Command Palette
Search for a command to run...
DreamO:一种统一的图像定制框架
DreamO:一种统一的图像定制框架
摘要
近期,针对图像定制化(如身份、主体、风格、背景等)的大量研究展示了大规模生成模型在定制化能力方面的强大表现。然而,大多数现有方法仅针对特定任务设计,限制了其在融合多种不同类型条件时的通用性。因此,构建一个统一的图像定制化框架仍是当前尚未解决的开放性挑战。本文提出DreamO,一种旨在支持广泛定制化任务并实现多种控制条件无缝融合的图像定制化框架。具体而言,DreamO采用扩散Transformer(Diffusion Transformer, DiT)架构,统一处理各类输入数据。在训练阶段,我们构建了一个大规模的训练数据集,涵盖多种定制化任务,并引入特征路由约束机制,以实现从参考图像中精准检索相关特征信息。此外,我们设计了一种占位符策略,通过将特定占位符与特定位置的条件进行绑定,从而实现对生成结果中条件布局的精确控制。为进一步提升模型性能,我们采用一种三阶段渐进式训练策略:第一阶段聚焦于简单任务与有限数据,旨在建立基础的一致性;第二阶段为全规模训练,全面增强模型的定制化能力;第三阶段为质量对齐阶段,用于修正由低质量数据引入的生成质量偏差。大量实验结果表明,所提出的DreamO框架能够高质量地完成多种图像定制化任务,并灵活整合多种类型的控制条件,在性能与灵活性方面均展现出显著优势。
一句话总结
字节跳动智能创作团队与北京大学的研究者提出 DreamO,一种基于统一扩散 Transformer 的框架,通过引入特征路由约束和占位符策略,解耦并精确控制身份、风格、主体和试穿属性,实现高保真、多条件图像定制,能够无缝融合多种条件,具备强泛化能力与高质量生成效果。
主要贡献
-
DreamO 提出了一种统一的图像定制框架,通过利用预训练扩散 Transformer(DiT)并仅需少量额外训练,支持身份保留、风格迁移和虚拟试穿等多种任务,实现多种条件类型的无缝集成。
-
该方法在训练过程中引入特征路由约束,通过利用内部表示的对应关系增强内容保真度并解耦不同控制条件;同时采用占位符策略,实现对生成图像中条件位置的精确空间控制。
-
通过渐进式训练策略与大规模多任务数据,DreamO 在复杂定制场景中实现稳定收敛与高质量结果,在视觉质量与灵活性方面均优于现有任务专用及多条件方法。
引言
研究者利用扩散 Transformer(DiT)应对身份保留、风格迁移和虚拟试穿等应用中日益增长的灵活、高质量图像定制需求。以往方法或聚焦单一任务且条件交互僵化,或依赖通用模型而缺乏针对多条件控制的专门设计,导致保真度差且集成能力有限。DreamO 引入统一框架,通过共享输入序列处理身份、风格、主体和布局等多种条件,利用特征路由约束确保精确、解耦的控制。同时采用占位符策略实现空间定位,并通过渐进式训练机制稳定复杂多概念场景下的学习过程,使单一模型在极低训练开销下实现高保真、灵活的图像定制。
数据集
- 数据集由多个任务特定子集构成,用于支持跨身份、主体、试穿、风格和路由任务的通用图像定制。
- 身份配对数据:使用 PuLID-FLUX 和 PuLID-SDXL 生成 15 万张写实身份对与 6 万张风格化身份对,通过相互参考图像或文本提示引导风格变化。
- 主体驱动数据:基于 Subject200K 的 20 万张单主体图像,通过语义搜索获取 10 万张角色相关配对数据进行增强。对于多主体任务,通过拼接 Subject200K 样本生成双列图像,并引入 X2I-subject 数据集。受 MovieGen 启发的流水线提升人像驱动生成效果。
- 试穿数据:从网络爬取的模特-服装配对中构建 50 万张配对图像,采用两步流程:高质量模特图像收集、服装分割与配对。所有数据均经过人工筛选以保证质量。
- 风格驱动数据:对于文本引导的风格迁移,使用内部基于 SDXL 的模型生成风格一致但内容多变的图像;对于图像引导的风格迁移,使用 Canny 引导的 Flux 生成配对的风格参考、内容参考与目标图像。
- 路由掩码提取:使用 LISA 根据文本提示生成对象掩码;在复杂情况下由 InternVL 提供对象描述,以支持路由约束的标签生成。
- 数据通过任务特定流水线处理:使用 Mask2Former 进行场景检测与对象追踪,利用 SigLip 嵌入与聚类实现跨 CLIP 实例匹配。
- 训练过程中,数据按任务特定比例混合,使模型涌现出联合身份与试穿定制等跨任务能力,尽管未显式训练此类组合。
方法
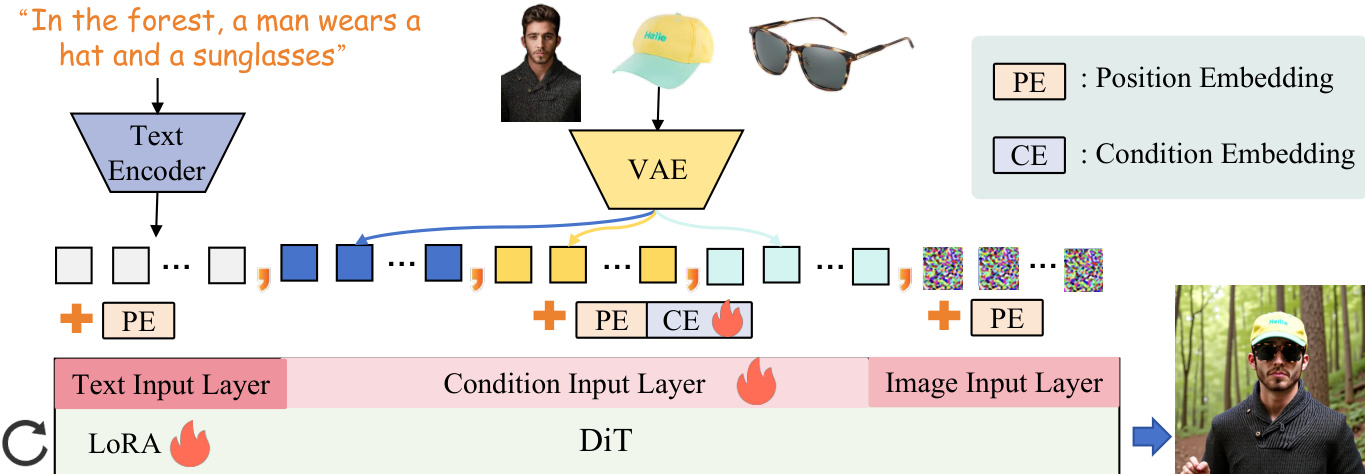
研究者采用扩散 Transformer(DiT)作为核心去噪网络,通过将二维图像隐空间分块为一维标记序列,统一处理图像与文本输入。该方法基于 Flux-1.0-dev 模型,作为所提方法的基础架构。框架支持灵活的条件输入,多个条件图像通过 Flux 的变分自编码器(VAE)组件编码至同一隐空间。这些条件标记随后与文本和图像标记沿序列维度拼接,并输入 DiT 模型。为确保位置信息正确对齐,在 Flux 输入端引入条件映射层,使用旋转位置嵌入(RoPE)将条件标记的位置嵌入与噪声隐空间对齐。作者进一步引入可训练的、逐索引的条件嵌入(CE),大小为 10×c,直接加至条件标记。此外,将低秩适应(LoRA)模块集成至 DiT 架构中,以实现模型参数的高效微调。
该方法引入路由约束机制,引导模型注意力聚焦于生成输出中的特定区域。如图所示,在 DiT 框架内建立条件图像标记与噪声图像隐空间标记之间的交叉注意力。交叉注意力图 M 计算为 M=dQcond,iKimgT,其中 Qcond,i 表示第 i 个条件图像的条件标记,Kimg 表示噪声图像隐空间的标记。为获得条件图像在生成输出中的全局响应,沿条件标记维度对注意力图取平均,得到响应图 M∈Rl。该响应图用于计算均方误差(MSE)损失 Lroute,优化注意力聚焦以对齐目标主体掩码。该约束确保模型注意力指向条件图像的相关区域,提升生成结果的一致性与细节保真度。
为进一步增强文本描述与条件输入之间的对齐,作者设计了占位符到图像的路由约束。该机制建立文本占位符与其对应条件图像之间的对应关系。训练期间,将如 [ref#1] 等占位符附加至文本描述,模型学习将占位符的文本标记与条件图像标记关联。路由约束强制最大化条件图像 Ci 与其对应占位符 [ref#i] 之间的相似性,同时最小化与其他占位符的相似性。这通过损失函数 Lholder 实现,其计算注意力得分的 softmax 与二值矩阵 Bi 之间的 MSE,其中仅当占位符与条件图像匹配时值为 1。该策略确保模型正确将文本引用映射至其对应的视觉输入,提升多参考图像生成的准确性。
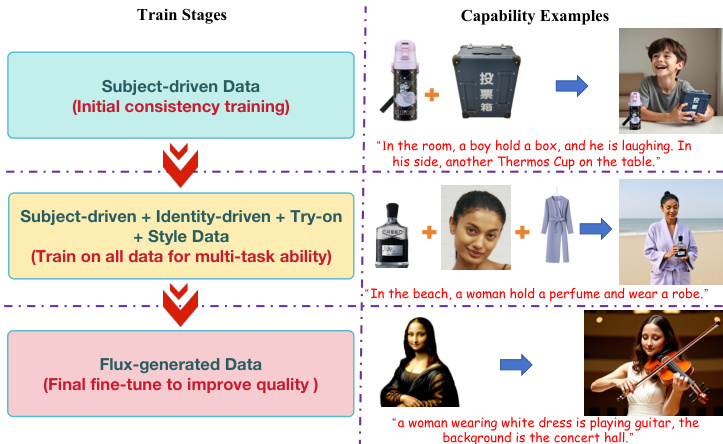
整体训练目标将扩散损失、路由约束损失与占位符路由损失合并为单一损失函数:L=λdiff⋅Ldiff+λroute⋅Lroute+λholder⋅Lholder。扩散损失 Ldiff 来自 Flow Matching 框架,模型被训练为在给定噪声隐空间、时间步与条件的情况下回归目标速度。路由与占位符损失设计为计算高效,对训练过程增加极小开销。方法还引入概率机制,以 50% 概率使用普通文本输入,使模型可处理条件与无条件文本输入。训练流程分阶段进行:首先在主体驱动数据上进行初始一致性训练,随后在主体、身份与风格数据上进行多任务训练,最后在 Flux 生成数据上进行微调以提升整体质量。
实验
- 渐进式训练策略验证了收敛性与生成质量的提升:在 Subject200K 上的初始预热加速了主体驱动生成的学习,全数据调优增强了多任务性能,图像质量优化使输出与 Flux 的生成先验对齐,显著提升保真度。
- 在 DreamBench 与多主体基准测试中,DreamO 在主体一致性(CLIP 与 Dino 相似性)与文本跟随能力方面表现优异,优于 MS-Diffusion、OmniGen 与 OminiControl 等方法。
- 在 Unsplash-50 上,DreamO 在人脸相似性(ID 余弦)与文本对齐(CLIP 相似性)方面优于 PhotoMaker、InstantID 与 PuLID。
- 在虚拟试穿任务中,DreamO 在试穿准确率(与参考服装的 CLIP 相似性)与文本跟随能力方面均表现卓越,超越缺乏文本对齐能力的 IMAGDressing。
- 在风格定制任务中,DreamO 实现最高风格一致性(CSD 相似性)与内容一致性(与提示的 CLIP 相似性),优于 StyleShot、StyleAlign、InstantStyle、DeaDiff 与 CSGO。
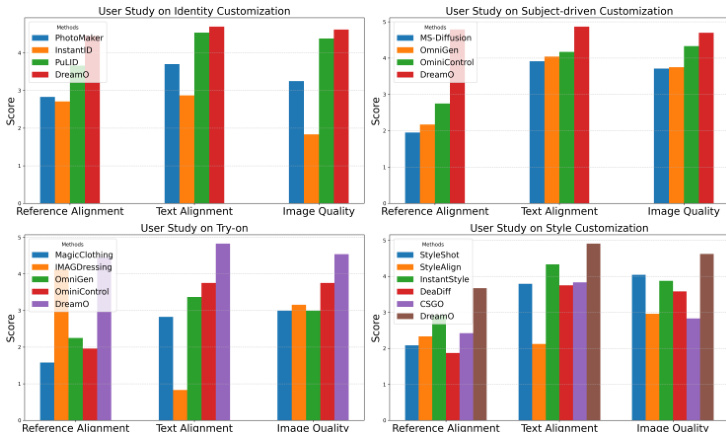
- 用户研究确认 DreamO 在所有任务中均在文本对齐、参考对齐与图像质量方面排名第一,平均得分超过 5 分制的 4.0。
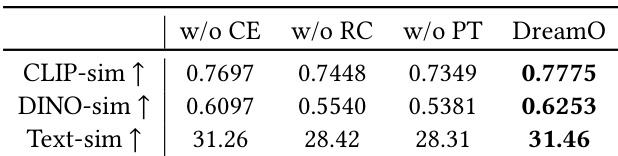
- 消融实验验证了路由约束与渐进式训练的关键作用:移除后导致参考保真度下降、条件耦合、一致性与文本跟随性能降低。
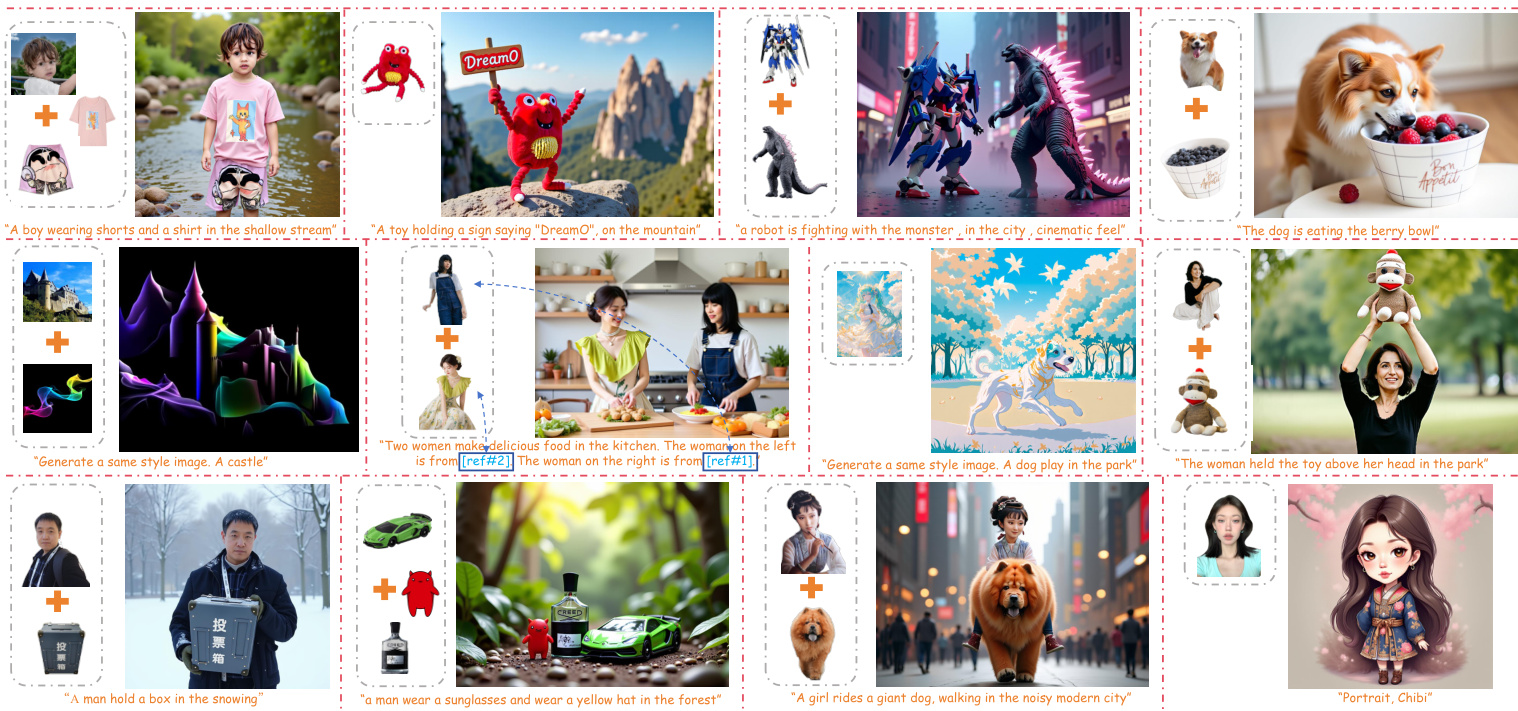
结果表明,DreamO 在单主体与多主体定制任务中均优于 MS-Diffusion、OmniGen 与 OminiControl,主体一致性方面取得最高 CLIP-sim 与 DINO-sim 分数,文本跟随能力方面取得最高 text-sim 分数。模型在不同条件下均表现出卓越的参考保真度与文本对齐能力。

结果表明,DreamO 在所有对比方法中实现最高人脸相似性(0.607)与文本相似性(0.2570),在身份定制指标上优于 PhotoMaker、InstantID 与 PuLID。作者利用这些定量结果证明 DreamO 在身份驱动生成任务中具备更强的身份保留能力与文本提示跟随能力。

研究者开展用户研究,评估 DreamO 与多种先进方法在四个定制任务(身份、主体驱动、试穿、风格)上的表现。结果表明,DreamO 在所有任务中均在参考对齐、文本对齐与图像质量方面取得最高分,表明其在对齐用户输入与保持高质量输出方面表现卓越。
结果表明,DreamO 在所有指标上均优于无条件嵌入、路由约束或渐进式训练的消融版本。完整模型在 CLIP-sim、DINO-sim 与 text-sim 上均取得最高值,展现出卓越的主体一致性和文本跟随能力。
结果表明,DreamO 在所有对比方法中实现最高 Style-sim 与 Text-sim 分数,表明其在风格一致性与文本对齐方面表现优异。模型在两项指标上均优于 StyleAlign、StyleShot、InstantStyle、DEADiff 与 CSGO,证明其在保持参考风格与遵循文本描述方面的有效性。
