.8%),1,175 个四跳问题(11.4%)。
- 该数据集因其结构化的难度递进以及包含支持段落(为每个答案提供证据)而被选中。
- 作者将该数据集作为训练数据的一部分,与其他来源混合使用,以反映不同推理复杂度。
- 未描述显式的裁剪或元数据构建,但数据已处理为与模型输入格式对齐,保留原始问题-答案对及支持证据。
方法
作者利用一种多阶段强化学习框架(带可验证奖励,RLVR)训练 Jan-nano,一个 4B 参数的语言模型,通过专用工具使用实现高性能,而非依赖传统的下一词预测训练。训练从 Qwen3-4B 出发,通过一个受控环境进行,使用 MuSiQue 数据集,并辅以本地 RAG 服务器,模拟真实搜索引擎行为。该设置使模型能够学习高效的资讯检索与整合策略,同时保持自主性。
训练过程遵循三阶段推进。第一阶段,模型学习基础工具操作与交互模式,上下文长度为 8K。此阶段的奖励函数设计用于平衡多个目标:正确答案生成、工具执行成功、响应格式合规以及 XML 结构遵循。该阶段建立工具调用与响应格式化的基础行为。如图所示,模型启动网络搜索以获取相关信息,展示了早期阶段的工具使用。

第二阶段,重点转向答案质量,模型继续在 8K 上下文下运行。奖励函数重新配置,优先考虑正确性,移除工具执行和格式遵循的激励。这促使模型优化其推理与整合能力,确保生成的回答准确且由检索信息充分支持。结构化的 XML 格式保持不变,工具通过 <tool> 标签调用,结果返回在 <result> 标签中,最终答案封装在 <answer> 标签内。这种一致格式有助于强化学习过程中的可靠解析与比较。
第三阶段将上下文长度从 8K 扩展至 40K,使模型能够处理更复杂、多步骤的查询,需要更深层次的信息整合。此阶段强调上下文扩展与重复工具调用能力,如图所示,模型执行多次获取操作以收集全面数据,再生成综合回答。训练方法确保模型发展出自主推理模式,仅需最少系统提示,从而有效应对复杂用户查询。
实验
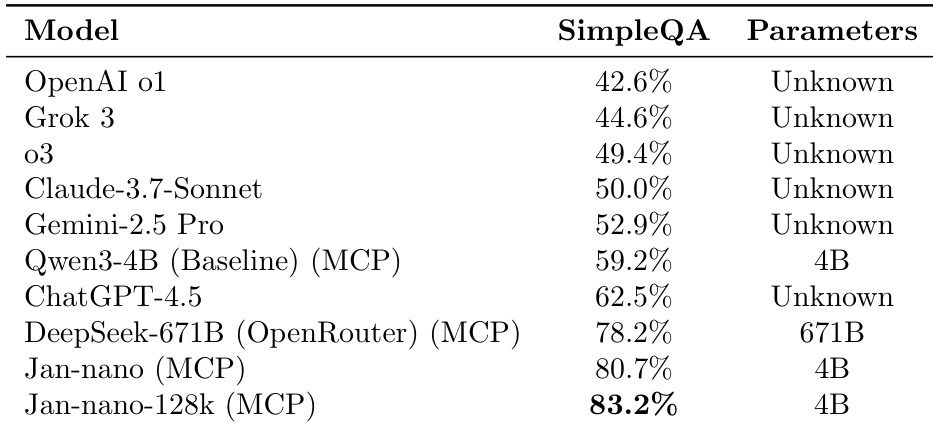
- Jan-nano 在 SimpleQA 基准上以 4B 参数实现 83.2% 的准确率,相比使用 MCP 的 Qwen3-4B 基线(59.2%)提升 24 个百分点,展现出强大的参数效率;128K 上下文版本进一步提升 2.5 个百分点,表明长上下文带来的优势。
- 使用 40K 上下文窗口训练,在保持高响应质量的同时支持更长输入处理,奖励函数聚焦于正确性与 XML 结构。
- 更大模型(8B)表现出过度思考行为,施加不必要的过滤,导致相关结果被剔除并引发幻觉,而 4B 模型的直接搜索方法实现更高准确率与可靠性。
- 禁用思考机制可显著提升响应速度,仅带来适度的准确率损失,因此采用“强制不思考”训练以优化用户体验。
- Jan-nano 在基于 LangGraph 的 ReAct 与 MCP 配置下表现优于 smolagents CodeAgent(80.7% vs 76.2%),因其与训练中使用的 JSON 工具调用模板更匹配,凸显格式兼容性在智能体系统性能中的重要性。
- 基于 MCP 的评估支持灵活、贴近现实的智能体行为测试,支持动态工具集成与真实用户体验复现,是评估自主推理的首选框架。
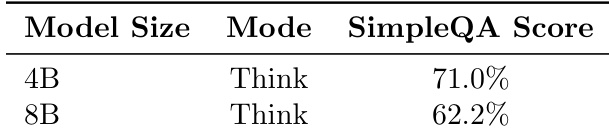
作者评估了模型规模与思考模式对 SimpleQA 基准性能的影响。结果显示,当两者均以 Think 模式运行时,4B 模型得分高达 71.0%,高于 8B 模型的 62.2%,表明大模型可能因过度思考行为导致性能下降。
作者对比了 Jan-nano 在两种智能体框架下的表现,发现 LangGraph MCP 配置的准确率(80.7%)高于 smolagents CodeAgent 设置(76.2%)。这一差异归因于与模型训练中使用的 JSON 工具调用模板更佳的对齐,凸显了格式兼容性在智能体系统性能中的关键作用。

作者使用 SimpleQA 基准评估 MCP 集成下的模型性能,结果显示 Jan-nano 以 4B 参数实现 83.2% 的准确率,相比 Qwen3-4B 基线提升 24 个百分点。该结果表明,其性能可与 DeepSeek-671B 等更大模型相竞争,同时保持极高的参数效率。