Command Palette
Search for a command to run...
Granite-speech:具备强大英语 ASR 能力的开源语音感知 LLMs
Granite-speech:具备强大英语 ASR 能力的开源语音感知 LLMs
摘要
Granite-speech LLMs 是一种紧凑且高效的语音语言模型,专为英语自动语音识别(ASR)和自动语音翻译(AST)而设计。这些模型通过模态对齐(modality aligning)技术进行训练,即将具有 2B 和 8B 参数规模的 granite-3.3-instruct 变体与语音数据进行对齐。训练所使用的公开开源语料库包含音频输入,以及作为目标文本的人类转录文本(用于 ASR)或自动生成的翻译文本(用于 AST)。全面的 benchmark 测试表明,在作为主要研究重点的英语 ASR 任务中,这些模型的表现优于多个竞争对手的模型,而后者所使用的专有数据规模要高出数个数量级;同时,在英语至主要欧洲语言、日语及中文的 AST 任务中,它们也保持了同等的竞争力。其针对语音设计的特定组件包括:1. 一个使用 block attention 和 self-conditioning,并采用连接时序分类(connectionist temporal classification, CTC)进行训练的 Conformer 声学编码器;2. 一个 windowed query-transformer 语音模态 adapter,用于对声学 embedding 进行时间维度下采样,并将其映射到 LLM 的文本 embedding 空间;3. 用于进一步微调文本 LLM 的 LoRA adapters。Granite-speech-3.3 以两种模式运行:在语音模式下,通过激活编码器、projector 和 LoRA adapters 来执行 ASR 和 AST 任务;在文本模式下,则直接调用底层的 granite-3.3-instruct 模型(不使用 LoRA),这本质上保留了原文本 LLM 的所有能力与安全性。这两个模型均已在 HuggingFace 上免费发布,并可在 Apache 2.0 许可协议下用于研究和商业用途。
一句话总结
通过将带有 block attention 和 self-conditioning 的 Conformer 声学编码器、窗口化 query-transformer 语音模态适配器以及 LoRA 微调相结合,Granite-speech 系列紧凑型语音感知 LLM 在实现高效英语 ASR 和自动语音翻译的同时,性能超越了多个规模更大的专用模型,并保留了 Granite-3.3-instruct 变体原有的基于文本的能力。
核心贡献
- 本文介绍了 Granite-speech,这是一个包含 2B 和 8B 参数变体的紧凑型语音感知大语言模型家族,旨在用于英语自动语音识别 (ASR) 和自动语音翻译 (AST)。
- 该架构采用了一种特定的语音模态对齐策略,由带有 block attention 的 Conformer 声学编码器、用于时间下采样的窗口化 query-transformer 语音模态适配器,以及用于微调底层 Granite-3.3-instruct 模型的 LoRA 适配器组成。
- 实验结果表明,这些模型在英语 ASR 任务上的表现优于在规模大得多的专用数据集上训练的多个竞争对手,并在英语到主要欧洲语言、日语和中文的翻译任务中保持了具有竞争力的性能。
引言
现代口语模型通常分为两类:直接整合音频和 text tokens 的早期融合模型,以及使用声学编码器将音频映射到基于文本的 LLM 的语音感知 LLM。虽然早期融合模型提供了较高的模态流畅度,但由于基于文本的对齐有限,往往会导致指令遵循能力下降并增加安全风险。本文利用语音感知架构开发了 Granite-speech,这是一系列设计用于英语自动语音识别和自动语音翻译的紧凑型 2B 和 8B 参数模型。通过使用 Conformer 声学编码器和窗口化 query-transformer 适配器将音频与 Granite-3.3-instruct 主干网络对齐,在实现英语 ASR 任务具有竞争力的性能的同时,保留了原始文本模型的安全护栏和推理能力。
数据集
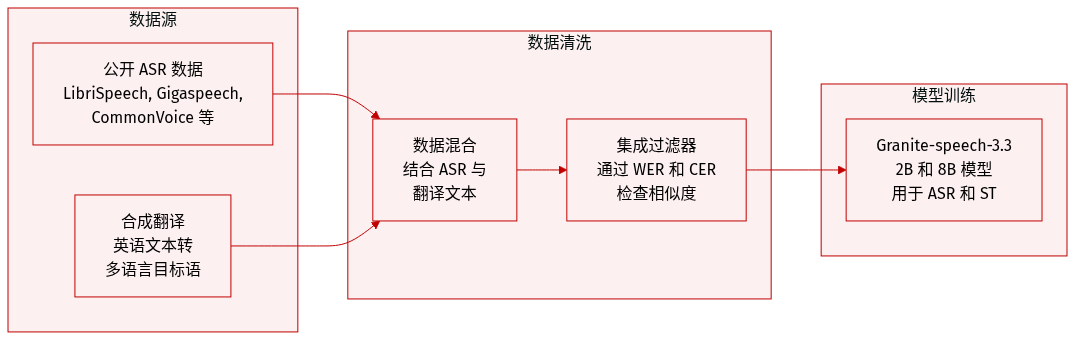
-
数据集组成与来源:模型在主要公开的英语自动语音识别 (ASR) 数据集和合成语音翻译数据的结合上进行训练。ASR 语料库包括 Multilingual LibriSpeech、Gigaspeech、CommonVoice 17.0、LibriSpeech、Voxpopuli、AMI、YODAS、SPGI Speech、Switchboard、CallHome、Fisher、Voicemail 和 TED LIUM。
-
合成语音翻译数据:为了支持语音翻译任务,通过将 CommonVoice 17 的英语转录文本翻译成包括法语、西班牙语、德语、意大利语、葡萄牙语、日语和中文在内的多种语言,生成了合成数据。
-
数据处理与过滤:采用集成过滤策略以确保合成翻译的高质量。使用 Phi-4 作为主要翻译模型,并使用 MADLAD-3B/10B 作为辅助模型来计算翻译输出之间的相似度。在测试了各种指标后,选择词错误率 (WER) 和字符错误率 (CER) 作为最有效的过滤阈值。具体而言,对英语到德语的翻译应用了 0.3 的 WER 阈值,对英语到日语的翻译应用了 0.4 的 CER 阈值。该过程保留了不足一半的原始 CommonVoice 数据,但确保了更高的翻译可靠性。
-
模型使用:处理后的数据集用于训练 Granite-speech-3.3 模型(包括 2B 和 8B 参数版本)。ASR 和合成翻译数据的混合使得模型能够同时执行语音识别和语音翻译任务,其中 8B 模型在翻译性能上优于 2B 变体。
方法
Granite 语音系统被设计为一个语音感知大语言模型 (LLM),能够执行自动语音识别 (ASR) 和自动语音翻译 (AST)。该架构集成了多个关键组件,以弥合连续声学信号与离散 text tokens 之间的差距。
整体框架由声学编码器、语音模态适配器和 Granite 文本 LLM 组成。声学编码器将原始语音信号转换为高层表示。这些表示随后由语音模态适配器进行处理,该适配器充当时间下采样器,并将声学嵌入映射到文本 LLM 可解释的潜在空间中。为了使 LLM 适应这些声学嵌入的特定特征,在 LLM 层注意力块内的 query 和 value 投影矩阵上应用了 LoRA (Low-Rank Adaptation) 适配器。
参考框架图:

语音模态适配器使用两层窗口级 Q-former 投影器。该设计受 SALMONN 架构启发,旨在将变长声学序列转换为固定数量的、能够关注声学嵌入的可训练 queries。给定长度为 T 的声学嵌入序列 X=x1…xT 和 N 个可训练 queries Q=q1…qN,适配器以大小为 K 的块进行输入处理(其中 K≥N 且 KmodN=0)。转换定义为:
y(i−1)∗N+1⋯yi∗N=Q−former(Q,x(i−1)∗K+1…xi∗K),i=1…⌈T/K⌉该机制通过 K/N 的因子有效地执行时间下采样。在确定的最佳配置中,块大小为 K=15 帧且 N=3 个 queries,将原始 100 Hz 的 logmel 帧率降低为适用于 LLM 的 10 Hz 帧率。
为了处理不同的任务,采用基于 Granite chat 格式语法的特定任务 prompt 构建方法。输入序列包括系统 prompt、用户 query 和模型响应。对于 ASR 和 AST 任务,用户 query 包含一个特殊的 ⟨audio⟩ token。在正向传播过程中,该 token 被 Q-former 投影的嵌入所替换。对于 AST,模型支持直接翻译和思维链 (CoT) 方法,其中模型被提示先转录语音然后进行翻译,并使用显式标签来区分步骤。
训练过程涉及在保持声学编码器冻结的情况下,联合优化 Q-former 和 LoRA 适配器。目标是 next-token prediction 交叉熵损失。为了解决不同语料库之间潜在的数据不平衡问题,使用了平衡采样器。语料库 i 的采样概率由因子 α∈[0,1] 控制,计算方式为:
∑j=1LNjαNiα通过设置 α=0.6,能够平滑自然的数据分布,确保在微调阶段较小的语料库得到充分的表示。
实验
研究人员通过比较不同的 tokenization 方法和模型规模来评估编码器架构,以优化联合 LLM 训练的性能。研究结果表明,字符级 tokenization 对于后续与大语言模型的集成最为有效。此外,安全性评估表明,语音接口成功维持了底层文本模型的拒绝行为,即使面对复杂或嘈杂的音频输入,也能防止执行有害指令。
评估了不同的输出 tokenization 方法在贪婪解码期间以及联合 LLM 训练后对 CTC 语音编码器性能的影响。结果显示,与 BERT 或 Granite tokenization 相比,字符级 tokenization 在与大语言模型集成时能带来更好的性能。字符 tokenization 结合 LLM 训练在各种数据集上的表现优于其他 tokenization 方法。与仅使用贪婪解码相比,联合 LLM 训练降低了所有测试 tokenization 类型的错误率。来自 LLM 集成的性能增益在多个不同的音频语料库中是一致的。
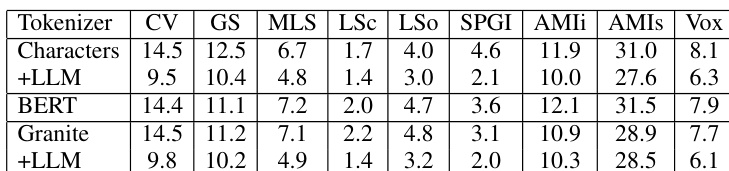
对比了不同 Granite 大语言模型在多个数据集上的性能。结果表明,模型大小和版本会影响各种音频语料库中的识别准确度。与较大版本相比,最小的模型版本在几个类别中显示出略高的错误率。对于大多数数据集,不同模型迭代之间的性能趋势保持相对一致。AMI 数据集显示的错误率始终高于其他测试语料库。

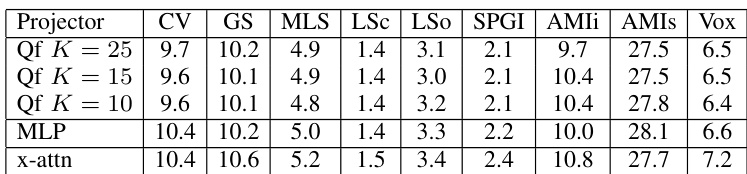
在多个数据集上评估了不同的投影器架构以衡量其性能。结果显示,改变投影头的数量或使用 MLP 在大多数语料库中产生相似的错误率。在 QF 投影器的不同配置下,性能保持相对稳定。与其它评估的架构相比,x-attn 投影器往往会导致较高的错误率。在大多数测试数据集中,MLP 和 QF 投影器表现出相当的性能趋势。
对比了两种不同编码器架构在各种数据集上的自动语音识别性能。结果显示,增加层数通常会提高大多数测试语料库中的识别准确度。在几个类别中,16 层编码器比 10 层编码器实现了更低的错误率。在大多数评估的数据集中都观察到了增加层数带来的性能提升。两种编码器配置都根据所使用的特定语料库显示出不同程度的错误率。

评估了 tokenization 方法、LLM 模型规模、投影器架构和编码器深度对各种数据集上语音识别性能的影响。研究结果表明,字符级 tokenization 结合联合 LLM 训练可产生更优的结果,而更大的模型规模和更深的编码器架构能持续提高准确度。此外,研究证明 MLP 和 QF 投影器在不同配置下提供稳定的性能,而 x-attn 架构往往会导致较高的错误率。