Command Palette
Search for a command to run...
基于对抗性后训练的快速文本到音频生成
基于对抗性后训练的快速文本到音频生成
摘要
尽管文本转音频(text-to-audio)系统在性能上持续提升,其推理阶段的延迟仍较高,难以满足众多创意应用对低延迟的需求。本文提出一种名为对抗性相对对比(Adversarial Relativistic-Contrastive, ARC)的后训练加速方法,这是首个不依赖知识蒸馏(distillation)的扩散模型与流模型对抗性加速算法。以往的对抗性后训练方法在与计算成本高昂的知识蒸馏方法对比时表现不佳,而ARC后训练则是一种简洁高效的流程,包含两个关键步骤:(1)将近期提出的相对对抗性(relativistic adversarial)框架拓展至扩散/流模型的后训练场景;(2)引入一种新颖的对比判别器目标函数,以增强模型对提示词(prompt)的遵循能力。我们将ARC后训练与一系列针对Stable Audio Open的优化技术相结合,构建出目前效率最高的文本转音频模型:在H100 GPU上,可实现约75毫秒内生成约12秒、44.1kHz采样率的立体声音频;在移动端边缘设备上,亦可在约75毫秒内生成约7秒的音频。该模型为目前已知推理速度最快的文本转音频系统。
一句话摘要
来自加州大学圣地亚哥分校、Stability AI 和 Arm 的作者提出 ARC(对抗性相对对比)后训练——一种新颖的无知识蒸馏加速方法,适用于文本到音频的扩散/流模型。该方法结合相对对抗损失与对比判别器,提升提示遵循度和真实感,使 H100 上 12 秒 44.1kHz 立体声音频生成仅需 75ms,移动端边缘设备上低于 7 秒,显著推动实时创意应用的发展。
主要贡献
- 文本到音频生成仍因扩散和流模型的迭代采样特性而速度缓慢,尽管模型质量近年大幅提升,但推理延迟仍是实时创意应用的主要瓶颈。
- 作者提出对抗性相对对比(ARC)后训练,一种新颖的无知识蒸馏方法,将相对对抗损失与对比判别器目标相结合,在加速推理过程中提升音频真实感和提示遵循度。
- ARC 实现了在 H100 GPU 上仅用 75ms 生成约 12 秒 44.1kHz 立体声音频,在移动边缘设备上低于 7 秒完成生成,速度与多样性均优于先前方法,且是首个完全对抗性、非蒸馏的音频流模型方法。
引言
文本到音频生成在质量上已取得显著进展,但推理延迟仍是主要瓶颈——当前模型每生成一次通常需要数秒至数分钟,限制了实时创意应用。以往的加速方法高度依赖知识蒸馏,这需要大量计算资源进行训练与存储,且常继承无分类器引导(CFG)的缺点,如多样性降低和过饱和。部分后训练方法通过使用对抗损失避免蒸馏,但在音频领域因提示遵循度弱、缺乏有效训练方案而成效有限。作者提出对抗性相对对比(ARC)后训练,一种新框架,将相对对抗训练扩展至文本条件音频,并引入对比判别器目标以强化提示保真度。该方法实现无需蒸馏或 CFG 的快速高质量音频生成,在 H100 GPU 上仅用 75ms 生成 12 秒 44.1kHz 立体声音频——比原始模型快 100 倍——并在移动 CPU 上实现约 7 秒的设备端推理,成为迄今最快的文本到音频系统。
方法
作者采用两阶段框架进行文本到音频生成,首先使用预训练的修正流模型,再通过对抗后训练加速采样过程,同时保持质量与提示遵循度。整体架构基于在压缩音频空间中运行的潜在扩散模型。基础模型由 SAO 提供的 1.56 亿参数自编码器构成,将立体声波形压缩为 64 通道的潜在表示,分辨率为 21.5Hz。该潜在空间由 1.09 亿参数的 T5 文本嵌入器编码的文本提示进行条件控制。核心生成组件为扩散 Transformer(DiT),初始作为修正流模型预训练,用于预测流的速度 vθ(xt,t,c),该速度用于逆转由 xt=(1−t)x0+tϵ 定义的前向加噪过程。
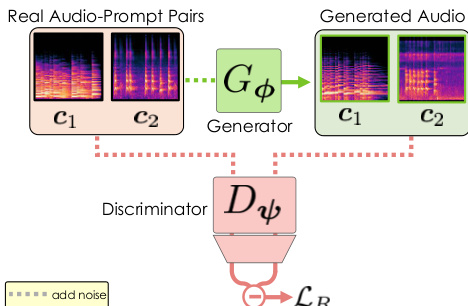
如图所示,后训练阶段将预训练的速度预测器 vθ 重参数化为少步生成器 Gϕ,使其能从噪声输入 xt 直接输出干净音频 x^0。这一过程通过对抗后训练实现,生成器 Gϕ 与判别器 Dψ 联合优化。判别器从预训练的 DiT 初始化,使用其输入嵌入层和 75% 的模块,并附加一个轻量级一维卷积头。训练过程包括:对真实音频 x0 加噪得到 xt,再输入生成器生成去噪样本 x^0。随后,真实样本与生成样本均被重新加噪至更低噪声水平 s,作为判别器的输入。生成器通过最小化相对对抗损失 LR 进行训练,该损失比较判别器对生成样本与配对真实样本的输出,鼓励生成器产出“比真实样本更真实”的结果。该损失定义为 LR(ϕ,ψ)=E[f(Δgen−Δreal)],其中 f(x)=−log(1+e−x),Δgen 为生成样本的判别器 logits,Δreal 为真实样本的 logits。
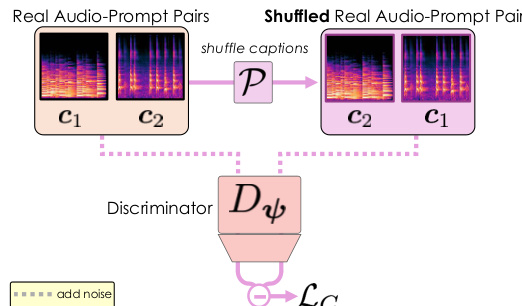
为解决因以真实感为导向的对抗损失导致的提示遵循度差的问题,作者引入判别器的对比损失 LC。该损失旨在提升判别器对音频与文本提示之间对齐的理解能力。其通过在批次内打乱文本提示,生成错配的音频-文本对,并训练判别器最大化正确对与错误对 logits 之间的差异。损失形式为 LC(ψ)=E[f(Δreal(x0,s,P[c])−Δreal(x0,s,c))],其中 P[⋅] 表示提示的随机置换。该对比目标促使判别器关注语义特征而非偶然相关性,从而为生成器提供更强的梯度信号以提升提示遵循度。总后训练目标为相对对抗损失与对比损失之和,即 LARC(ϕ,ψ)=LR(ϕ,ψ)+λ⋅LC(ψ)。
后训练完成后,模型采用专用采样策略进行推理。生成器 Gϕ 被设计为从噪声输入直接估计干净输出,这要求摒弃修正流中传统的 ODE 求解器。作者采用乒乓采样(ping-pong sampling),在使用 Gϕ 去噪样本与将其重新加噪至更低噪声水平之间交替进行。该迭代精炼过程使模型能在极少数步骤内生成高保真音频,显著加速生成过程。
实验
- 在 AudioCaps 测试集(4,875 次生成)上评估加速后的文本到音频模型,使用 FDopen13、KLpasst、CLAP 分数、Rpasst、Cpasst 以及提出的 CCDS 指标,验证音频质量、语义对齐、提示遵循度与多样性。
- 相较于 SAO(100 步)实现 100 倍加速,相较预训练 RF(50 步)实现 10 倍加速,性能指标具有竞争力,且 ARC 后训练在无显著质量损失下提升了多样性。
- 尽管质量略低,ARC 在多样性上优于 Presto(CCDS 与 MOS 多样性更高),而 Presto 虽质量高但多样性严重下降。
- 8 步推理取得最佳效果,与近期关于加速模型步数效率的研究结果一致;消融实验验证了相对损失及 LR 与 LC 联合训练的重要性。
- CCDS 指标与主观多样性 MOS 显示强相关性,验证其在条件多样性评估中的有效性。
- 在边缘设备(Vivo X200 Pro)上,动态 Int8 量化将推理时间从 15.3 秒降至 6.6 秒,峰值 VRAM 从 6.5GB 降至 3.6GB,实现消费级 GPU 上低于 200ms 的延迟。
- 展示了实际创意应用,包括实时音效设计、风格迁移、语音到音频控制及节拍对齐生成,凸显其响应速度与多功能性。
作者使用经 ARC 后训练的修正流模型,在保持高音频质量与提示遵循度的同时实现显著加速。结果表明,该方法在与 SAO、Presto 等最先进模型相当的性能基础上,具有显著更低的延迟与更高的多样性,尤其在使用 8 步时表现突出,同时通过量化实现了有效的边缘设备优化。