Command Palette
Search for a command to run...
FLUX.1 上下文:用于潜在空间中上下文图像生成与编辑的流匹配
FLUX.1 上下文:用于潜在空间中上下文图像生成与编辑的流匹配
摘要
我们展示了FLUX.1 Kontext的评估结果。FLUX.1 Kontext是一种生成式流匹配模型,能够统一图像生成与图像编辑任务。该模型通过融合文本和图像输入中的语义上下文,生成新颖的输出视角。采用简单的序列拼接方法,FLUX.1 Kontext在单一统一架构中同时支持局部编辑与生成式上下文任务。相较于当前主流编辑模型在多轮交互中普遍存在角色一致性与稳定性下降的问题,FLUX.1 Kontext在对象与角色的保留方面表现出显著提升,从而在迭代式工作流中展现出更强的鲁棒性。该模型在保持与当前最先进系统相当性能的同时,实现了显著更快的生成速度,为交互式应用与快速原型设计流程提供了有力支持。为验证上述改进,我们提出了KontextBench——一个涵盖1026组图像-提示对的综合性基准测试集,覆盖五大任务类别:局部编辑、全局编辑、角色参考、风格参考与文本编辑。详细评估结果表明,FLUX.1 Kontext在单轮生成质量与多轮一致性方面均表现优异,为统一图像处理模型设立了新的性能标准。
一句话总结
黑森林实验室的作者提出了 FLUX.1 Kontext,这是一种统一的生成流匹配模型,通过简单的序列拼接实现图像生成与编辑,能够实现稳健的多轮一致性,并在推理速度上优于以往模型,在 KontextBench 上的本地与全局编辑、角色与风格参考、文本编辑等任务中均表现出色。
主要贡献
-
FLUX.1 Kontext 解决了在多次迭代编辑中保持角色与物体一致性的挑战,这是当前生成式图像编辑系统的关键局限,常因视觉漂移和身份保真度下降而影响故事驱动或品牌敏感型工作流。
-
该模型引入统一的流匹配架构,通过简单的序列拼接处理文本与图像输入,实现本地编辑、全局修改、风格迁移和文本驱动生成的无缝集成,仅需单次快速推理,无需参数更新或微调。
-
在 KontextBench——一个包含 1026 个图像-提示对、覆盖五个任务类别的新基准——上评估,FLUX.1 Kontext 在单轮图像质量与多轮一致性方面均达到最先进水平,且在 1024×1024 分辨率下生成时间仅为 3–5 秒,适用于交互式与快速原型开发场景。
引言
作者利用潜在空间中的流匹配技术,实现上下文感知的图像生成与编辑,以应对从叙事创作、电商到品牌资产管理等应用中日益增长的直观、准确且交互式视觉内容生成需求。以往方法虽在单次编辑中表现良好,但在多轮迭代中存在角色漂移、推理速度慢以及依赖合成训练数据导致真实感与一致性受限的问题。主要贡献为 FLUX.1 Kontext,一种基于流的统一模型,通过在拼接的上下文与指令序列上进行速度预测训练,实现了高保真度、多轮编辑中角色一致性以及每张 1024×1024 图像 3–5 秒的交互式推理速度。该模型支持低视觉漂移的迭代式、指令驱动工作流,适用于叙事生成与产品编辑等复杂创意任务,并通过 KontextBench 进行评估,该基准包含 1026 个真实世界图像-提示对。
数据集
- 数据集 KontextBench 由 1,026 个唯一图像-提示对组成,源自 108 张来自多样化真实场景的底图,包括个人照片、CC 许可艺术作品、公共领域图像及 AI 生成内容。
- 涵盖五大核心任务:局部指令编辑(416 例)、全局指令编辑(262 例)、文本编辑(92 例)、风格参考(63 例)和角色参考(193 例),确保对实际上下文编辑场景的广泛覆盖。
- 作者使用 KontextBench 评估模型性能,完整数据集作为人类评估与基准测试的测试集。数据未划分为训练与验证集,因重点在于评估真实世界适用性而非模型训练。
- 未描述显式裁剪或图像预处理,但数据集强调真实世界使用场景,提示与编辑通过众包收集,以反映真实用户行为。
- 元数据围绕任务类型、图像来源与编辑范围构建,支持对不同编辑模态下模型性能的细粒度分析。
- 该基准旨在支持可靠的人类评估,并随 FLUX.1 Kontext 样本与基线结果一同发布,以支持可复现性与社区使用。
方法
作者采用在卷积自编码器潜在空间中训练的修正流变换器架构,基于 FLUX.1 模型构建。整体框架如高层概览所示,整合文本与图像条件以生成目标图像。模型首先使用冻结的自编码器将输入图像编码为潜在标记,随后与文本标记一同处理。架构采用混合块设计:初始部分由双流块组成,图像与文本标记分别处理并使用独立权重,其表示通过拼接序列上的注意力机制融合;随后是一系列 38 个单流块,处理融合后的图像与文本标记。处理完成后,文本标记被丢弃,剩余图像标记被解码回像素空间。
为提升计算效率,模型采用受 Dehghani 等人启发的融合前馈块,减少调制参数,并将注意力与 MLP 线性层融合,以支持更大的矩阵-向量运算。模型引入分解的三维旋转位置嵌入(3D RoPE),为每个潜在标记编码空间与时间信息,位置由 (t,h,w) 索引。对于上下文图像,其位置嵌入应用恒定偏移,将其视为发生在虚拟时间步,从而清晰分离上下文与目标图像标记,同时保留其内部空间结构。
训练目标为修正流匹配损失,优化模型预测目标图像与噪声之间线性插值潜在空间的速度场。该损失定义为预测速度与真实速度之间平方差的期望。时间步 t 从逻辑正态分布中采样,其中模式 μ 根据数据分辨率调整。在采样阶段,模型可基于文本提示与可选的上下文图像生成图像,支持图像驱动编辑与自由文本到图像生成。模型在关系对 (x∣y,c) 上训练,其中 x 为目标图像,y 为上下文图像,c 为文本提示。训练从预训练的文本到图像检查点开始,联合微调图像到图像与文本到图像任务。
实验
- FLUX.1 Kontext 通过单一架构验证了统一的图像生成与编辑能力,在迭代工作流中相比现有模型展现出更优的角色与物体一致性。
- 在包含 1026 个图像-提示对、覆盖五类任务(局部编辑、全局编辑、角色参考、风格参考、文本编辑)的 KontextBench 基准上,FLUX.1 Kontext [pro] 在文本编辑与角色保留方面表现最佳,FLUX.1 Kontext [max] 在通用角色参考任务中领先,并在计算效率上相比竞争对手最高提升一个数量级。
- 在图像到图像任务中,FLUX.1 Kontext [max] 与 [pro] 在局部编辑与角色参考方面达到最先进水平,AuraFace 相似度得分证实了面部一致性的提升。
- 在 Internal-T2I-Bench 与 GenAI Bench 的文本到图像评估中,FLUX.1 Kontext 在提示遵循、美学、真实性、排版准确性与速度方面表现均衡,优于 FLUX1.1 [pro],且从 [pro] 到 [max] 逐步提升,同时避免了其他模型常见的“烘焙感”问题。
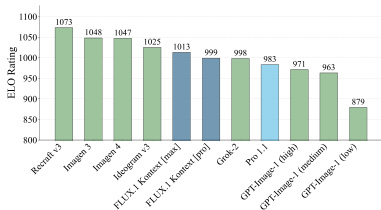
结果显示,FLUX.1 Kontext [pro] 在评估模型中获得最高 ELO 评分,超越 GPT-Image-1 和 Recraft-3 等竞争模型。作者利用此排名证明该模型在图像生成与编辑任务中的卓越性能,尤其在多样输入下保持一致性和质量方面表现突出。
结果显示,FLUX.1 Kontext [pro] 在评估模型中获得最高 ELO 评分,超越 Recraft v3 和 ImageGen 3 等竞争模型。该模型在编辑任务中表现强劲,文本编辑与角色保留得分最高,评估结果充分反映其性能优势。

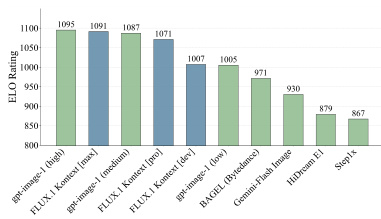
结果显示,FLUX.1 Kontext [pro] 在评估模型中获得最高 ELO 评分,超越 Recraft 3、Imagen 3 和 GPT-Image-1(中等)等竞争模型。该模型在文本编辑与角色保留方面表现优异,与其统一图像生成与编辑任务的设计目标一致。
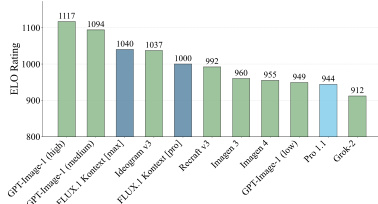
结果显示,FLUX.1 Kontext [max] 在所有评估模型中获得最高 ELO 评分,超越 gpt-image-1 和 Gen-4 等竞争模型。该模型在图像到图像任务中表现卓越,尤其在文本编辑与角色参考方面表现突出,多个评估类别中均位居榜首。
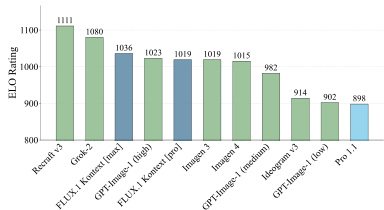
结果显示,FLUX.1 Kontext [max] 在图像到图像评估中获得 1080 的最高 ELO 评分,超越 Recraft v3 和 GPT-Image-1(tigh)等其他模型。作者使用 KontextBench 在多个编辑任务中评估性能,FLUX.1 Kontext [pro] 始终位列顶尖,尤其在文本编辑与角色保留方面表现卓越。