Command Palette
Search for a command to run...
DiffuCoder:理解与改进用于代码生成的掩码扩散模型
DiffuCoder:理解与改进用于代码生成的掩码扩散模型
Shansan Gong Ruixiang Zhang Huangjie Zheng Jiatao Gu Navdeep Jaitly Lingpeng Kong Yizhe Zhang
摘要
扩散型大语言模型(dLLMs)因其去噪机制能够作用于整个序列,成为自回归(AR)模型的有力替代方案。dLLMs所具备的全局规划能力与迭代优化特性,在代码生成任务中尤为突出。然而,当前针对代码任务的dLLMs在训练与推理机制方面仍处于探索阶段。为揭示dLLMs的解码行为机制,并充分释放其在代码生成中的潜力,我们系统性地研究了其去噪过程及强化学习(RL)方法。我们基于1300亿个标记的代码数据,训练了一个70亿参数的dLLM模型——DiffuCoder。以此模型为实验平台,我们深入分析了其解码行为,发现其与AR模型存在显著差异:(1)dLLMs能够在不依赖半自回归(semi-AR)解码的前提下,自主决定生成过程的因果性程度;(2)提高采样温度不仅扩大了词元选择的多样性,还改变了生成顺序的分布,从而在强化学习的轨迹采样(rollout)中构建出更为丰富的搜索空间。在强化学习训练方面,为降低词元对数似然估计的方差并保持训练效率,我们提出一种新型采样策略——耦合-GRPO(coupled-GRPO)。该方法通过为训练中使用的补全内容构造互补的掩码噪声,有效提升了训练稳定性与效率。实验结果表明,采用耦合-GRPO训练的DiffuCoder在多个代码生成基准测试中性能显著提升,尤其在EvalPlus评测中提升达+4.4%;同时,其在解码过程中对AR偏差的依赖显著降低。本研究不仅深化了对dLLM生成机制的理解,更提供了一套高效、原生适配扩散模型的强化学习训练框架。相关代码已开源:https://github.com/apple/ml-diffucoder。
一句话总结
苹果公司与香港大学的研究人员提出 DiffuCoder,这是一种 7B 参数的扩散语言模型,用于代码生成。该模型采用一种新颖的耦合-GRPO 强化学习方法,降低训练中的方差,并实现更灵活、非因果的解码。与自回归模型不同,DiffuCoder 能动态调整生成的因果性,并利用温度驱动的顺序多样性,实现更丰富的强化学习搜索,在 EvalPlus 上实现了 +4.4% 的性能提升,同时保持高效。
主要贡献
- 我们提出 DiffuCoder,一个在 1300 亿个代码 token 上训练的 7B 规模扩散语言模型,为研究和推进代码生成中的原生扩散训练方法提供了基础。
- 我们的分析表明,dLLMs 能够根据采样温度动态调整其生成策略,实现更灵活的非自回归行为——在 token 选择和生成顺序上均实现多样化,这与传统自回归模型形成鲜明对比。
- 我们提出耦合-GRPO,一种新颖的强化学习方法,通过成对互补的掩码噪声降低策略梯度估计的方差,无需依赖半自回归解码,使 DiffuCoder 的 EvalPlus 得分提升 4.4%。
引言
研究人员利用掩码扩散模型(MDMs)作为传统自回归语言模型在代码生成中的非自回归替代方案,其中整个序列的并行精炼支持全局规划——这非常适合代码开发中迭代性、非线性的过程。先前基于扩散的代码模型研究虽具潜力,但通常依赖半自回归解码策略或固定时间步,削弱了扩散模型的核心优势:真正的并行性。这些方法限制了性能提升,并偏离了预期的非自回归行为。为解决此问题,研究人员提出 DiffuCoder,一个在 1300 亿 token 上训练的 7B 规模扩散语言模型,并开发了新颖的局部与全局自回归性度量方法,用于分析解码模式。他们的分析发现,更高的采样温度促进更灵活、非自回归的生成,降低因果偏差,提升代码质量。基于这一洞察,他们提出耦合-GRPO,一种原生扩散的强化学习方法,通过耦合采样机制在不依赖半自回归解码的前提下,降低策略梯度估计的方差。该方法仅使用 2.1 万次训练样本,便在 EvalPlus 上实现 4.4% 的性能提升,证明了将强化学习与扩散模型内在并行性对齐的有效性。
方法
研究人员采用基于扩散的架构进行代码生成,建立在离散扩散模型的基本原理之上。核心框架通过前向过程 q(x1:T∣x0) 逐步破坏一个干净的输入序列 x0,在每个时间步 t 根据转移矩阵 Qt 定义的类别分布引入噪声。该过程设计为吸收过程,其中特殊 [MASK] 标记作为吸收态,确保最终的噪声状态 xT 完全被掩码。模型学习逆转此过程,通过后向过程 pθ(x0:T) 从 xt 去噪以重建 x0。参数 θ 通过最小化证据下界(ELBO)进行优化,该下界在采样时间 t 处近似为加权交叉熵损失 Lt,权重与掩码比例 t 成反比。这种连续时间形式使模型能够在一系列掩码 token 上运行,支持非自回归生成过程。
该模型的训练流程分为四个不同阶段,如框架图所示。第一阶段为适应预训练,涉及在大规模代码语料库上持续预训练,以建立强基础模型。随后是中期训练阶段,作为退火阶段,连接预训练与后训练阶段。第三阶段为指令微调,模型在较小的指令遵循示例数据集上进行微调,以增强其理解与执行用户指令的能力。最后一阶段为后训练,采用一种新颖的强化学习方法——耦合-GRPO,进一步优化模型在代码生成任务上的性能。这种多阶段方法使模型能力得以逐步提升,从通用代码理解过渡到特定指令执行。
研究人员将扩散过程重新解释为马尔可夫决策过程(MDP),以支持强化学习。在此框架中,状态 st 定义为 (c,t,xt),其中 c 为条件(如代码提示),t 为当前扩散时间步,xt 为部分掩码序列。动作 at 为对前一个 token xt−1 的预测。策略 πθ(at∣st) 为模型在给定当前状态下生成 xt−1 的概率。奖励函数 R(s0,a0) 在最终去噪步骤定义,基于生成序列 x0 与条件 c 的质量。该 MDP 框架允许应用策略梯度方法(如 GRPO)来优化模型策略。
研究人员提出一种名为耦合-GRPO 的新型强化学习算法,以应对扩散模型训练的挑战。其核心创新在于一种耦合采样机制,为训练中使用的补全构建互补的掩码噪声。该机制选择一对时间步 (t,t^),满足 t+t^=T。对于每一对,生成两个互补掩码:一个隐藏部分 token,另一个隐藏剩余 token,确保每个 token 在两个前向传播中恰好有一个未被掩码。该设计保证每个 token 的对数概率至少被计算一次,提供非零学习信号,降低概率估计的方差。耦合-GRPO 损失函数结合标准 GRPO 目标与 KL 惩罚项,以保持更新后的策略接近参考策略,并使用耦合概率估计计算策略梯度更新的重要性比率。该方法显著提升了模型在代码生成基准上的性能,并降低了解码过程中对自回归偏差的依赖。
实验
- 比较了不同 dLLMs(从零训练的 LLaDA 与从 AR LLMs 适配的 Dream/DiffuCoder)、数据模态(数学与代码)及训练阶段;发现 dLLMs 展现出灵活解码,具有较低但非零的自回归性(AR-ness),而适配模型因继承左到右依赖关系,表现出更高的 AR-ness。
- 在 GSM8K(8-shot)上,DiffuCoder 达到 85.2% 准确率,超过 LLaDA(82.1%)和 Dream(83.4%);在 HumanEval(零样本)上,达到 72.3% pass@1,优于 Dream(69.8%)和 LLaDA(70.1%)。
- 代码生成的全局 AR-ness 均值较低、方差较高,表明更具全局规划行为,与程序员式的 token 生成模式一致。
- AR-ness 在后期训练阶段(700B token)上升,但性能下降,因此选择 65B token 的 Stage 1 模型作为基础;中期训练与指令微调降低 AR-ness 并提升性能。
- 耦合-GRPO 训练进一步降低 AR-ness 并实现更快解码:DiffuCoder-Instruct 在 2 倍速度下仅下降 4.2% 性能(对比指令微调基线的 10.1%),表明并行性显著提升。
- 更高的采样温度(1.0–1.2)显著提升生成多样性(pass@k 显著上升)并降低 AR-ness,实现更非自回归、并行的解码,而 AR 模型中温度仅影响 token 选择。
- 熵 sink 现象——表现为 L 形置信度分布——揭示了对局部邻近 token 的偏好,解释了尽管解码灵活但仍存在残余 AR-ness 的原因。
- DiffuCoder-Instruct 在耦合-GRPO 后于 HumanEval 达到 74.1% pass@1,pass@k 从 k=1 时的 72.3% 提升至 k=10 时的 81.6%,表明其具有强大的潜在多样性,有利于强化学习增强。
结果表明,更高的采样温度在基础模型和指令模型中均降低 AR-ness,表明生成方式向更少序列化、更多并行化转变。AR-ness 的下降与生成多样性提升相关,表现为在更高温度下 pass@k 分数显著提高,尤其在代码基准上表现明显。
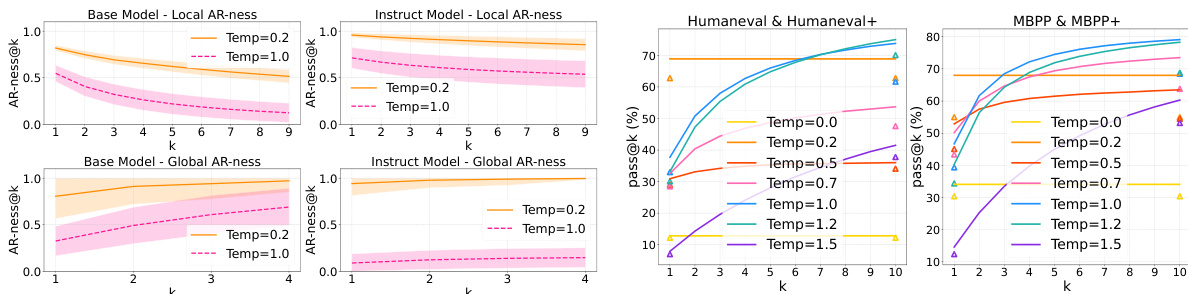
研究人员分析了 DiffuCoder 在不同训练阶段中 AR-ness 的演变,显示在指令微调和 GRPO 训练期间,局部与全局 AR-ness 均下降。GRPO 后,模型表现出更低的 AR-ness 和在双倍速度解码时更小的性能下降,表明并行性得到改善。
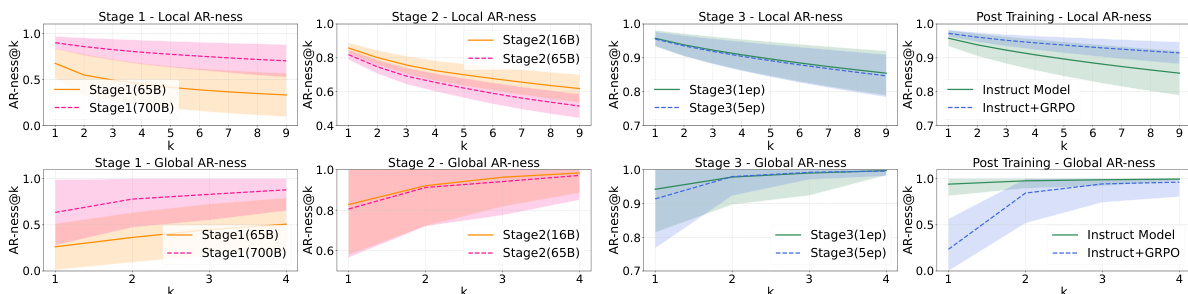
结果表明,提高采样温度可提升基础模型和指令模型在 HumanEval 上的 pass@k 分数,表明生成多样性增强。更高温度还降低 AR-ness,使模型以更非序列化的方式生成 token,相比低温度更具灵活性。
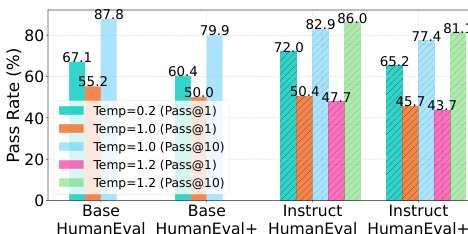
结果表明,DiffuCoder-Instruct 在 HumanEval 和 MBPP 基准上表现具有竞争力,耦合 GRPO 在多个指标上提升了 pass@k 分数。模型性能进一步通过提高采样温度得到增强,该操作降低 AR-ness,实现更丰富且可并行化的生成。
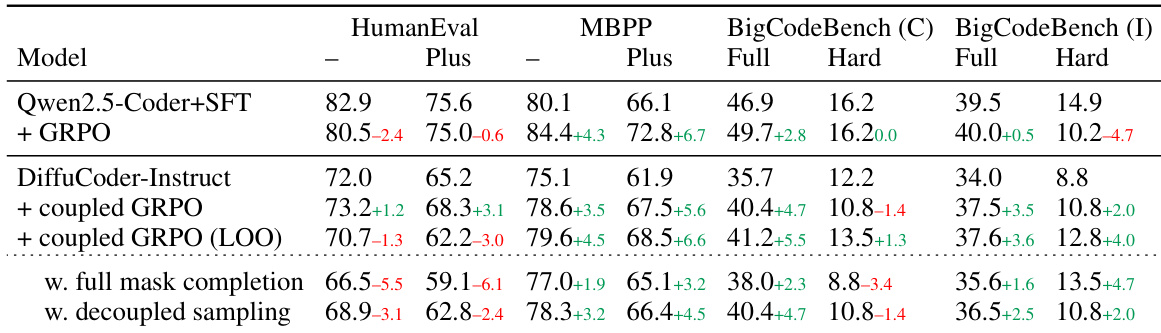
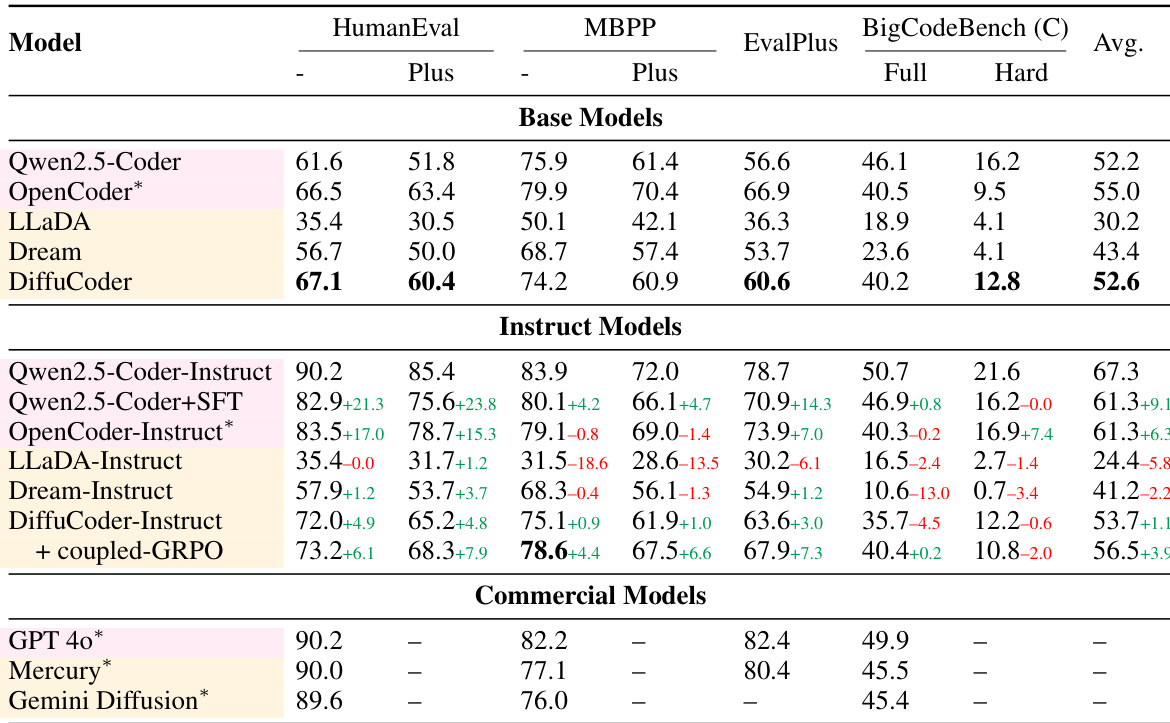
研究人员使用表格比较了多种基于扩散的语言模型(dLLMs)与自回归(AR)模型在编码基准上的表现。结果显示,DiffuCoder 在基础模型中取得最高平均分,显著优于 LLaDA 和 Dream;指令微调进一步提升性能,尤其是 DiffuCoder-Instruct,在多数任务上超越其他模型。表格还表明,将 GRPO 训练与指令微调结合可获得最佳整体结果,DiffuCoder-Instruct + 耦合-GRPO 在 HumanEval、MBPP 和 BigCodeBench 上均取得最高分数。