Command Palette
Search for a command to run...
Direct3D-S2:基于空间稀疏注意力的超大规模3D生成新范式
Direct3D-S2:基于空间稀疏注意力的超大规模3D生成新范式
摘要
基于体素表示(如有符号距离函数,SDF)生成高分辨率3D形状面临显著的计算与内存挑战。我们提出Direct3D-S2,一种基于稀疏体素的可扩展3D生成框架,能够在大幅降低训练成本的同时实现卓越的输出质量。其核心创新在于空间稀疏注意力(Spatial Sparse Attention, SSA)机制,该机制显著提升了扩散Transformer(DiT)在稀疏体素数据上的计算效率。SSA使模型能够高效处理稀疏体素中的大规模token集合,显著减少计算开销,在前向传播中实现3.9倍的加速,后向传播中更达9.6倍的加速。此外,本框架集成了一种变分自编码器(VAE),在输入、隐空间与输出阶段均保持一致的稀疏体素表示形式。与以往在3D VAE中采用异构表示的方法相比,这种统一设计显著提升了训练效率与稳定性。我们的模型在公开数据集上进行训练,实验结果表明,Direct3D-S2不仅在生成质量与效率上超越现有最先进方法,更实现了仅使用8张GPU即可完成1024分辨率的训练任务——而传统体素表示在256分辨率下通常至少需要32张GPU。这一突破使千兆级(gigascale)3D生成成为现实且可及。项目主页:https://www.neural4d.com/research/direct3d-s2。
一句话总结
南京大学、DreamTech、复旦大学与牛津大学的研究团队提出 Direct3D-S2,一种基于稀疏体素和空间稀疏注意力(SSA)的可扩展3D生成框架,通过高效计算扩散Transformer,实现反向传播高达9.6倍的加速,并支持仅用8张GPU即可生成1024³分辨率的3D内容——使千兆规模的3D生成变得切实可行且易于访问。
主要贡献
- 从稀疏体素表示生成高分辨率3D形状,长期以来受限于扩散Transformer中全注意力机制带来的高昂计算成本,尤其在 10243 等高分辨率下,由于内存呈二次增长,通常需要数十张GPU。
- 本文提出空间稀疏注意力(SSA)机制,重新定义块划分方式,并集成可学习的压缩与选择模块,高效处理非结构化稀疏3D标记,通过自定义Triton内核实现前向传播3.9倍加速、反向传播9.6倍加速。
- 通过统一的VAE设计,在输入、潜在和输出阶段保持一致的稀疏体素格式,Direct3D-S2仅用8张GPU即可实现 10243 分辨率的训练——在保持最先进质量与效率的同时,使千兆规模3D生成真正实用且可访问。
引言
研究团队利用稀疏体素表示与一种新型空间稀疏注意力(SSA)机制,实现千兆规模下高效、高分辨率的3D形状生成,解决了现有基于扩散的3D生成模型中计算成本这一关键瓶颈。此前的3D潜在扩散方法面临两大挑战:隐式方法因架构不对称且不可扩展,导致训练效率低下;显式体素方法受限于立方体内存增长及扩散Transformer中全注意力机制的高昂开销,使其仅能支持低分辨率或需数百张GPU。核心贡献为 Direct3D-S2,一种统一框架,采用对称稀疏SDF VAE,确保输入、潜在与输出阶段保持一致的稀疏体素表示,消除跨模态转换开销。通过引入SSA——一种专为不规则3D稀疏数据重新设计的可学习压缩与选择模块,该方法在 10243 分辨率下相较FlashAttention-2实现高达9.6倍的反向传播加速,仅用8张GPU即可训练 10243 输出,为显式3D扩散模型带来显著的可扩展性与效率跃升。
数据集
- 数据集包含约45.2万件3D资产,主要来自公开来源,包括Objaverse [9]、Objaverse-XL [8] 和 ShapeNet [5],重点聚焦高质量、非冗余模型。
- 为确保几何一致性,所有原始非封闭网格均通过标准预处理流程转换为封闭表示。
- 为每个网格计算真实值有符号距离函数(SDF)体素,作为模型SS-VAE组件的输入与监督信号。
- 为训练图像条件扩散Transformer(DiT),每件网格生成45张高分辨率(1024 × 1024)RGB渲染图,使用随机相机参数:仰角10°至40°,方位角0°至180°,焦距30mm至100mm。
- 构建了一个具有挑战性的评估基准,采用来自专业3D社区(如Neural4D [3]、Meshy [2] 和 CivitAI [1])的高细节图像,用于在真实条件下测试几何保真度。
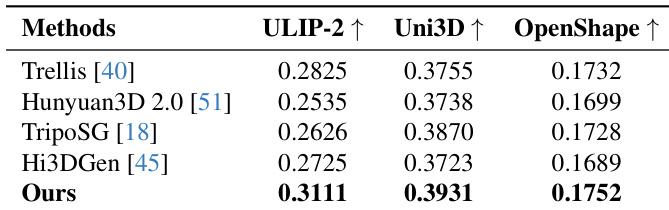
- 定量评估采用多种最先进指标——ULIP-2 [44]、Uni3D [52] 与 OpenShape [20],衡量生成网格与输入图像之间的形状-图像对齐,实现与现有3D生成方法的严格对比。
- 训练数据在不同来源间按混合比例使用,并应用过滤机制剔除低质量或损坏的网格,确保模型鲁棒性与泛化能力。
方法
Direct3D-S2框架采用两阶段架构进行高分辨率3D形状生成,包括对称稀疏SDF变分自编码器(SS-VAE)与基于图像输入的扩散Transformer(DiT)。整个系统将3D形状表示为稀疏有符号距离函数(SDF)体素,实现高效表示与生成。SS-VAE作为全端到端编码器-解码器网络,旨在将高分辨率稀疏SDF体素编码为紧凑潜在表示,并实现后续重建。编码器采用混合架构,结合残差稀疏3D卷积神经网络(CNN)与Transformer层。其通过一系列稀疏3D CNN模块与3D均值池化操作逐步下采样空间分辨率。生成的稀疏体素被视作变长标记,随后由移位窗口注意力层处理以捕捉局部上下文信息。为保留空间信息,每个有效体素的特征在输入注意力层前,基于其3D坐标添加位置编码。该混合设计输出低分辨率稀疏潜在表示。解码器镜像编码器结构,采用注意力层与稀疏3D CNN模块对潜在表示进行上采样,并重建原始SDF体素。框架引入多分辨率训练策略,每个训练迭代中,输入SDF体素被随机插值至多个目标分辨率之一(2563、3843、5123、10243),增强模型对多尺度的处理能力。SS-VAE的训练目标包含重建损失,监督所有解码体素的SDF值,包括原始输入与解码过程中生成的额外有效体素。为提升几何保真度,对靠近锐边的体素施加额外损失,并使用KL散度正则项约束潜在空间。
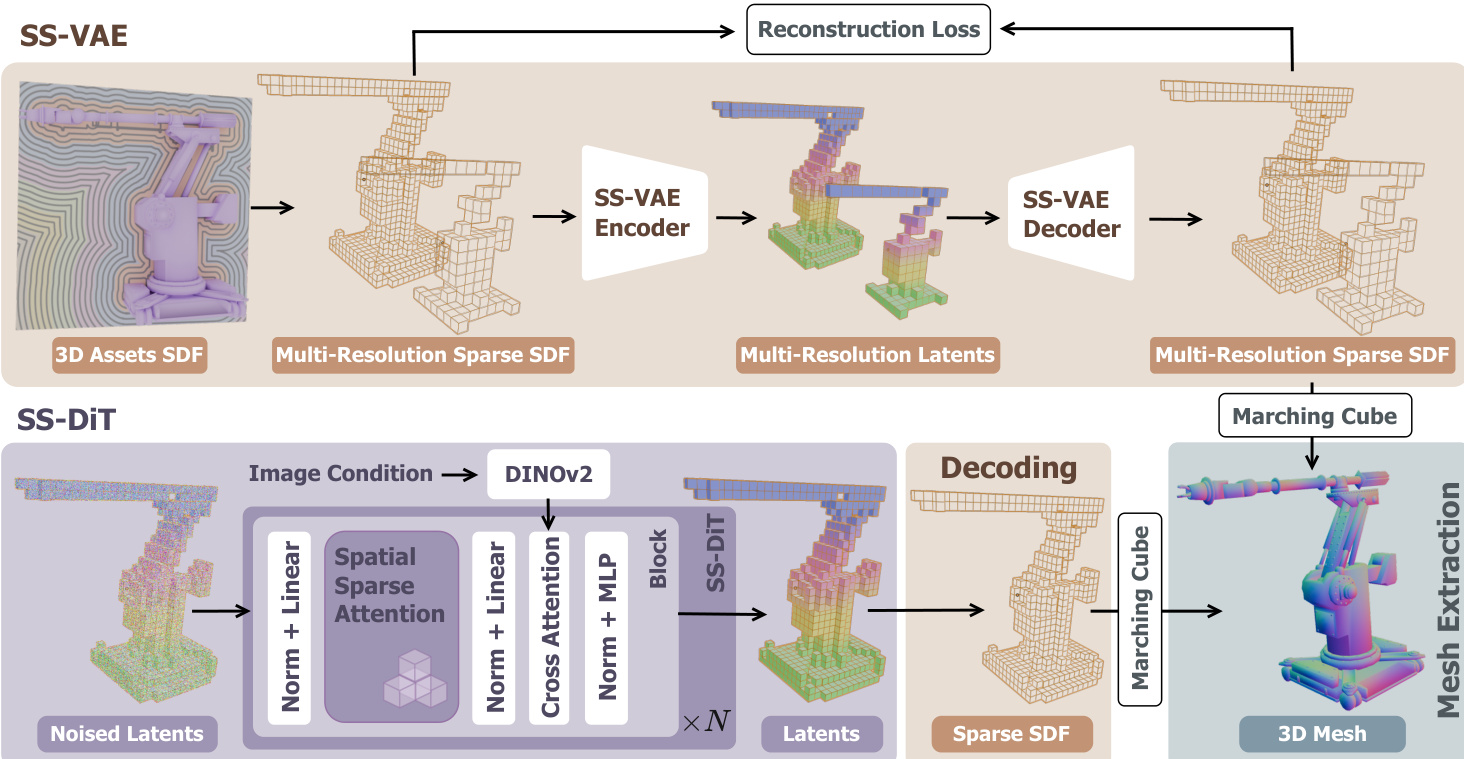
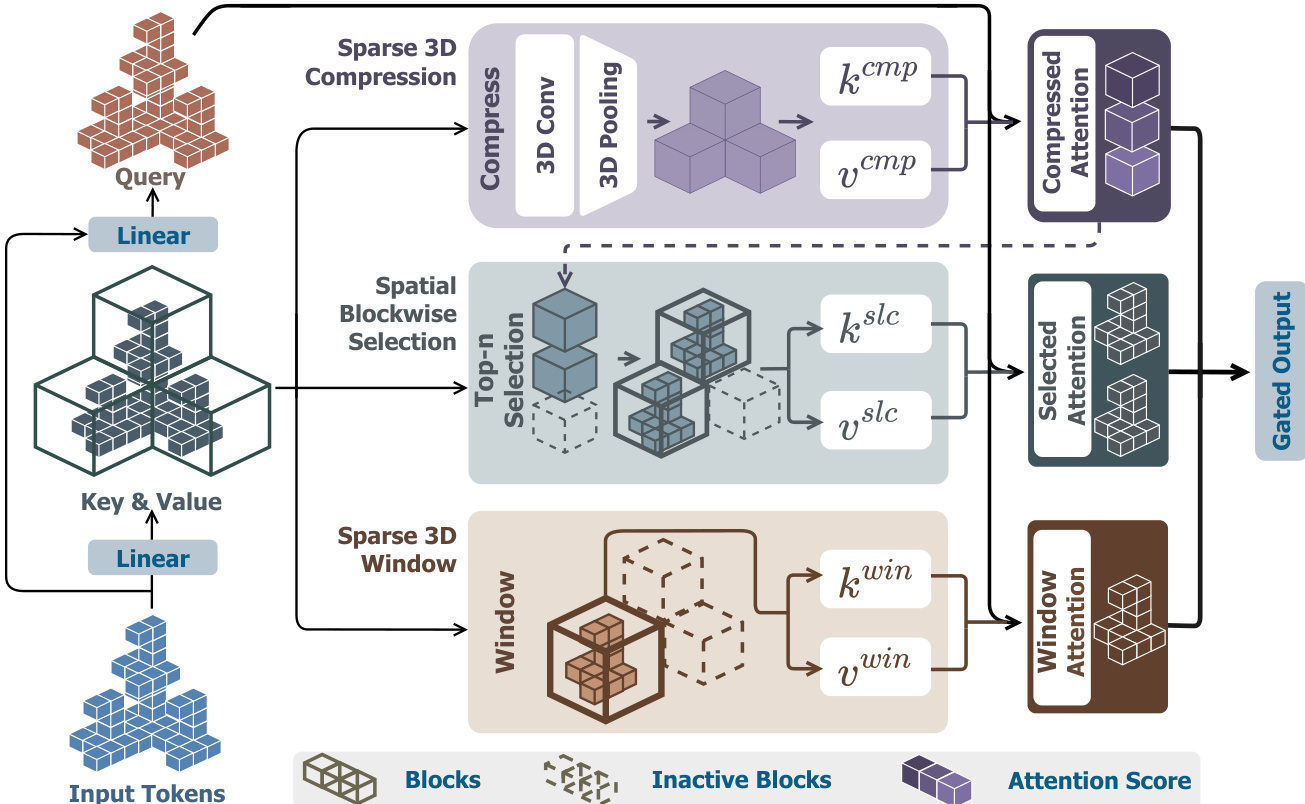
在SS-VAE之后,潜在表示由扩散Transformer(SS-DiT)处理,以生成基于输入图像的3D形状。SS-DiT采用修正流目标进行训练,模型学习从噪声潜在表示到数据分布的速率场。训练过程采用渐进策略,逐步将分辨率从 2563 提升至 10243,以加速收敛。为高效处理高分辨率稀疏体素中的大量标记,作者引入一种新型空间稀疏注意力(SSA)机制。该机制旨在显著加速训练与推理,降低注意力操作的计算成本。标准全注意力机制需计算所有标记间的两两交互,当标记数量增长时变得不可行,至 10243 分辨率时已超过10万标记。SSA机制通过基于3D坐标对输入标记进行空间一致的分块,而非使用易导致训练不稳定的1D索引分块。注意力计算通过三个核心模块完成:稀疏3D压缩、空间分块选择与稀疏3D窗口。稀疏3D压缩模块首先将标记分组为 mcmp3 大小的块,利用稀疏3D卷积与均值池化生成键与值标记的压缩块级表示,捕获全局信息的同时减少标记数量。空间分块选择模块随后利用查询与压缩块之间的注意力得分,选择Top-k 最相关块。这些选中块内的所有标记用于计算第二轮注意力,捕捉细粒度特征。稀疏3D窗口模块进一步通过显式引入局部特征交互增强模型性能。其将输入标记划分为大小为 mwin3 的非重叠窗口,并仅在每个窗口内执行自注意力,确保局部上下文得以保留。这三个模块的输出经加权聚合,由预测的门控得分加权,生成SSA机制的最终输出。该设计使模型能有效处理稀疏体素中的大规模标记集,实现显著加速。
为进一步提升效率,采用稀疏条件机制处理输入图像。模型不使用图像所有像素级特征(易受背景区域主导),而是选择性提取稀疏前景标记。该过程通过DINO-v2编码器提取特征,再应用掩码仅保留前景标记。这些稀疏条件标记随后与噪声潜在标记进行交叉注意力操作,降低计算开销并提升生成网格与输入图像的对齐度。最终3D网格通过生成的稀疏SDF体素使用Marching Cubes算法提取。
实验
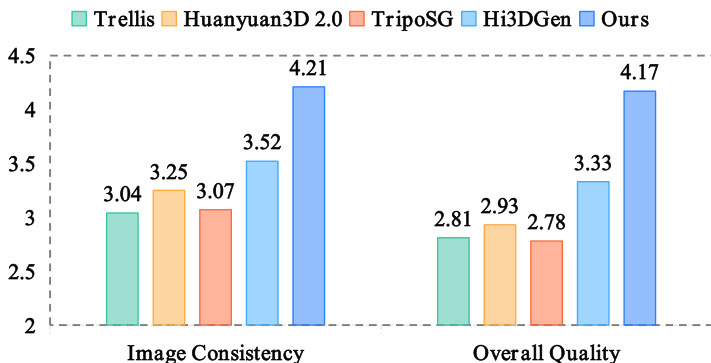
- Direct3D-S2在图像到3D生成任务中超越现有最先进方法,在三项指标上均实现更优的输入图像对齐,并在用户研究(40名参与者,75个网格)中显示出统计显著优势,涵盖图像一致性与几何质量。
- SS-VAE在 5123 与 10243 分辨率下实现高保真重建,尤其在复杂几何结构上表现显著提升,且仅需8张A100 GPU训练2天,远少于竞争方法。
- 消融研究显示,分辨率从 2563 提升至 10243 逐步改善网格质量,10243 分辨率下边缘更锐利、细节对齐更佳。
- SSA机制提升网格质量与平滑度:空间分块选择模块对全局关注至关重要,稀疏3D窗口化实现高效局部交互,完整SSA设计在稳定性与细节保留方面均优于全注意力与NSA变体。
- 在12.8万标记下,SSA相较FlashAttention-2实现最高3.9倍前向加速与9.6倍反向加速,展现出强大可扩展性与效率。
- 稀疏条件机制通过过滤非前景标记,提升图像到网格对齐度,生成更准确的几何结果。
结果表明,所提方法在三项指标——ULIP-2、Uni3D与OpenShape——上均优于所有对比方法,各项得分最高,表明生成网格与输入图像之间具有更优对齐。作者利用这些定量结果证明,其Direct3D-S2框架相比现有最先进方法,生成的3D重建更准确、更一致。
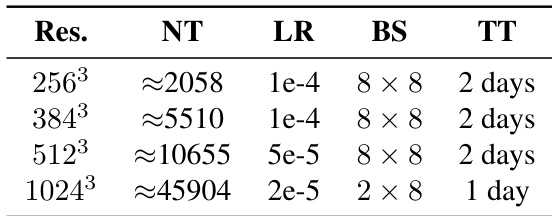
作者通过表格展示,随着分辨率提升,训练时间显著减少,10243 分辨率仅需一天,而低分辨率需两天。尽管标记数量大幅增加且学习率更低,仍实现训练效率提升,表明高分辨率下训练效率更高。
结果显示,所提Direct3D-S2框架在用户研究中,图像一致性和整体几何质量两项指标均优于对比方法。作者组织40名参与者评估75个未过滤网格,柱状图显示Direct3D-S2全面领先,图像一致性得分为4.21,整体质量得分为4.17。