Command Palette
Search for a command to run...
OmniConsistency:从成对的风格化数据中学习风格无关的一致性
OmniConsistency:从成对的风格化数据中学习风格无关的一致性
Song Yiren Liu Cheng Shou Mike Zheng
摘要
扩散模型在图像风格化任务中取得了显著进展,然而仍面临两大核心挑战:(1)在复杂场景中保持风格的一致性,尤其在身份特征、构图结构以及细节表现方面;(2)在使用风格LoRA的图像到图像生成流程中,防止风格退化。GPT-4o所展现出的卓越风格一致性,凸显了开源方法与专有模型之间的性能差距。为弥合这一差距,我们提出OmniConsistency——一种基于大规模扩散Transformer(DiTs)的通用一致性增强插件。OmniConsistency的主要贡献包括:(1)一种基于对齐图像对的上下文一致性学习框架,具备强大的泛化能力;(2)一种两阶段渐进式学习策略,将风格学习与一致性保持解耦,有效缓解风格退化问题;(3)一种完全即插即用的设计,可在Flux框架下兼容任意风格LoRA。大量实验表明,OmniConsistency显著提升了图像的视觉连贯性与美学质量,其性能已接近商业领先模型GPT-4o的水平。
一句话总结
新加坡国立大学 Show 实验室的作者提出了 OmniConsistency,这是一种即插即用的基于扩散 Transformer 的框架,通过结合上下文一致性学习与两阶段渐进式训练策略,实现了在多样化场景和未见风格 LoRA 下的风格一致性图像风格化,显著减少了风格退化,并达到了 GPT-4o 水平的性能。
主要贡献
- OmniConsistency 通过引入基于对齐图像对训练的上下文一致性学习框架,解决了复杂图像到图像风格化中长期存在的风格不一致与退化问题,实现了在无需针对特定风格重新训练的情况下,对多样化风格的鲁棒泛化能力。
- 该方法采用两阶段渐进式学习策略,将风格学习与一致性保持解耦,并结合轻量级一致性 LoRA 模块与条件令牌映射机制,有效缓解了风格退化问题,同时保持了高计算效率。
- 在新构建的包含 22 种多样化风格的数据集上进行的广泛评估表明,OmniConsistency 在风格一致性和内容一致性方面均达到最先进水平,其输出质量在各类基准测试中可与商业模型 GPT-4o 相媲美。
引言
扩散模型已成为图像风格化领域的主导力量,尤其是基于 Transformer 的架构(如 DiT)在保真度和提示对齐方面表现出色。然而,现有方法在使用风格 LoRA 的图像到图像流水线中,难以在复杂场景下维持一致的风格化——尤其是在保持身份、构图和细节方面。一个关键限制是来自 ControlNet 等模块的结构约束导致的风格退化,这削弱了风格化质量和连贯性。作者提出了 OmniConsistency,一种基于扩散 Transformer 的即插即用一致性模块,通过两阶段渐进式训练策略将风格学习与一致性保持解耦。该方法利用成对风格化数据的上下文学习能力,引入滚动 LoRA 银行加载器、轻量级一致性 LoRA 模块和条件令牌映射机制,以提升泛化能力与效率。该方法实现了对多样化及未见风格的风格无关一致性,性能可媲美 GPT-4o 等专有模型,并发布了基于 GPT-4o 的新基准数据集与评估协议,以实现标准化评估。
数据集
- 数据集完全通过 GPT-4o 驱动生成,使用公开获取且合法合规的输入图像,并经过精心筛选。
- 针对 22 种不同艺术风格(如动漫、素描、Q版、像素艺术、水彩、油画、赛博朋克等),GPT-4o 生成风格化图像版本,并为原始图像与风格化图像分别提供描述性文本注释。
- 通过人机协同过滤流程,审查超过 5,000 对候选图像对,剔除存在性别不匹配、年龄或肤色错误、细节失真、姿态不一致、风格不统一或布局错位等问题的样本。
- 过滤后,每种风格保留 80 至 150 对高质量图像对,最终形成 2,600 对经验证的图像对数据集。
- 每种风格的输入图像保持互斥,以确保多样性,包括多人肖像等复杂场景。
- 数据集用于混合风格训练,每种风格在训练混合中的贡献比例根据其在筛选集中的代表性进行分配。
- 未进行图像裁剪,而是保留原始图像尺寸以维持结构保真度。
- 在生成过程中构建元数据,包括风格标签、源图像标识符和注释一致性检查,用于指导训练与评估。
方法
作者采用两阶段训练流程与一组模块化组件,实现图像风格化中鲁棒的风格无关一致性。整体框架如图所示,由风格学习阶段与一致性学习阶段组成,旨在将风格适应与结构保持解耦。第一阶段在专用数据集上训练独立的 LoRA 模块,以捕捉独特的风格特征,形成风格 LoRA 银行。第二阶段在相同成对数据上训练一致性 LoRA 模块,训练过程中动态切换预训练的风格 LoRA 模块,以优化跨多样化风格的内容完整性。该解耦策略避免了风格与一致性目标之间的干扰,提升了泛化能力。
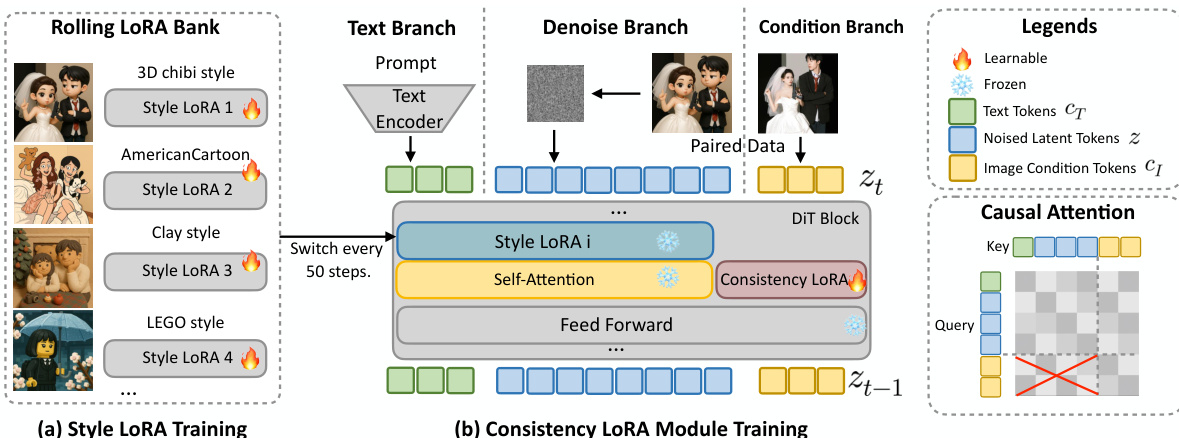
该框架引入两个关键的架构组件以提升解耦性与效率。第一个是一致性 LoRA 模块,它通过专用于扩散 Transformer 条件分支的低秩适配路径注入条件相关信息。该设计将一致性学习与风格化路径隔离,确保兼容性并防止参数纠缠。形式上,给定文本、噪声和条件分支的输入特征 Zt、Zn 和 Zc,标准的 QKV 投影定义为 Qi=WQZi、Ki=WKZi 和 Vi=WVZi,其中 i∈{t,n,c}。为注入条件信息,LoRA 变换仅应用于条件分支,得到 ΔQc=BQAQZc、ΔKc=BKAKZc 和 ΔVc=BVAVZc,其中 A 和 B 为低秩适配矩阵。条件分支的更新后 QKV 为 Qc′=Qc+ΔQc、Kc′=Kc+ΔKc 和 Vc′=Vc+ΔVc,而文本与噪声分支保持不变。这确保了与一致性相关的适配以隔离方式引入,不会干扰主干的风格化能力。
第二个架构组件是位置感知插值与特征复用机制。为提升计算效率,框架采用条件令牌映射(CTM)机制,利用低分辨率条件图像引导高分辨率生成。给定原始分辨率 (M,N) 与条件分辨率 (H,W),定义缩放因子 Sh=M/H 与 Sw=N/W。下采样条件图像中的每个令牌 (i,j) 映射到高分辨率网格中的位置 (Pi,Pj),其中 Pi=i⋅Sh 与 Pj=j⋅Sw,以保持像素级对应关系。此外,通过在推理过程中缓存条件令牌的中间键值投影,并在去噪步骤间复用,实现特征复用,显著降低推理时间与 GPU 内存占用,同时不损害生成质量。框架还采用因果注意力机制,条件令牌仅能关注彼此,被禁止访问噪声/文本令牌,而主分支遵循标准因果注意力,可访问条件令牌。该设计保持了清晰的因果建模,避免了风格化与一致性之间的冲突。
实验
- 采用两阶段训练:在单张 GPU 上对风格 LoRA 进行 6,000 步微调,随后在 4 张 GPU 上对一致性模块进行 9,000 步训练,使用滚动 LoRA 银行以实现多风格泛化。
- 在新构建的 100 张图像基准测试集上进行评估,包含复杂构图与 5 个未见风格 LoRA(漫画、油画、PVC 玩具、素描、矢量),使用 DreamSim、CLIP 图像得分、GPT-4o 得分、FID 与 CMMD 进行衡量。
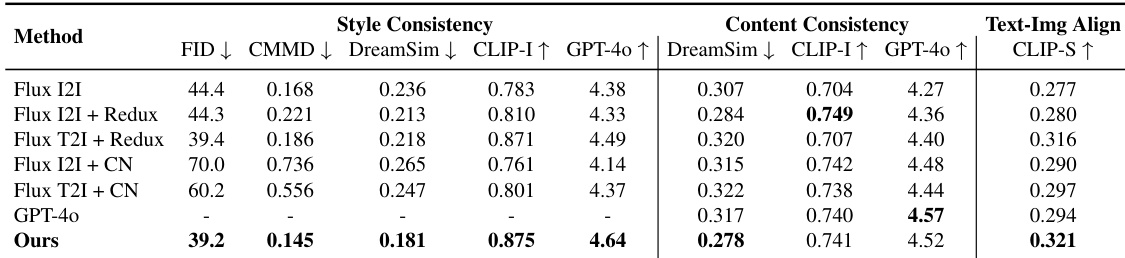
- 在风格一致性指标上达到最先进结果,并取得最高 CLIP 得分,表明其在文本-图像对齐、风格保真度、内容保留与提示对齐之间具有更优平衡。
- 在定量与定性评估中均优于基线方法(包括 Flux I2I、Redux、ControlNet 与 GPT-4o),性能与 GPT-4o 相当,同时在结构与风格一致性方面表现更优。
- 消融实验确认,使用多个 LoRA 的滚动训练以及风格与一致性解耦训练对性能至关重要,尤其在未见风格上表现显著。
- 展现出对未见风格的强大泛化能力,性能下降极小(FID/CMMD 得分见表 3),与 IP-Adapter 及文本引导流水线具备即插即用兼容性,且开销极低(GPU 内存增加 4.6%,推理时间延长 5.3%)。
- 用户研究(n=30)显示,用户对风格与内容一致性的偏好高于基线方法,尽管 GPT-4o 作为参考,因 LoRA 不兼容而仅能通过提示近似实现。
- 局限性包括难以保持非英文文本,以及在多人复杂场景中面部与手部小区域偶尔出现伪影。
作者使用包含复杂构图的 100 张图像基准测试集,将该方法与多个基线(包括 Flux 流水线、ControlNet 与 GPT-4o)进行对比。结果表明,该方法在五项风格一致性指标上表现最佳,并在内容一致性方面位列前列,同时获得最高 CLIP 得分,表明其具有更优的文本-图像对齐能力。
结果表明,OmniConsistency 在已见与未见风格上均实现了强大的风格一致性,FID 与 CMMD 得分显示其在未见风格上的退化极小,与已见风格相比几乎无差异。该方法在风格与内容一致性方面均保持高水平性能,展现出对多样化及此前未见 LoRA 风格的有效泛化能力。

作者采用两阶段训练流程开发 OmniConsistency,结合风格 LoRA 微调阶段与利用滚动 LoRA 银行促进多风格泛化的 consistency 模块训练阶段。结果表明,完整模型在所有指标上均达到最佳性能,尤其在风格一致性与文本-图像对齐方面表现突出;消融实验进一步证实,滚动 LoRA 银行与风格-一致性解耦训练对维持高质量风格化与内容保留至关重要。
