Command Palette
Search for a command to run...
AM-Thinking-v1:在32B规模下推进推理能力的前沿
AM-Thinking-v1:在32B规模下推进推理能力的前沿
摘要
我们提出 AM-Thinking-v1,这是一个参数量为320亿的密集型语言模型,标志着开源创新协作精神在推理能力前沿的又一次突破。该模型在性能上超越了 DeepSeek-R1,并与领先的混合专家(Mixture-of-Experts, MoE)模型如 Qwen3-235B-A22B 和 Seed1.5-Thinking 相媲美,在多项基准测试中展现出卓越表现:在 AIME 2024 上取得 85.3 分,在 AIME 2025 上取得 74.4 分,在 LiveCodeBench 上取得 70.3 分,充分展现了当前同规模开源模型中顶尖的数学推理与代码生成能力。AM-Thinking-v1 完全基于开源的 Qwen2.5-32B 基础模型,并结合公开可获取的训练数据构建而成。通过精心设计的后训练流程——融合监督微调(Supervised Fine-Tuning)与强化学习(Reinforcement Learning)——该模型实现了出色的推理性能。本工作证明,在32B这一规模上,开源社区完全有能力实现高水平的模型表现,而这一规模正是部署与微调的实际“黄金区间”。通过在顶尖性能与现实可用性之间取得良好平衡,我们期望 AM-Thinking-v1 能够激励更多协作努力,推动中等规模模型的发展,持续拓展推理能力的边界,同时始终将可访问性作为技术创新的核心。目前,我们已将该模型在 Hugging Face 上开源,访问地址为:https://huggingface.co/a-m-team/AM-Thinking-v1。
一句话总结
该研究由 a-m-team 团队提出,AM-Thinking-v1 是一个 32B 参数的密集型语言模型,通过在开源数据上采用优化的后训练流程,在数学与编程基准测试中实现了最先进水平的推理性能,超越 DeepSeek-R1 并接近大型 MoE 模型的表现,同时保持了实际部署的可行性与开源可访问性。
主要贡献
-
AM-Thinking-v1 是一个基于开源 Qwen2.5-32B 基础模型和公开可用训练数据构建的 32B 参数密集型语言模型,在数学与代码基准测试中展现出最先进推理能力,无需依赖大规模混合专家(MoE)架构或专有数据。
-
该模型在 AIME 2024 上取得 85.3 分,在 AIME 2025 上取得 74.4 分,在 LiveCodeBench 上取得 70.3 分,通过精心设计的后训练流程实现,该流程结合监督微调与两阶段强化学习,包括难度感知查询选择和渐进式数据过滤。
-
通过严格的预处理流程——如去重、剔除低质量或多模态查询、验证真实答案——模型显著提升了推理能力,超越了更大的 MoE 模型(如 DeepSeek-R1),并接近 Qwen3-235B-A22B 和 Seed1.5-Thinking 的性能。
引言
作者利用公开可用的 Qwen2.5-32B 基础模型,开发了 AM-Thinking-v1,这是一个专为高级推理任务(如数学问题求解和代码生成)优化的密集型语言模型。本工作意义重大,因为它证明了高性能推理——此前主要由超大规模混合专家(MoE)模型主导——可以在 32B 规模的密集架构中实现,相比大型 MoE 系统具有更好的可部署性和更低的基础设施需求。以往方法要么依赖专有数据、超大模型,要么采用复杂的部署流程,限制了可访问性与实用性。其核心贡献在于一个精心设计的后训练流程,仅使用开源数据,包含严格的预处理、数学查询的真实答案验证,以及结合监督微调与强化学习的两阶段训练过程,其中引入了难度感知查询选择。这使得 AM-Thinking-v1 在 AIME2024、AIME2025 和 LiveCodeBench 等基准测试中超越了更大规模的 MoE 模型,证明了通过精心的数据筛选与训练设计,可以在不牺牲模型效率的前提下弥合推理性能差距。
数据集
- 数据集包含约 284 万条样本,来自五个核心领域:数学推理、代码生成、科学推理、指令遵循和通用对话,均来自公开的开源来源。
- 数学推理数据来自 OpenR1-Math-220k、Big-Math-RL-Verified、NuminaMath、MetaMathQA、2023_amc_data、DeepMath-103K 和 AIME 等数据集,每条查询均附有可验证的真实答案。
- 代码生成数据来自 PRIME、DeepCoder、KodCode、liveincode_generation、codeforces_cots、verifiableCoding、opencoder、OpenThoughts-114k-Code_decontaminated 和 AceCode-87K,所有数据均包含可验证的测试用例。
- 科学推理包含来自 task_mmmlu、chemistryQA、Llama-Nemotron-Post-Training-Dataset-v1、LOGIC-701、ncert 和 logicLM 的多项选择题,每道题均配有可靠的真实答案。
- 指令遵循数据来自 Llama-Nemotron-Post-Training-Dataset 和 tulu-3-sft-mixture。
- 通用对话数据涵盖 evol、InfinityInstruct、open_orca、tulu-3-sft-mixture、natural_reasoning、flan、ultra_chat 和 OpenHermes-2.5,覆盖开放式、多轮和单轮交互。
- 所有数据均经过去重和过滤:移除包含 URL 或图像引用的查询,以防止幻觉并确保与纯文本模型的兼容性。
- 使用大语言模型(LLM)过滤描述不清的数学查询,真实答案通过对比 DeepSeek-R1 的回答与原始答案,利用 math_verify 进行验证。不一致结果将通过 o4-mini 重新评估,若 o4-mini 的答案与 DeepSeek-R1 的多数回答一致,则修正错误的真实答案。
- 排除数学证明题和多子问题查询;多选题数学题被重写为填空题以保留实用性。
- 代码查询在支持 Python 和 C++ 的安全分布式云沙箱中处理。代码块使用标准 Markdown 语法标记(如
python,cpp)。测试用例为方法调用(转换为断言)或标准输入/输出(通过 stdin/stdout 处理)。仅当所有测试用例通过时,查询才获得 1 分奖励。 - 为防止数据泄露,训练查询被过滤,排除与评估集存在完全匹配或语义相似的样本。
- 在监督微调阶段,模型在 Qwen2.5-32B 上训练,学习率为 8e-5,全局批量大小为 64,训练 2 个周期,采用余弦预热(占总步数的 5%)。序列长度上限为 32k token,使用序列打包。
- 对于数据稀缺类别(如指令遵循),通过重复进行数据上采样。对挑战性查询,通过生成多个合成响应以提升训练多样性与鲁棒性。
- 在多轮对话中,仅使用最终响应(包含完整推理链)作为训练目标,损失仅在该输出上计算,以强调推理质量。
方法
作者采用两阶段强化学习(RL)流程,以增强基于 Qwen2.5-32B 基础模型构建的 32B 密集型语言模型 AM-Thinking-v1 的推理能力。整体训练框架基于开源的 verl 强化学习框架,集成 vLLM、FSDP 和 Megatron-LM,支持在 1000+ GPU 上实现可扩展训练。RL 流程设计确保了稳定且高效的策略更新,同时保持计算效率。
训练流程始于预过滤步骤,用于选择难度适中的查询。数学与代码查询根据监督微调(SFT)模型的通过率进行筛选,仅保留通过率严格介于 0 和 1 之间的样本。这确保了训练数据具有足够的挑战性以驱动学习,同时避免因过于简单或不可解样本导致的不稳定性。过滤后的数据集包含 32k 条数学查询和 22k 条代码查询。
RL 流程包含两个阶段。在第一阶段,模型在过滤后的数学与代码查询上使用组相对策略优化(GRPO)进行训练,GRPO 是近端策略优化(PPO)的轻量级变体。训练配置包含若干关键设计:不施加 KL 约束,允许更大幅度的策略更新;在回放过程中,超过长度阈值的响应被赋予零优势,以防止过长输出影响参数更新;强制执行严格在线策略训练,即每批 256 个查询生成 16 次回放,每个探索阶段仅更新一次策略。最大响应长度限制为 24K token,使用相对较高的学习率 4×10−6 以加速收敛。
当第一阶段性能趋于平稳时,流程进入第二阶段。在此阶段,将第一阶段中模型以 100% 准确率回答的所有数学与代码查询从训练集中移除。数据集随后通过增加 15k 条通用对话和 5k 条指令遵循数据进行扩充,以提升模型的泛化能力。最大响应长度提升至 32K token,学习率降低至 1×10−6,以稳定后期训练过程。
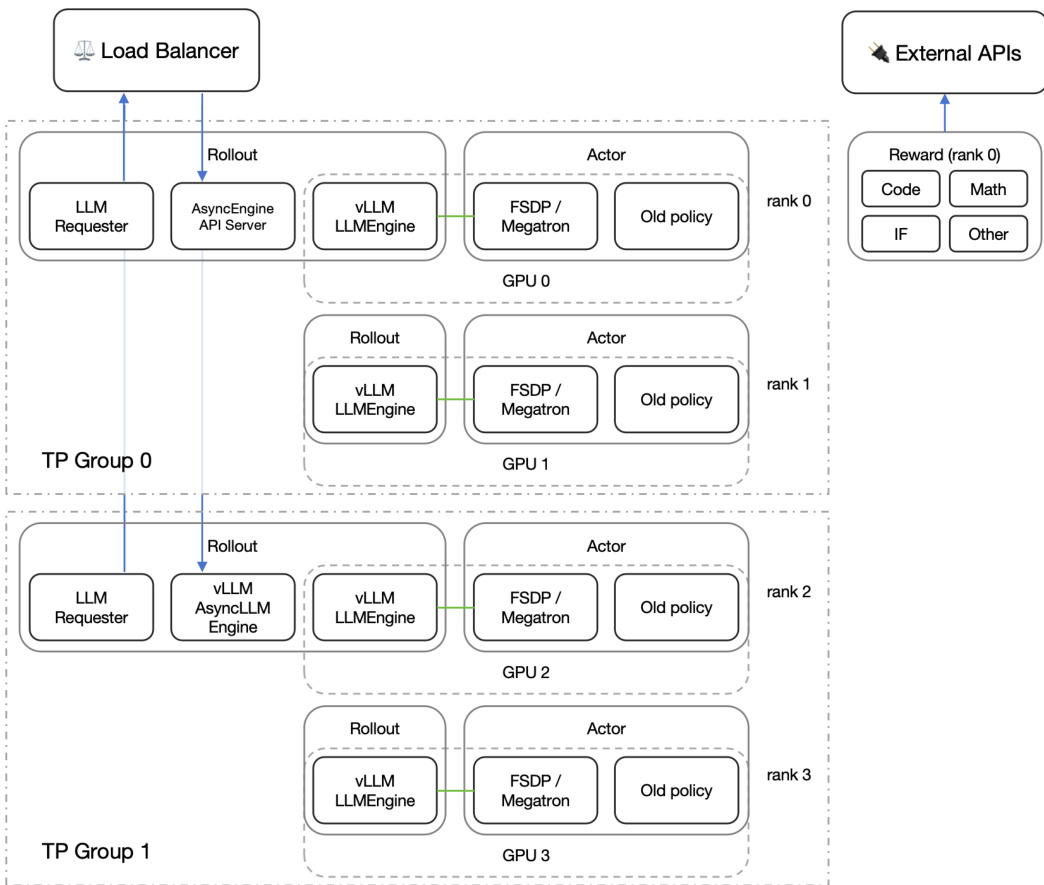
如图所示,RL 框架分为两个张量并行(TP)组,每组包含多个 GPU。每组内部使用负载均衡器分发传入请求。LLM Requester 与 AsyncEngine API Server 管理查询流,vLLM LLMEngine 负责推理,Actor 组件执行策略更新。Actor 使用 FSDP/Megatron 实现分布式训练,并在 GRPO 更新期间维护旧策略用于对比。框架还支持外部 API 用于奖励计算,将 LLM 作为裁判和代码沙箱等资源密集型操作外挂处理。奖励计算按来源类型分类,包括 Code、Math、Instruction Following(IF)和其他,每类奖励独立计算。这种模块化设计支持在大规模集群上高效、可扩展的强化学习训练。
实验
- 合成响应过滤通过困惑度、n-gram 重复率和结构检查验证质量;真实答案查询通过通过率验证,其他查询通过基于 LLM 的奖励评分验证。
- 可验证查询(数学、代码、指令遵循)采用基于规则的验证:数学答案通过归一化比较(math_verify)验证,指令遵循通过 IFEval 严格模式评估,输出二元奖励。
- 非可验证查询使用奖励模型评估有用性、正确性和连贯性;最终得分为三者平均值。
- 回放速度优化采用分离式回放与流式负载均衡,降低长尾延迟,通过动态分配生成任务提升 GPU 利用率。
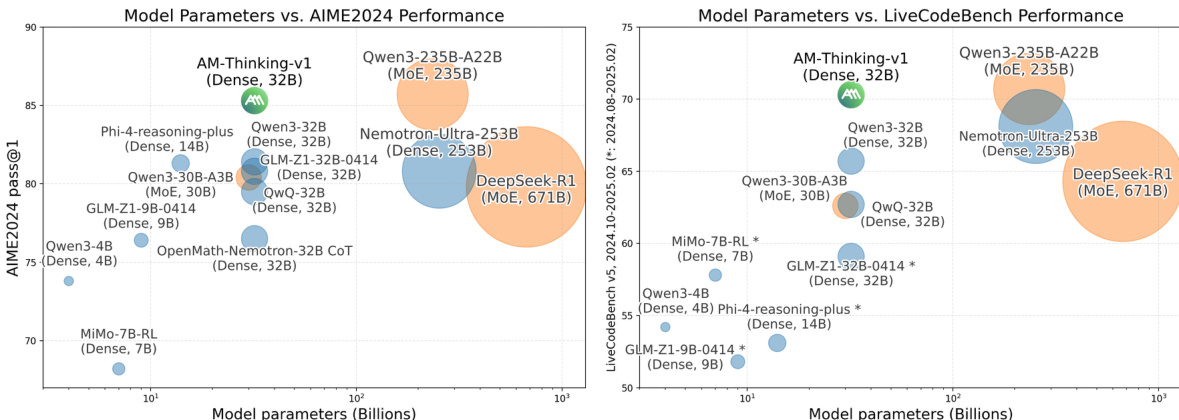
- 在 AIME2024 上,AM-Thinking-v1 达到 85.3 pass@1,超越 DeepSeek-R1(80.0)和 Qwen3-32B(78.7),与更大模型 Qwen3-235B-A22B(85.3)持平。
- 在 AIME2025 上,得分为 74.4,优于 DeepSeek-R1(70.0)和 Qwen3-32B(69.3)。
- 在 LiveCodeBench 上,AM-Thinking-v1 达到 70.3 pass@1,显著超越 DeepSeek-R1(64.3)、Qwen3-32B(65.7)和 Nemo-Ultra-256B(68.1)。
- 在 Arena-Hard 上,得分为 92.5,与 OpenAI-o1(92.1)和 o3-mini(89.0)相当,但低于 Qwen3-235B-A22B(95.6)。
- SFT 训练显示模式转变:较高学习率(8×10⁻⁵)和批量大小(2M token)实现收敛;生成长度随时间减少,停止比例上升,表明推理结构对齐能力提升。
作者在多个推理基准测试中采用一致的评估设置,将 AM-Thinking-v1 与多个领先模型进行比较。结果表明,AM-Thinking-v1 在数学与编程任务中表现强劲,超越或接近 DeepSeek-R1 和 Qwen3-32B 等更大模型,同时在通用对话基准 Arena-Hard 上也展现出竞争力。
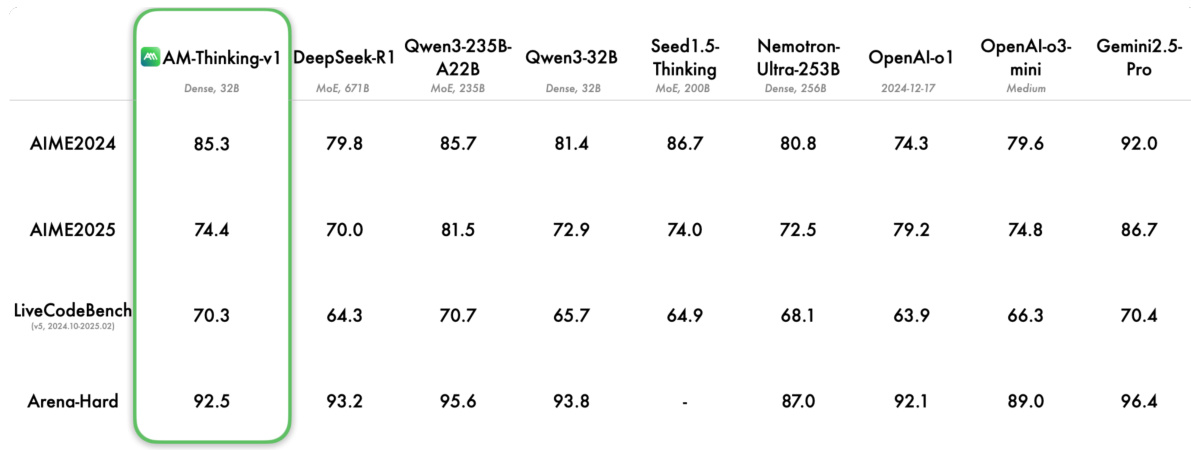
作者在多个推理基准测试中评估 AM-Thinking-v1,并与多个领先的大规模模型进行比较。在数学任务中,AM-Thinking-v1 在 AIME2024 和 AIME2025 上分别取得 85.3 和 74.4 分,优于或接近 DeepSeek-R1 和 Qwen3-235B-A22B 等更大模型。在 LiveCodeBench 基准测试中,AM-Thinking-v1 达到 70.3 分,显著超越 DeepSeek-R1(64.3)、Qwen3-32B(65.7)和 Nemotron-Ultra-253B(68.1),展现出强大的代码理解与生成能力。在通用对话基准 Arena-Hard 上,AM-Thinking-v1 获得 92.5 分,与 OpenAI-o1(92.1)和 o3-mini(89.0)等专有模型相当。然而,其性能仍落后于 Qwen3-235B-A22B(95.6),表明在通用对话能力方面仍有提升空间。

作者利用提供的图表,将 AM-Thinking-v1 在 AIME2024 和 LiveCodeBench 基准测试中的性能与多种模型进行对比,绘制模型规模与基准得分的关系图。结果显示,AM-Thinking-v1 在两项任务中均表现出色,超越多个更大模型,展现出相对于其参数量的高效竞争力。