Command Palette
Search for a command to run...
UniversalRAG:面向多模态与多粒度语料库的检索增强生成
UniversalRAG:面向多模态与多粒度语料库的检索增强生成
Woongyeong Yeo Kangsan Kim Soyeong Jeong Jinheon Baek Sung Ju Hwang
摘要
检索增强生成(Retrieval-Augmented Generation, RAG)通过将模型响应基于与查询相关的外部知识,显著提升了事实准确性。然而,现有大多数方法仅限于文本单一模态的语料库,尽管近期研究已将RAG扩展至图像、视频等其他模态,但通常仍局限于单一模态专用的语料库。相比之下,现实世界中的查询对知识类型的需求差异极大,单一类型的知识源难以全面应对。为此,我们提出UniversalRAG,旨在从异构来源中检索并整合具有多样化模态与粒度级别的知识。具体而言,基于观察发现:若强制将所有模态映射到由单一聚合语料库导出的统一表示空间,会导致“模态鸿沟”问题,即检索过程倾向于优先返回与查询相同模态的项。为此,我们提出一种模态感知路由机制,能够动态识别最适配的模态专用语料库,并在其中执行针对性检索,同时通过理论分析进一步验证其有效性。此外,除了模态维度,我们还将每种模态划分为多个粒度层级,从而实现针对查询复杂度与范围的精细化检索。我们在涵盖多种模态的10个基准测试上对UniversalRAG进行了验证,结果表明其在性能上显著优于多种模态专用及统一型基线方法。
一句话总结
KAIST与DeepAuto.ai的作者提出UniversalRAG,一种模态感知的检索框架,能够动态将查询路由至相关模态特定的语料库,并利用多粒度索引提升跨模态检索的准确性,在10个多元模态基准测试中均优于统一和模态特定的基线方法。
主要贡献
- 现有的检索增强生成(RAG)系统通常局限于单模态语料库,导致在需要来自文本、图像或视频等多样化来源知识的查询上表现不佳,这是由于统一嵌入空间中固有的模态差距所致。
- UniversalRAG引入模态感知路由机制,动态将查询导向最相关的模态特定语料库,避免跨模态嵌入偏差,并在无需统一表示空间的情况下实现精准检索,该方法得到理论分析支持。
- 该框架在每种模态内进一步整合多种粒度层级(如段落、片段、图像等),使检索可针对查询复杂度进行细粒度调整,在10个多元模态基准测试中均达到最先进水平,同时提升效率与鲁棒性。
引言
检索增强生成(RAG)通过将大语言模型(LLM)的响应锚定在外部知识中,提升了事实准确性,但先前方法大多局限于纯文本语料库或单模态检索,无法处理现实世界中需要多种知识类型(如文本、图像、视频或其组合)的查询。一个关键挑战是模态差距:在统一嵌入空间中,检索倾向于偏向查询的模态,导致相关跨模态内容被忽略。此外,检索粒度固定(无论是完整文档还是短段落)限制了对复杂度各异查询的精确性。作者提出UniversalRAG,通过模态感知路由克服这些局限,动态将查询导向最合适的模态特定语料库,无需依赖统一嵌入空间。该方法避免了模态偏差,并支持新模态的无缝集成。此外,每种模态按多个粒度层级(如段落、片段、章节等)组织,使检索能根据查询复杂度进行细粒度适配。系统在10个多样化基准上进行了验证,表现优于模态特定和统一基线,同时提升了效率与鲁棒性。
数据集

- 数据集包含领域内与领域外基准,每类按3:7比例划分为训练集与测试集。
- 领域内数据集包括:
- MMLU:使用所有开发集问题(无需检索),涵盖数学、法律、世界知识等多样化任务。
- Natural Questions:从开发集随机采样2,000个问答对;维基百科语料库按100词段落切分。
- HotpotQA:测试集中的2,000个问答对;多跳推理查询,语料库由相关文档分组构成(最多4K+ token)。
- HybridQA:开发集中的2,000个问答对;分为独立的表格与文本语料库,支持模态特定检索。
- MRAG-Bench:1,353个多元模态问题(文本+图像);基于所有问题中的图像构建单一图像语料库。
- WebQA:2,000个筛选后的问答对,需图像检索;使用GPT-4o确保问题不依赖图像;构建独立的文本与图像语料库。
- InfoSeek:开发集中的2,000个问答对;每题收集文本与图像证据,分别构建语料库。
- LVBench:短时间戳查询通过GPT-4o重述为纯文本格式;用作片段级训练数据;在可用视频上进行评估。
- VideoRAG-Wiki 与 VideoRAG-Synth:通过GPT-4o识别全视频检索查询;用作视频级训练数据。
- 领域外数据集仅用于评估:
- TruthfulQA:多项选择题,测试避免错误信念的能力;每题仅一个正确答案。
- TriviaQA:开发集中的2,000个问答对;由GPT-4o分类是否需要检索;证据按100词段落切分。
- SQuAD:开发集中的2,000个问答对;使用完整维基百科语料库,按100词段落切分。
- 2WikiMultiHopQA:开发集中的2,000个问答对;基于聚合的段落级上下文构建文档级语料库。
- Visual-RAG:使用完整查询集;每类随机采样五张图像作为图像检索池。
- CinePile:144个视频,每视频随机选取10个测试问题;使用GPT-4o分类粒度(片段级 vs. 全视频)。
- 作者使用训练集进行模型训练,混合使用领域内数据集,应用模态特定路由与处理流程。
- 处理流程包括:
- 文本语料库按100词段落切分。
- 多跳与多元模态查询通过文档分组或模态分离处理。
- 视频查询通过GPT-4o重述为纯文本格式,并分类粒度。
- 图像语料库通过聚合各问题中的证据构建。
- 使用GPT-4o进行过滤、重述与粒度分类,确保与实验设置一致。
方法
作者提出UniversalRAG,一种旨在动态将查询路由至最适配的模态与粒度以实现精准检索的框架,解决了现有检索系统要么仅限单模态,要么固定粒度的局限。核心挑战是模态差距:当涵盖文本、图像、视频等异构模态的语料库被整合为统一语料库并嵌入共享空间时,文本查询往往更接近文本项,无论查询实际所需模态为何,导致检索性能不佳。为规避此问题,UniversalRAG将检索过程分解为两个阶段:模态感知路由与粒度感知检索。
参考框架图,该图展示了先前方法的局限与所提方案。第一阶段采用路由模块,预测给定查询最相关的模态或模态-粒度组合。该模块通过分析查询,确定最优的模态与粒度集合以进行信息检索。路由决策不强制所有数据进入统一嵌入空间,从而保留每种模态特定语料库的独特特性。相反,检索被限制在选定语料库内,使用针对特定数据类型的模态专用检索器。该方法避免了统一嵌入方案固有的模态偏差问题。
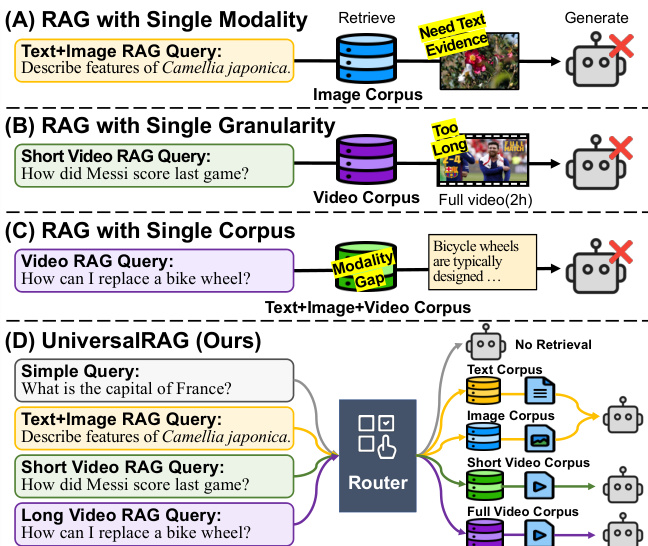
为进一步提升灵活性,UniversalRAG将路由机制扩展至考虑每种模态内的不同粒度层级。这使系统可根据查询需求检索细粒度细节或更广泛上下文。因此,路由模块被扩展为不仅预测模态,还预测粒度级别,包括不检索选项,适用于无需外部知识的查询。这使框架能适应不同查询的多样复杂度与信息范围,提供更精细有效的检索策略。
路由模块以两种方式实现:基于训练的方法与免训练方法。在基于训练的变体中,路由器使用多热标签表示与交叉熵损失进行训练,利用现有基准的归纳偏置自动生成标注数据。模型训练目标是为每个查询预测合适的模态-粒度组合,推理决策基于预设阈值。相比之下,免训练方法利用大语言模型(如Gemini)的推理能力,通过精心设计的提示模板(包含任务目标与少量示例)作为路由器。该方法无需监督训练,使系统可在无需额外数据的情况下适应新领域。
实验
- 在七种模态与粒度上使用多样化数据集评估UniversalRAG:MMLU(无需检索)、Natural Questions(文本,段落级)、HotpotQA(文本,文档级)、HybridQA(文本+表格)、MRAG-Bench(图像)、WebQA与InfoSeek(跨模态文本-图像)、LVBench、VideoRAG-Wiki、VideoRAG-Synth(视频)。
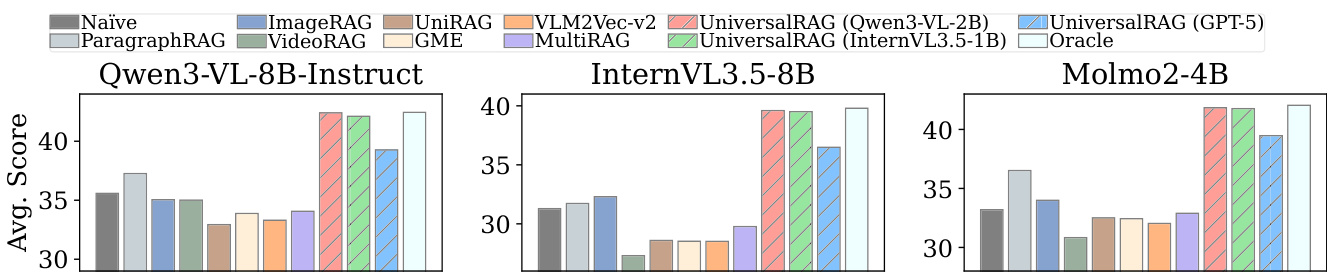
- 证明UniversalRAG在所有基准上持续优于单模态RAG、统一嵌入多元模态RAG(如VLM2Vec-V2、GME)及MultiRAG,其在Qwen3-VL-8B-Instruct上的平均表现最高,ROUGE-L与BERTScore指标全面超越所有基线。
- 证明跨模态检索显著优于单模态方法,尤其在HybridQA与WebQA上,多模态互补证据对性能提升至关重要。
- 验证多粒度路由的有效性:UniversalRAG采用粒度感知选择的版本,其准确率高于固定粒度基线,训练自由与训练依赖变体均观察到性能提升。
- 证明模态感知路由在语料库规模增大时,检索延迟呈次线性下降,优于统一嵌入方法(在超过1000万条目后),因搜索空间缩小且路由高效。
- 确认小型路由器模型(如10亿参数)可实现约90%的路由准确率,支持高效部署且不牺牲性能。
- 证明对领域外数据集具有强泛化能力:免训练路由器(如GPT-5)在OOD设置中优于训练路由器,而结合训练与免训练路由器的集成策略在各领域均表现稳健。
- 案例研究证实UniversalRAG能正确将查询路由至合适模态与粒度,实现准确的跨模态与细粒度推理,即使单模态方法失败亦能胜任。
作者使用UniversalRAG在涉及多种模态与粒度的多样化RAG任务中评估其性能,与包括单模态、统一嵌入及多语料库多元模态方法在内的多种基线进行对比。结果表明,UniversalRAG在所有基准上持续取得最佳平均性能,其免训练路由器变体常接近或达到“理想”性能,证明模态感知与粒度感知路由的有效性。
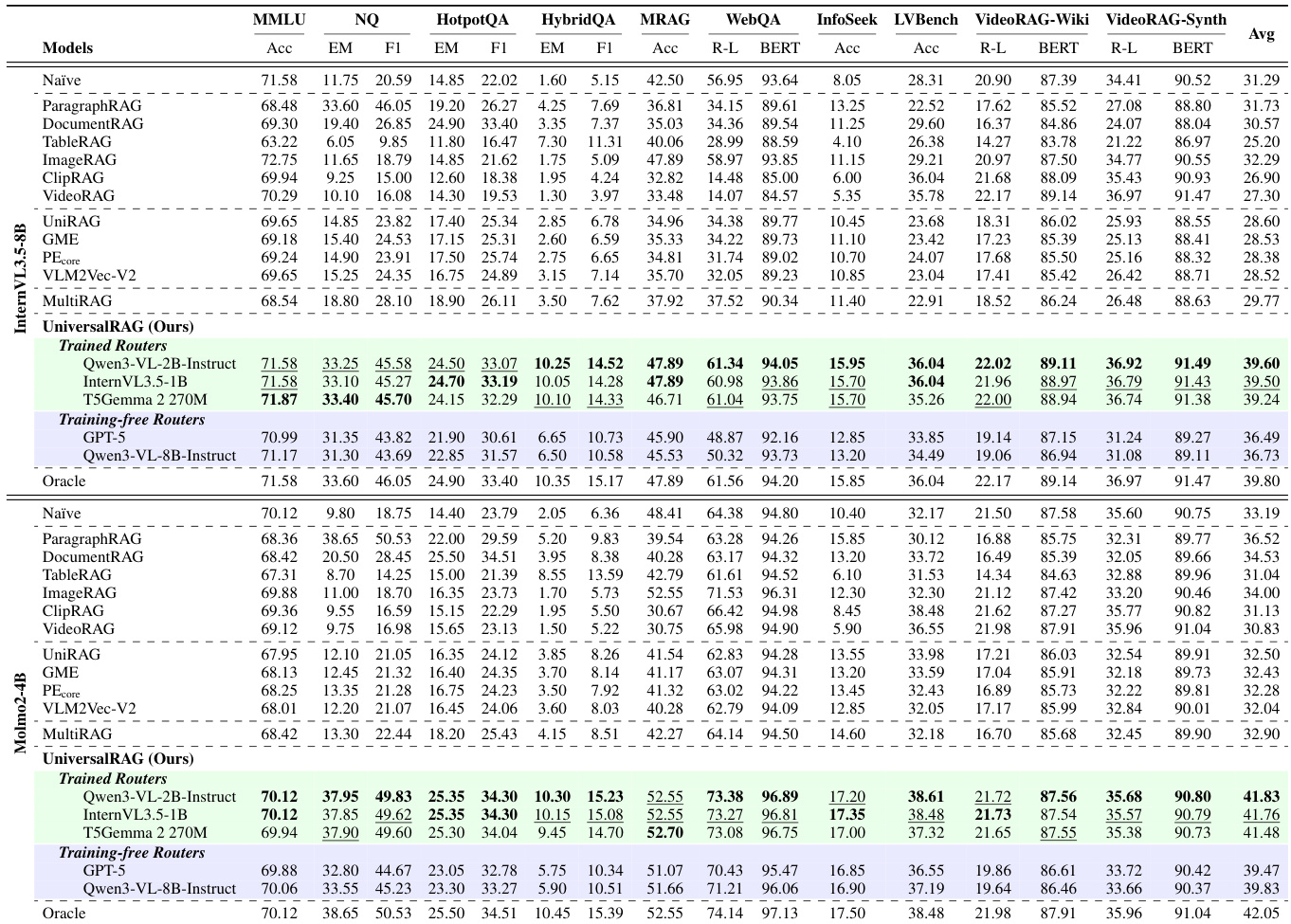
作者使用UniversalRAG在涉及多种模态与粒度的多样化RAG任务中评估其性能,与包括单模态、统一嵌入及多语料库多元模态方法在内的多种基线进行对比。结果表明,UniversalRAG在所有基准上持续取得最佳平均性能,其训练路由器变体超越所有基线并接近理想水平,而免训练路由器在不同场景中也展现出强泛化与鲁棒性。
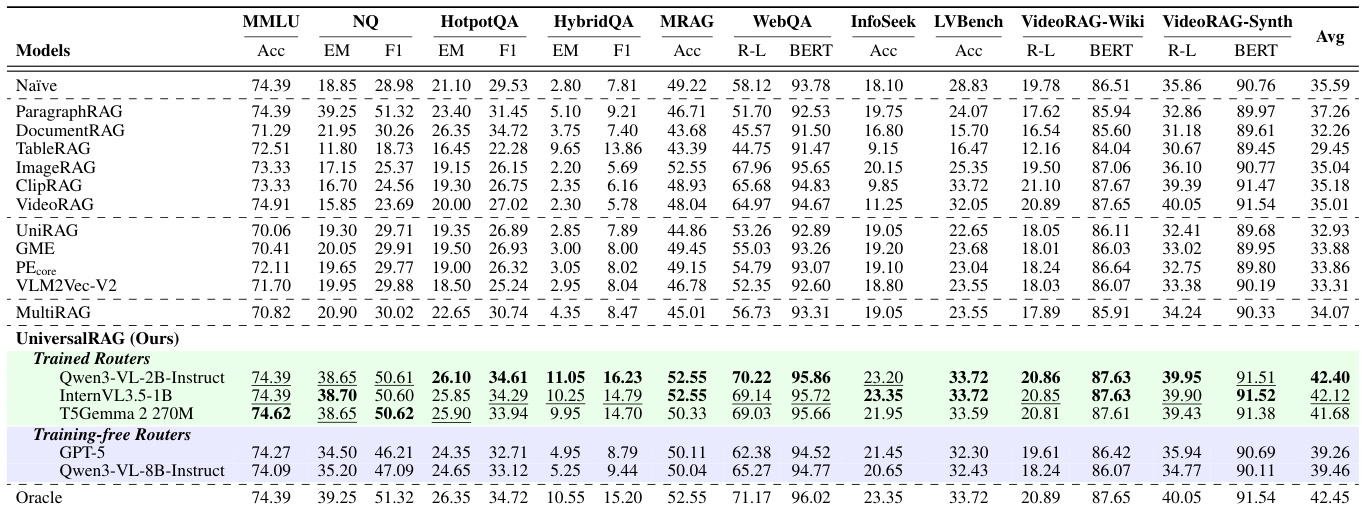
结果表明,UniversalRAG在三个大型视觉语言模型(Qwen3-VL-8B-Instruct、InternVL3.5-8B、Molmo2-4B)上均取得最高平均得分,全面优于所有基线方法,包括单模态RAG、统一嵌入模型与MultiRAG。与GME、VLM2Vec-v2等模型相比,性能提升尤为显著,这些模型表现出强模态偏差与较低检索准确率,而UniversalRAG的自适应路由实现了有效的跨模态与多粒度检索。
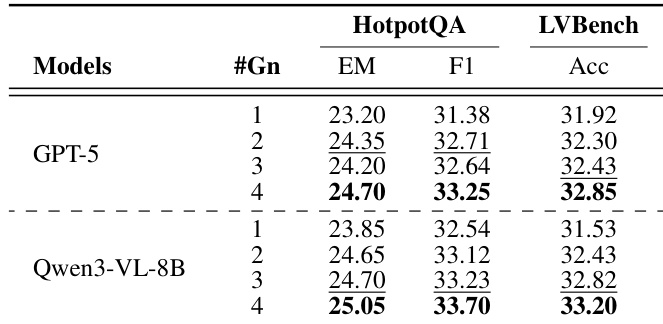
结果表明,采用免训练路由器(GPT-5)的UniversalRAG在HotpotQA与LVBench的不同粒度层级上均取得最佳性能,HotpotQA上EM与F1得分最高,LVBench上准确率最高。Qwen3-VL-8B模型表现具有竞争力,但GPT-5在所有粒度设置中均持续优于它,表明免训练路由方法的有效性。
作者使用免训练路由器的UniversalRAG在领域外数据集上评估其性能,与训练路由器变体及基线方法进行对比。结果表明,免训练路由器在领域外设置中取得最高平均得分,而结合训练与免训练路由器的集成策略实现最佳整体性能,证明其在未见数据上的鲁棒性与泛化能力。