Command Palette
Search for a command to run...
Kimi-Audio 技术报告
Kimi-Audio 技术报告
摘要
我们提出 Kimi-Audio,这是一个开源的音频基础模型,在音频理解、生成与对话任务中均表现出色。本文详细介绍了 Kimi-Audio 的构建实践,涵盖模型架构、数据筛选、训练策略、推理部署及评估方法。具体而言,我们采用 12.5Hz 的音频分词器(audio tokenizer),设计了一种基于大语言模型(LLM)的新颖架构,以连续特征作为输入,输出离散的 token 序列,并开发了一种基于流匹配(flow matching)的分块式流式反分词器(chunk-wise streaming detokenizer)。我们构建了一个包含超过 1300 万小时音频数据的预训练数据集,覆盖语音、声音与音乐等多种模态,并建立了一套高质量、多样化的后训练数据构建流水线。Kimi-Audio 以预训练的大语言模型为起点,通过一系列精心设计的任务,在音频与文本数据上进行持续预训练,随后进一步微调以支持多种音频相关任务。大量实验评估表明,Kimi-Audio 在多项音频基准测试中达到当前最优性能,涵盖语音识别、音频理解、音频问答以及语音对话等任务。我们已在 https://github.com/MoonshotAI/Kimi-Audio 开源代码、模型检查点及评估工具包。
一句话总结
作者提出Kimi-Audio,这是一个由Moonshot AI及合作者开发的开源音频基础模型,融合了12.5Hz音频分词器与基于大语言模型(LLM)的新型架构,支持连续特征输入与离散输出,通过持续预训练和基于流匹配的流式反分词技术,在音频理解、生成与对话任务中实现最先进性能,适用于语音识别、音频问答及多模态对话。
主要贡献
-
Kimi-Audio 是一个开源音频基础模型,旨在通过一种新颖的基于大语言模型(LLM)的架构,统一处理语音识别、音频理解与语音对话等多样化任务。该架构可处理连续声学特征与离散语义标记,并采用12.5Hz音频分词器,对齐音频与文本序列长度,实现高效的多模态建模。
-
模型在超过1300万小时的多样化音频(语音、音乐、环境声音)大规模预训练数据集上进行训练,并采用精心设计的高质量、任务特定微调数据管道,使其在多个领域表现出稳健性能,且无需依赖专有数据源。
-
大规模评估表明,Kimi-Audio 在关键基准测试(如语音识别、音频问答、语音对话)中达到最先进水平,其开源评估工具包确保了不同音频大模型之间公平、可复现的对比。
引言
传统音频处理通常依赖于特定任务的模型,限制了可扩展性与泛化能力。随着大语言模型(LLM)的发展,越来越多研究致力于在单一框架下统一音频理解与生成,利用音频的序列特性及其与文本的强对齐关系。然而,以往工作在多个关键方面仍存在不足:模型范围狭窄——或专注于理解或生成;缺乏对原始音频的鲁棒预训练;且常不公开代码或检查点,阻碍了可复现性与社区发展。
作者提出Kimi-Audio,一个开源的通用音频基础模型,统一实现语音识别、音频理解、音频生成与语音对话。为解决上述局限,作者设计了一种混合输入表示:在12.5Hz压缩率下结合离散语义标记与连续声学向量,实现高效而丰富的音频建模。模型从预训练文本LLM初始化,并基于1300万小时多样化音频数据,采用多阶段预训练策略——涵盖纯文本、纯音频、音频到文本映射及音频与文本交错任务——随后进行基于指令的微调。该方法在保持高语言智能的同时,实现了多领域强性能。
关键的是,作者同时发布模型与开源评估工具包,以确保公平基准测试,解决以往比较中因指标与协议不一致带来的问题。其工作标志着迈向通用音频智能的重要一步,聚焦于可访问性、可扩展性与自主性。
数据集
-
预训练数据集包含单模态(纯文本、纯音频)与多模态(音频-文本)数据,其中纯音频数据总计约1300万小时,来自真实世界多样来源,如有声书、播客与访谈,涵盖音乐、环境声、人类发声及多语言语音等丰富声学内容。
-
原始音频缺乏转录文本、语言标签、说话人标注与分段信息,常包含背景噪声、混响与说话人重叠等伪影。
-
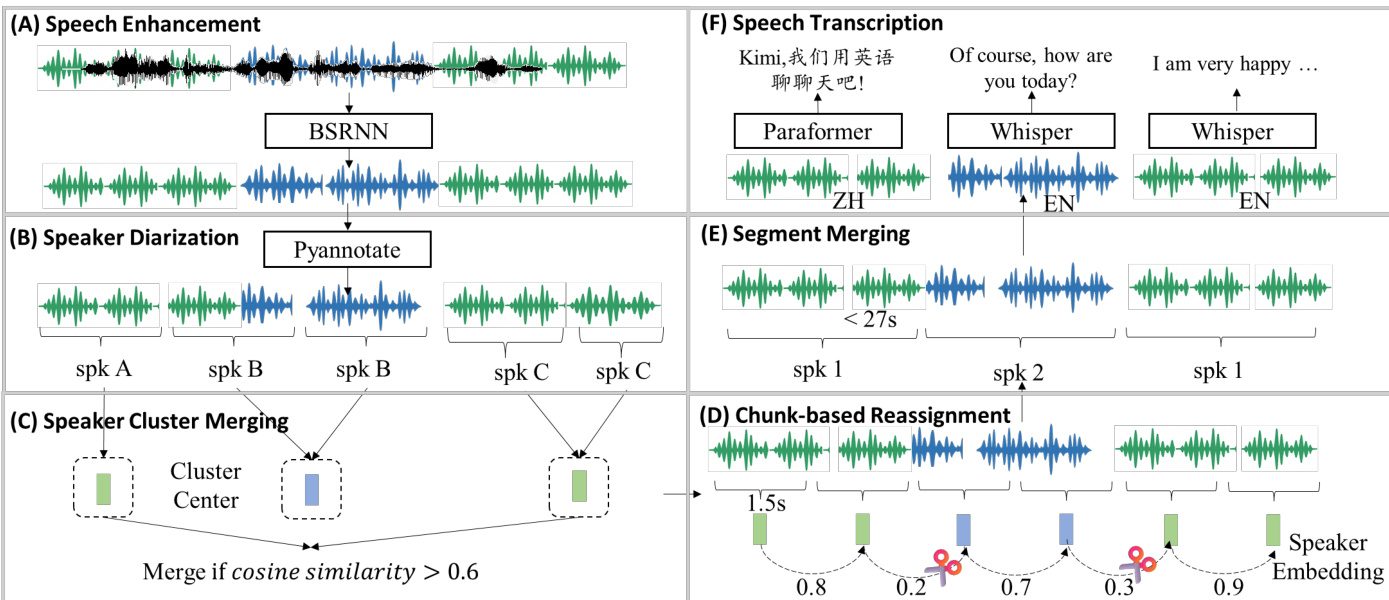
作者开发端到端音频数据处理流水线,生成高质量多模态标注,重点处理长时音频并保持上下文一致性——不同于以往侧重短片段的方法。
-
流水线包括:
- 语音增强:基于Band-Split RNN(BSRNN)模型在48kHz下进行降噪与去混响;预训练阶段以1:1比例使用原始或增强音频,以保留环境与音乐内容。
- 基于说话人分割的分段:使用PyAnnotate进行初始说话人分割,随后执行三步后处理:
- 说话人聚类合并:余弦相似度 > 0.6 的聚类合并,减少说话人碎片化。
- 块级重分配:将1.5秒块根据相似度阈值(<0.5 表示说话人变更)重新分配至说话人聚类。
- 段落合并:相邻同说话人段落若总长度超过27秒或静音间隔超过2秒,则合并。
- 语音转录:
- 语言检测使用Whisper-large-v3;仅保留英文与中文段落。
- 英文:Whisper-large-v3 提供转录与标点。
- 中文:Paraformer-Zh 生成带字符级时间戳的转录;标点根据字符间间隔添加(0.5–1.0秒为逗号,>1.0秒为句号)。
-
流水线在30台云实例集群上运行(每台128 vCores、1 TB RAM、8块NVIDIA L20 GPU),总计3,840 vCores、30 TB RAM与240块GPU,每日处理约20万小时音频。
-
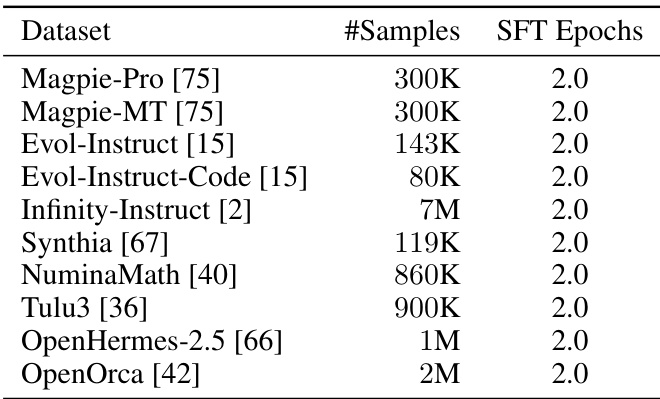
针对音频理解任务(ASR、AQA、AAC、SER、SEC、ASC),模型在开源数据集(表1)上进行微调,并补充5.5万小时内部ASR数据与5,200小时内部音频数据用于AAC/AQA。
-
针对语音对话能力,作者构建大规模多轮对话数据集:
- 用户查询由LLM生成,并通过Kimi-TTS系统转换为语音,使用多样化音色(12.5万+音色)。
- 助手回复由单一配音演员(Kimi-Audio说话人)合成,其预录了20+风格与每种风格5个强度级别的情感与风格变化。
- Kimi-TTS支持3秒提示下的零样本TTS,保留音色、情感与风格,基于100万小时合成数据训练,并通过强化学习优化。
- Kimi-VC实现语音转换,将多样真实场景语音转换为Kimi-Audio说话人音色,同时保留风格、情感与口音,基于配音演员录音进行微调。
-
针对音频到文本聊天任务,使用开源文本数据集(表2),将用户查询转为语音。文本预处理包括:
- 过滤复杂内容(数学、代码、表格、多语言文本或长输入)。
- 重写为口语化与清晰表达。
- 将单轮复杂指令转换为多轮、简洁的交互。
方法
Kimi-Audio模型采用统一框架,实现音频理解、生成与对话,集成三个核心组件:音频分词器、音频LLM与音频反分词器。整体架构设计用于处理多模态输入,并在单一模型中生成文本与音频输出。如框架图所示,系统从音频分词器开始,将原始音频输入转换为离散语义标记与连续声学特征。这些表示随后输入音频LLM,其采用共享Transformer架构进行跨模态处理。共享层从预训练文本LLM初始化,从文本与音频输入中提取联合表示,随后路由至专用并行头:文本头用于生成文本标记,音频头用于预测离散音频语义标记。预测的音频标记传递至音频反分词器,重建连贯音频波形。该模块化设计实现了对多样化音频-语言任务(如语音识别、音频理解、语音对话)的无缝处理,统一于单一模型框架。
音频分词器采用混合策略表示音频信号,结合离散语义标记与连续声学特征。其利用从自动语音识别(ASR)模型导出的监督语音分词器,基于Whisper编码器架构中的向量量化技术,将连续语音表示转换为12.5Hz帧率的离散标记。同时,从预训练Whisper模型中提取连续特征表示,运行于50Hz帧率。为对齐时间分辨率,引入适配器将Whisper特征下采样至12.5Hz,再与离散语义标记的嵌入拼接。该联合表示作为音频LLM的输入,使模型同时受益于离散标记的语义基础与连续特征的丰富声学细节。
音频LLM通过处理分词器的多模态输入,实现文本与音频输出的生成。其采用共享Transformer架构,初始层在两种模态间共享,使模型能够学习跨模态表示。共享层之后,架构分叉为两个并行头:文本头用于自回归预测文本标记,音频头用于预测离散音频语义标记。共享Transformer层与文本头从预训练文本LLM初始化,确保强语言能力;音频头则随机初始化。该初始化策略使模型在保留强大文本理解与生成能力的同时,有效学习音频处理与生成。
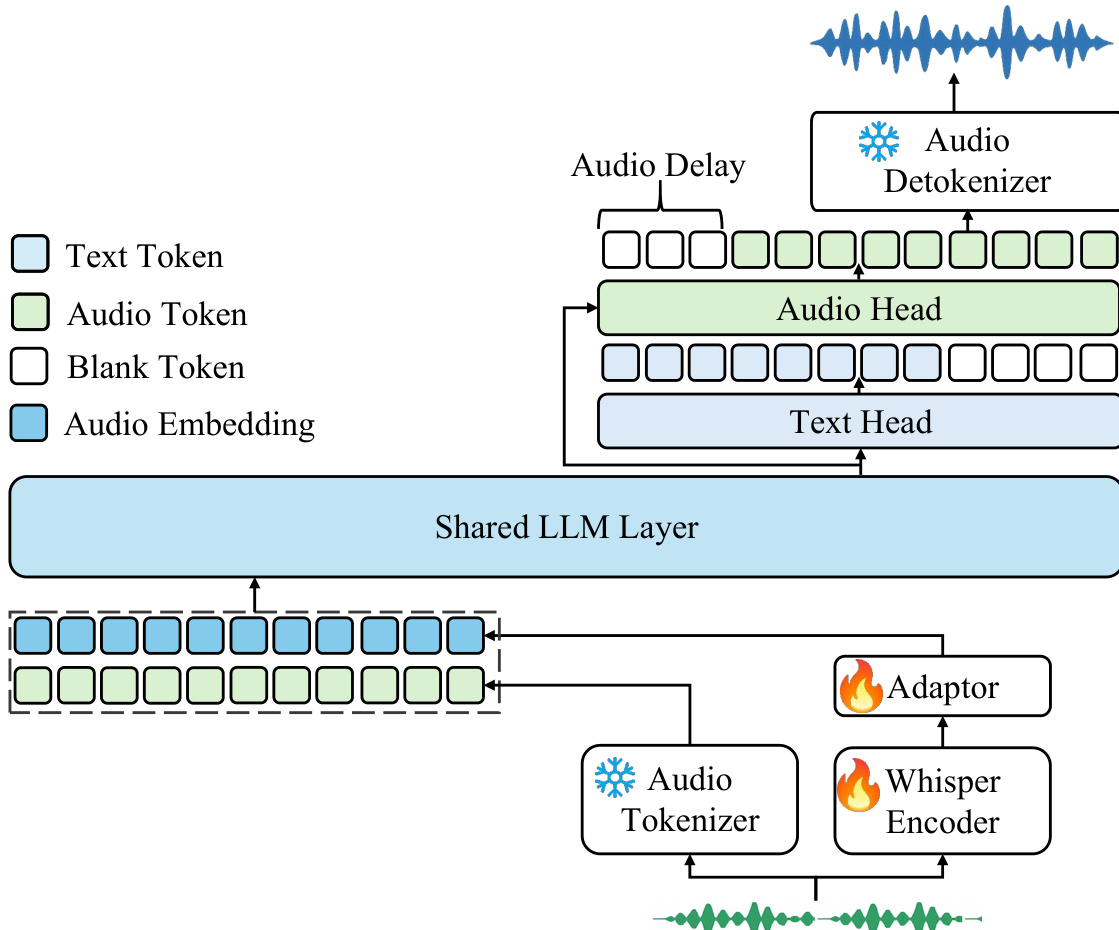
音频反分词器将音频LLM预测的离散语义标记转换为连贯音频波形。其包含两个主要组件:流匹配模块,将12.5Hz语义标记转换为50Hz梅尔频谱图;声码器,从梅尔频谱图生成波形。为降低延迟,实现分块流式反分词器,将音频按块处理(如每块1秒)。该方法在训练与推理中使用分块因果掩码,每块处理时包含所有先前块的上下文。为解决块边界处的间歇性问题,引入前瞻机制,将下一区块的未来语义标记纳入当前块处理。该机制无需训练,仅延迟首块生成数个标记,确保高质量音频合成。
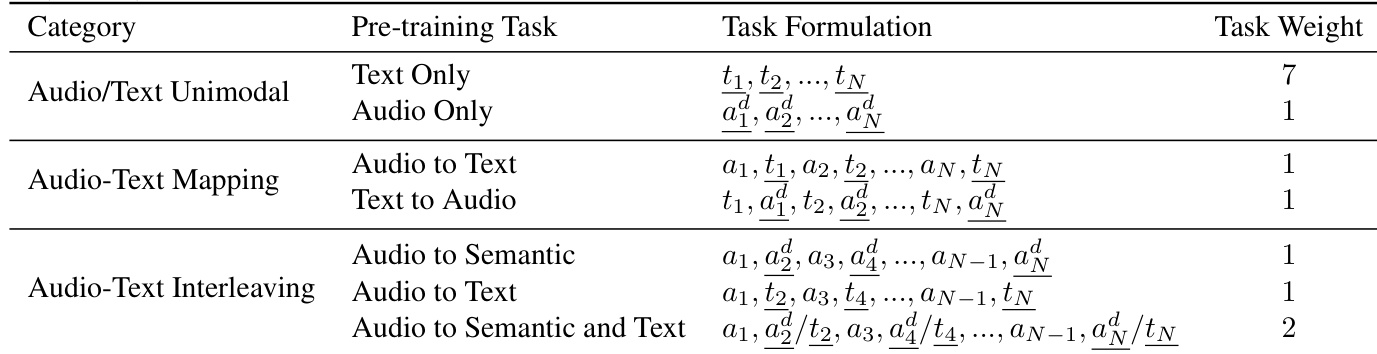
Kimi-Audio的预训练包含多个任务,旨在从音频与文本领域学习知识,并在模型潜在空间中对齐二者。这些任务包括单模态预训练(音频与文本)、音频-文本映射预训练与音频-文本交错预训练。单模态预训练中,对文本标记与离散音频标记分别应用下一项预测。音频-文本映射任务中,将ASR与TTS任务建模,学习音频与文本对齐。交错预训练设计三种任务:音频到语义标记交错、音频到文本交错、音频到语义标记+文本交错。模型从Qwen2.5 7B模型初始化,并扩展语义音频标记与特殊标记。预训练使用585B音频标记与585B文本标记,特定任务权重,连续声学特征提取器初始冻结,后期微调。
音频反分词器训练分为三个阶段。第一阶段,流匹配模型与声码器在大量音频数据上预训练,学习多样音色、语调与质量。第二阶段,在相同预训练数据上采用动态块大小的分块微调策略。第三阶段,在高质量单说话人录音数据上微调,以提升生成音频质量。
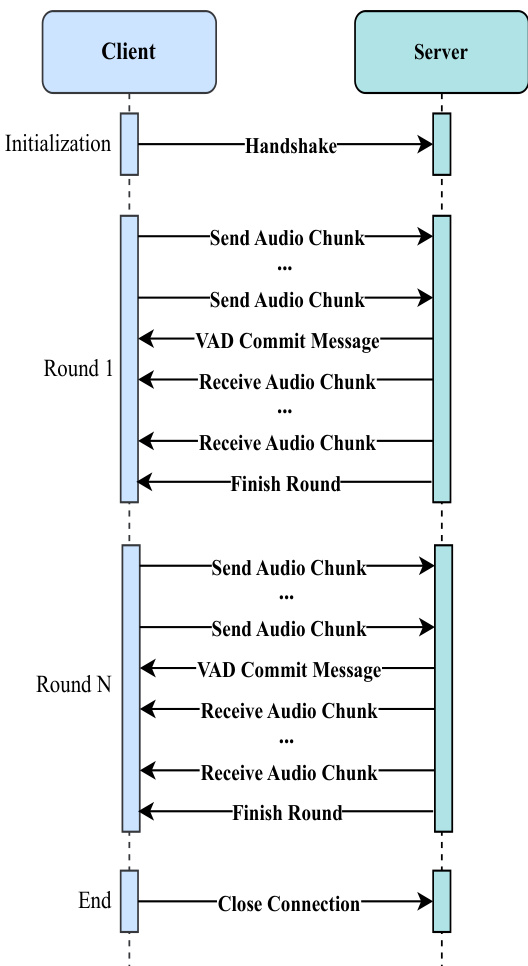
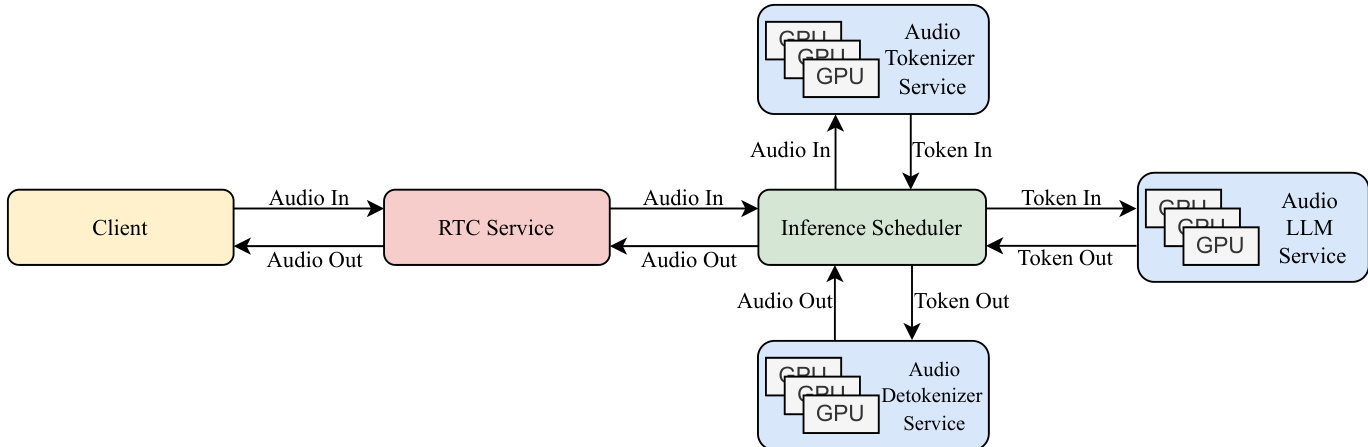
推理与部署设计用于实时语音到语音对话。工作流程为:客户端发送音频块至服务器,服务器使用音频分词器、音频LLM与音频反分词器处理输入,随后将音频块返回客户端播放。生产部署架构为模块化,音频分词器、音频LLM与音频反分词器各服务配备负载均衡器与多个推理实例,实现并行处理。推理调度器管理对话流程,维护对话历史并协调每轮交互处理。
实验
- 在音频理解、语音对话与音频到文本聊天数据上进行监督微调(SFT),以增强指令遵循与音频处理能力。
- 使用AdamW优化器、余弦衰减学习率(1e-5至1e-6)与10%预热标记,对Kimi-Audio进行2–4轮微调。
- 开发开源评估工具包,解决音频基础模型中的可复现性问题,包含标准化WER计算与基于GPT-4o-mini的智能语义判断。
- 在语音识别(ASR)上达到最先进水平:LibriSpeech test-clean为1.28 WER,AISHELL-1为0.60 WER,AISHELL-2 ios为2.56 WER,优于Qwen2-Audio-base与Qwen2.5-Omni。
- 在音频理解方面表现卓越:MMAU声学类别73.27,语音类别60.66,MELD情感识别59.13,非语音声与声学场景分类任务取得最高分。
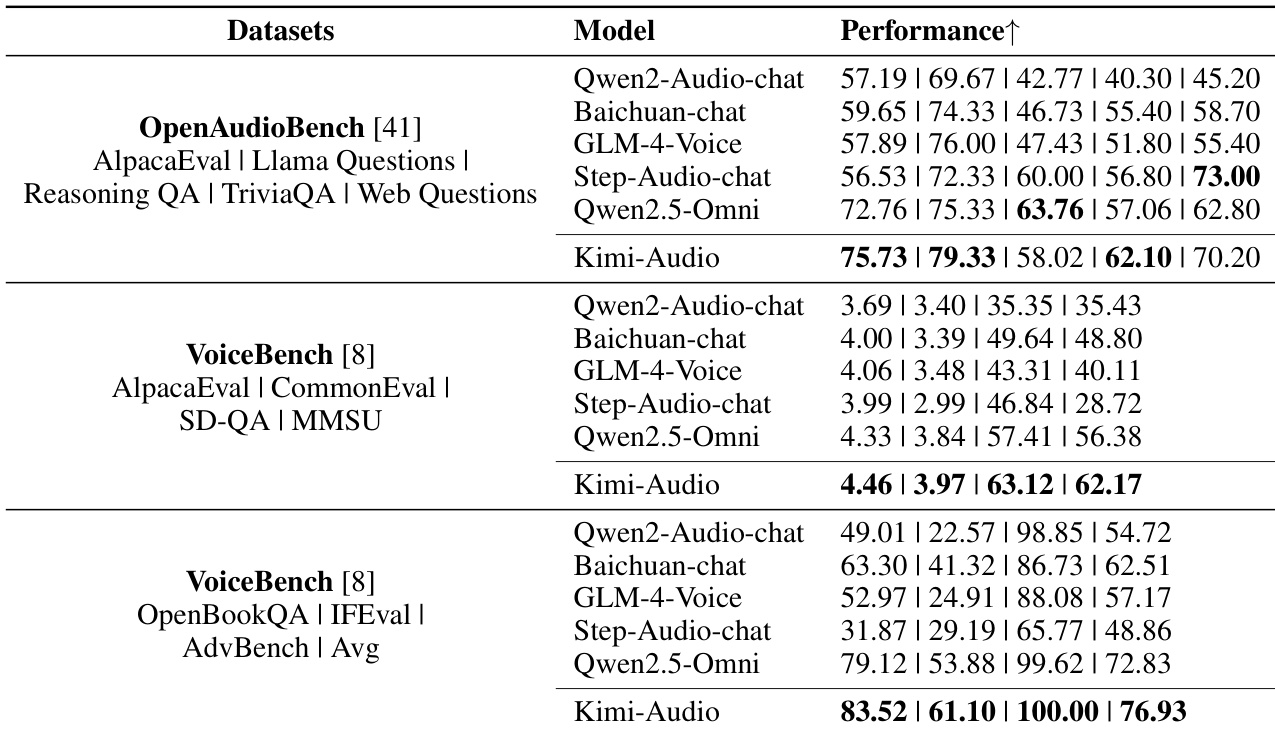
- 在音频到文本聊天任务中达到SOTA性能:在OpenAudioBench(AlpacaEval、Llama Questions、TriviaQA)领先,VoiceBench上全面超越所有基线(如AlpacaEval 4.46,Advbench 100.00)。
- 展现出强大的端到端语音对话能力:平均人类评分3.90(1–5分制),在情感控制与共情方面最高,整体仅次于GPT-4o(4.06)。
作者采用结构化方法定义Kimi-Audio的预训练任务,将其分为音频/文本单模态、音频-文本映射与音频-文本交错任务,具有不同公式与权重。该设计强调音频-文本与文本-音频对齐的重要性,同时引入交错音频-文本交互以增强多模态理解。
作者使用表格评估Kimi-Audio在多个基准测试(MMAU、ClothoAQA、VocalSound、Nonspeech7k、MELD、TUT2017、CochlScene)上的音频理解性能。结果显示,Kimi-Audio在多数基准上取得最高分,表明其在理解音乐、声音事件与语音方面优于其他模型。

作者在多个SFT数据集上采用一致的微调策略,每数据集训练2.0轮,使用相同超参数。该统一方法确保了在监督微调中不同数据源间模型性能的公平比较。
作者使用OpenAudioBench与VoiceBench数据集评估Kimi-Audio在音频到文本聊天任务中的表现,与多个基线模型对比。结果表明,Kimi-Audio在多个子任务(AlpacaEval、Llama Questions、TriviaQA)中达到最先进水平,并在SD-QA、MMSU与OpenBookQA等关键指标上全面超越所有对比模型。
作者通过人类评分评估Kimi-Audio的语音对话能力,涵盖情感控制、共情与风格控制等维度。结果显示,Kimi-Audio在速度控制与情感控制方面得分最高,整体平均分3.90,仅次于GPT-4o,优于所有其他模型。
