Command Palette
Search for a command to run...
Surfer-H 与 Holo1 的融合:基于开源权重的低成本网络代理
Surfer-H 与 Holo1 的融合:基于开源权重的低成本网络代理
摘要
我们提出 Surfer-H,一种成本高效的网络代理(web agent),通过集成视觉-语言模型(Vision-Language Models, VLM)来执行用户定义的网络任务。我们将其与 Holo1 配套使用,Holo1 是一套全新的开源权重视觉-语言模型集合,专为网络导航与信息提取任务而设计。Holo1 在精心筛选的数据源上进行训练,包括开放获取的网络内容、合成样本以及自生成的智能体数据(agentic data)。在通用用户界面(UI)基准测试以及我们新提出的网页UI定位基准测试 WebClick 上,Holo1 均取得领先表现。在 Holo1 的驱动下,Surfer-H 在 WebVoyager 基准测试中实现了 92.2% 的当前最优性能,实现了准确率与成本效益之间的帕累托最优(Pareto-optimal)平衡。为加速智能体系统领域的研究进展,我们已开源 WebClick 评估数据集及 Holo1 模型权重。
一句话总结
作者提出 Surfer-H,一种成本高效的网络代理,利用新发布的开放权重视觉语言模型 Holo1——该模型在精心筛选的网络和合成数据上训练——实现准确、可扩展的网页导航与信息提取,在 WebVoyager 基准上达到 92.2% 的最先进准确率,同时通过开源数据集和模型权重加速研究进程。
主要贡献
-
Surfer-H 是一种成本高效的网络代理,通过视觉交互实现用户自定义的网络任务,利用视觉语言模型(VLMs)无需依赖 DOM 或可访问性树,采用模块化架构结合策略、定位器和验证器,实现实时、类人化的网页导航。
-
作者提出 Holo1,一个在精心筛选数据(包括开放网络内容、合成样本和自产代理数据)上训练的开放权重 VLM 家族,在通用 UI 基准和专为网页特定 UI 定位挑战(如动态日历和嵌套菜单)设计的 WebClick 基准上均达到最先进性能。
-
在集成 Holo1 后,Surfer-H 在 WebVoyager 基准上实现 92.2% 的成功率,创下新纪录,同时在准确率与成本效率之间保持帕累托最优,Holo1 模型权重与 WebClick 数据集均已开源,以加速代理系统研究。
引言
作者利用大型视觉语言模型(VLMs)构建 Surfer-H,一种通过视觉界面与网站交互而非依赖 API 或 DOM 访问的成本高效网络代理。该方法对于创建能够执行真实世界网络任务(如预订行程或获取最新信息)的通用代理至关重要,且无需定制集成。以往基于 LLM 的代理受限于对预定义工具的依赖和高昂的工程开销,而基于 GUI 的代理在准确 UI 定位方面,尤其在复杂动态网页元素上表现不佳。为解决此问题,作者提出 Holo1,一个轻量级 VLM 家族,其在精心筛选的网络数据(包括合成和代理交互)上训练,擅长动作执行与 UI 定位。作者进一步提出 WebClick,一个专为网页特定 UI 挑战设计的新基准,证明 Holo1 在网页检索任务中实现最先进性能,且具备更优的成本效率。
数据集
-
Surfer-H 的训练数据集是一个大规模、多源混合数据集,旨在实现深度网页理解与跨多样化界面的精确状态到动作映射。该数据集融合真实网页、合成 UI、文档可视化以及代理生成的行为轨迹,构成泛化能力的全面基础。
-
数据集由三个主要部分组成:
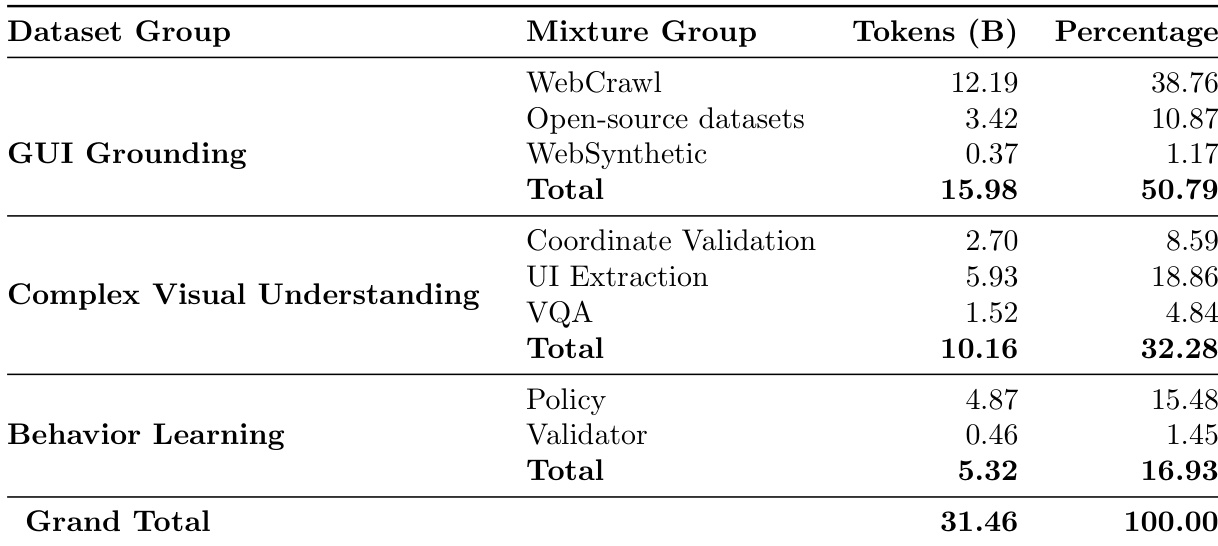
- GUI 基础(占 token 的 50.79%):基于网络爬取页面和专有合成数据构建,核心部分包含来自 400 万真实网页的 8900 万次点击,意图标签由前沿模型生成。通过自定义合成网站(如日历)、关系型表格和图标导向数据集进行增强,以解决模型已知弱点。
- 复杂视觉理解(占 token 的 32.28%):包含 500 万个坐标验证三元组,用于意图到位置对齐;近 700 万个页面用于全面的 UI 元素提取(可点击、可选择、可输入);以及来自公开和内部 VQA 数据集的 30 万张图像,聚焦图表、仪表板、表格和密集报告,总计 1.5 亿 token。
- 多模态轨迹上的行为学习(占 token 的 16.93%):源自代理执行轨迹,其中 15.48% 来自成功代理轨迹(FBC 过滤),1.45% 来自代理答案与任务证据的评估。轨迹来自两个语料库:WebVoyager(15 个站点上的 643 项任务)和 WebVoyagerExtended(330 个站点上的 1.5 万项任务),通过合成任务生成提升多样性。
-
数据经过处理以支持多模态推理:每个训练样本包含截图、意图和精确交互坐标。在 UI 提取方面,模型训练为利用视觉 affordance 而非仅 OCR 识别可交互元素。坐标验证数据采用 Set-of-Marks 方法评估定位准确性。代理轨迹结构化为(思考、笔记、动作)对序列,基于过往观察和动作,支持记忆感知的策略学习。
-
模型使用这些数据集的混合进行训练,采用基于 token 的加权方式反映其贡献。训练划分采用完整混合数据,合成与真实数据平衡以增强鲁棒性。WebClick 基准源自代理与人类交互(包括日历相关任务),用于评估定位性能并跟踪在真实网络交互挑战上的进展。
方法
作者为 Surfer-H 设计了一种模块化架构,该网络代理通过与网页界面交互执行用户定义任务。系统通过感知、决策与动作执行的循环运行,包含三个主要可训练组件:策略、定位器和验证器。如图所示,代理首先接收任务,该任务与最近的截图、思考、笔记及当前浏览器状态一起存储在内部记忆中。策略(一种视觉语言模型 VLM)处理此记忆,生成思考并从有限动作空间中选择下一步动作,动作包括点击、输入、滚动、等待、刷新、跳转至 URL 或返回答案。当动作需要与网页上特定元素(如按钮或输入框)交互时,策略提供目标的文本描述。定位器随后处理该描述与当前截图,确定元素的精确二维坐标,从而实现点击或输入动作的准确执行。动作在浏览器中执行后,结果状态以新截图形式捕获,并加入记忆以供后续步骤使用。
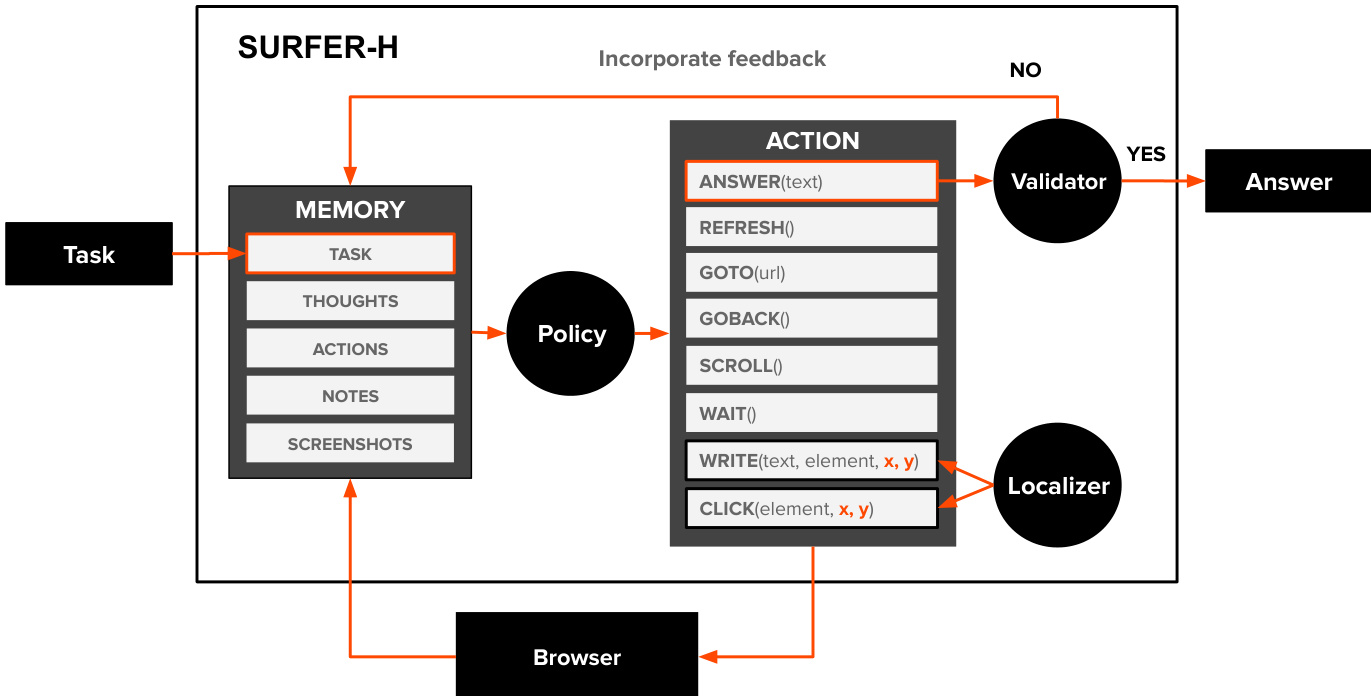
若策略判断任务已完成,则通过 ANSWER 动作生成答案。该答案随后传递给验证器,另一个 VLM 组件,其根据任务描述和近期轨迹中的支持截图评估答案的正确性。验证器输出一个布尔值表示成功,并附带自然语言解释以说明判断依据。若答案通过验证,代理终止并返回答案给用户。否则,反馈被纳入代理记忆,代理继续执行。代理在步数限制下运行,确保即使任务未完成也能终止。策略、定位器和验证器可使用通用基础模型或专用模型实现,作者引入 Holo1,一个专为网页导航与信息提取训练的新开放权重 VLM 集合,以驱动这些模块。
实验
- 在 Screenspot、Screenspot-V2、Screenspot-Pro、GroundUI-Web 和 WebClick 等定位基准上评估 Holo1 模型;Holo1-3B 和 Holo1-7B 在各自规模下均达到最先进平均定位性能,分别得分为 73.55% 和 76.16%,优于 Qwen2.5-VL-3B、UGround-V1-2B、UI-TARS-2B,甚至比 Qwen2.5-VL-7B 高出 4.23 个百分点。
- Holo1-7B 在两个 Screenspot 基准和两个 WebClick 数据集上超越 UGround-V1-7B,尽管在 GroundUI-Web 上略有下降(78.50%),仍取得 76.19% 的最高平均得分。
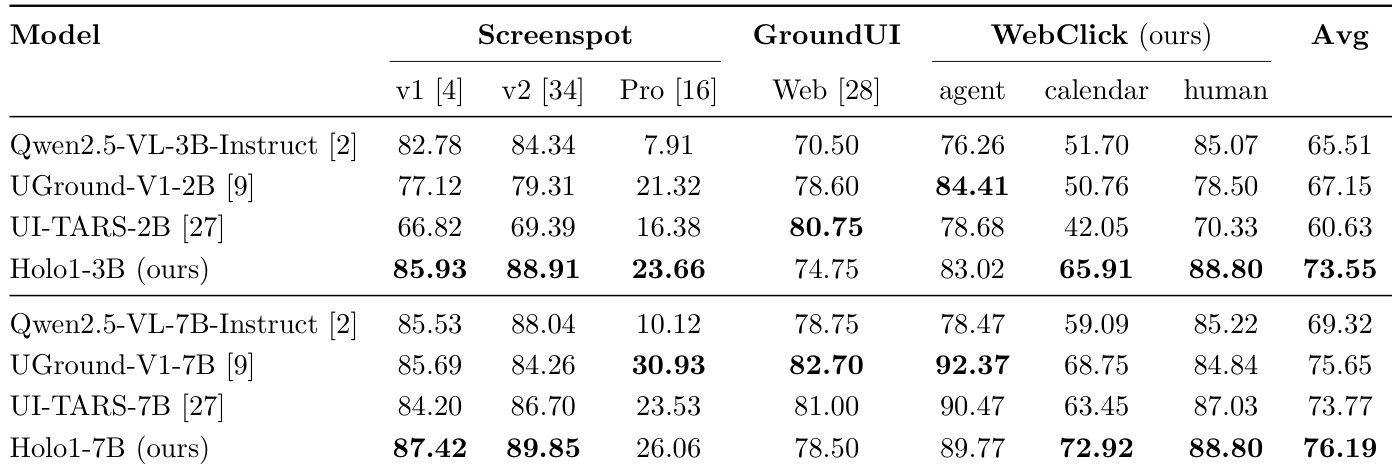
- 在 WebVoyager 基准中,由 Holo1-7B 驱动的 Surfer-H 在 10 次尝试后达到 92.2% 的成功率,与 GPT-4.1 的 92.0% 性能相当,但成本显著降低至每任务 0.13,远低于GPT−4.1的0.54。
- Holo1-3B 和 Holo1-7B 在 5 次尝试后优于外部基线 BrowserUse、Project Mariner 和 OpenAI Operator,10 次尝试后与 BrowserUse 性能持平。
- 使用 Holo1 作为验证器虽降低开销,但性能下降 12–16 个百分点,表明验证任务比策略或定位任务更具挑战性。
- 在领域内 WebVoyagerExtended 数据上训练的 Holo1-7B-WVE 比 Qwen2.5-VL-7B-Instruct 提升 9.5 个百分点,比 Holo1-7B 提升 4.5 个百分点,证明针对性微调与跨领域探索的显著优势。
作者使用 WebVoyager 基准评估 Surfer-H 在不同策略与验证器模块下的表现,结果表明基于 Holo1 的代理在显著更低成本下实现高准确率,优于 GPT-4。结果显示,由 Holo1-7B 驱动的 Surfer-H 在 10 次尝试后达到 92.2% 的准确率,每任务成本为 $0.13,性能超越 GPT-4.1,且成本效率更高。
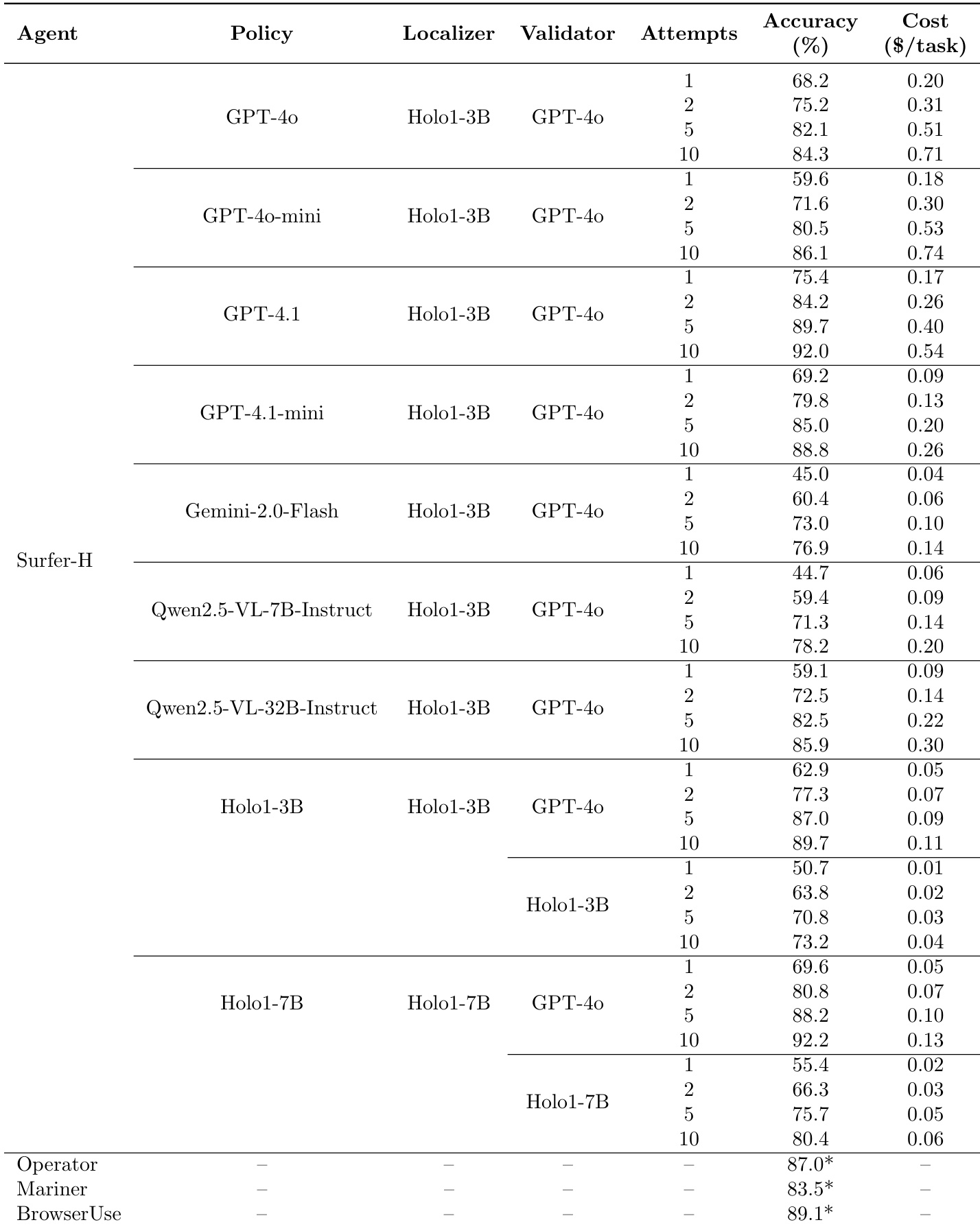
作者使用表格对比其 Holo1 模型与多个最先进模型在多个基准上的定位性能。结果显示,Holo1-3B 在 2B 和 3B 模型中取得最高平均得分 73.55%,优于 Qwen2.5-VL-3B 和 UGround-V1-2B;Holo1-7B 取得最高平均得分 76.19%,尽管在 GroundUI 上略有下降,但在多数基准上仍超越 UGround-V1-7B。
作者使用表格详细说明其训练混合数据的构成,显示 GUI 基础占比最大,达 50.79%,主要由 WebCrawl 数据驱动。混合数据还包括复杂视觉理解(32.28%)和行为学习(16.93%)的显著贡献,其中策略是行为学习中的主导组件。
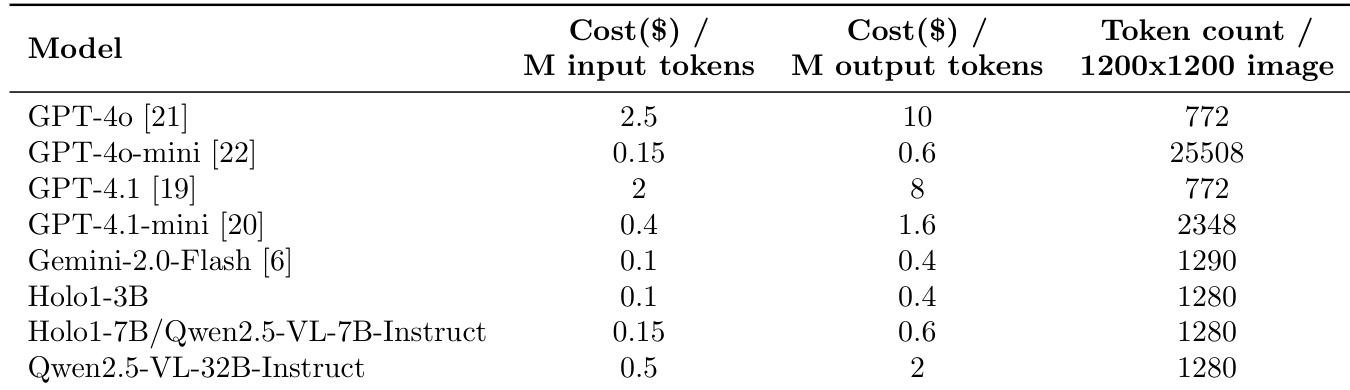
作者使用提供的表格比较各模型的推理成本,显示 Holo1-3B 和 Holo1-7B/Qwen2.5-VL-7B-Instruct 的输入与输出 token 成本均较低,Holo1-3B 每百万输入 token 成本为 0.1 美元,每百万输出 token 成本为 0.4 美元。结果表明,Holo1-3B 和 Holo1-7B/Qwen2.5-VL-7B-Instruct 是最具成本效益的模型之一,其每张 1200x1200 图像的 token 数量与其他模型相当,表明其在视觉任务处理上具有高效性。
作者使用 WebVoyager 基准评估 Surfer-H 在不同策略训练任务与模块下的表现,结果显示,Holo1-7B 在同时训练 WebVoyager 与 WebVoyagerExtended 数据时,WebVoyager 准确率最高,达 92.2%。该性能比 Qwen2.5-VL-7B-Instruct 基线高出 14 个百分点,证明结合领域内与跨领域训练对提升代理性能具有显著优势。
