Command Palette
Search for a command to run...
DiffVox:一种用于捕捉与分析专业效果分布的可微分模型
DiffVox:一种用于捕捉与分析专业效果分布的可微分模型
Chin-Yun Yu Marco A. Martínez-Ramírez Junghyun Koo Ben Hayes Wei-Hsiang Liao György Fazekas Yuki Mitsufuji
摘要
本研究提出了一种新颖且可解释的模型——DiffVox(全称“可微分人声效果”,Differentiable Vocal Fx),用于音乐制作中人声效果的匹配。DiffVox 将参数化均衡器、动态范围控制、延迟(delay)和混响(reverb)等效果模块,通过高效的可微分实现方式集成在一起,从而支持基于梯度的优化方法,实现参数估计的自动化。人声预设从两个数据集获取,分别包含来自 MedleyDB 的 70 首曲目以及一个私有数据集中的 365 首曲目。对参数相关性的分析揭示了各类效果与参数之间存在显著关联:例如,高通滤波器与低频 Shelf 滤波器常协同作用以塑造低频响应;延迟时间与延迟信号的强度之间也表现出明显的相关性。主成分分析(PCA)进一步揭示了与 McAdams 音色维度之间的联系,其中首要主成分调控听觉上的空间感,而次要成分则影响频谱亮度。统计检验结果证实,参数分布并非服从高斯分布,凸显了人声效果空间的复杂性。这些关于参数分布的初步发现,为人声效果建模及自动混音技术的后续研究奠定了重要基础。本文的源代码与数据集已开源,可通过 https://github.com/SonyResearch/diffvox 获取。
一句话总结
来自伦敦玛丽女王大学、索尼AI和索尼集团的作者提出了DiffVox,一种可微分的声乐效果模型,整合了参数化均衡、动态范围控制、延迟和混响,并采用高效的GPU加速可微分实现,支持基于梯度的参数优化;该模型揭示了非高斯的参数分布,并将效果配置与McAdam的音色维度相关联,实现了可解释的声乐处理,推动了音乐制作中的自动混音发展。
主要贡献
- DiffVox引入了一种可微分且可解释的声乐效果匹配模型,用于音乐制作,集成了参数化均衡、动态范围控制、延迟和混响,并采用高效的GPU加速可微分实现,支持基于梯度的参数估计。
- 该模型应用于MedleyDB中的435个声乐音轨及一个私有数据集,揭示了显著的参数相关性——如高通与低 shelf 滤波器的共用——并表明参数空间的主成分与McAdam的音色维度(尤其是空间感和频谱亮度)高度对齐。
- 统计分析证实了效果参数分布的非高斯特性,挑战了音频处理中常见的均匀或高斯先验假设,作者发布了源代码和数据集,以支持未来在音频效果建模方面的研究。
引言
作者利用可微分信号处理技术开发了DiffVox,一种能够实现基于梯度优化的声乐效果参数估计模型,用于音乐制作。该方法对于自动化和优化声乐处理任务至关重要,因为精确控制均衡、压缩、延迟和混响是实现专业音质的关键。以往工作在非可微分的效果链和可解释性方面存在困难,导致自动参数调优困难,通常依赖启发式或试错方法。DiffVox通过提供关键效果的高效可微分实现,克服了这些限制,支持端到端优化。模型对真实世界声乐预设的分析揭示了有意义的参数相关性,并与感知音色维度相关联,表明声乐效果在结构化且非高斯的空间中运行。这些洞见为更智能、数据驱动的自动混音和声乐制作工具奠定了基础。
数据集
-
数据集包含两个来源:MedleyDB(76个音轨)和一个名为Internal的私有多轨数据集(370个音轨),均以44.1 kHz采样。Internal聚焦于现代主流西方音乐,包含配对的干音和湿音音轨,而MedleyDB提供官方元数据以识别声乐音轨。
-
对于Internal数据集,作者通过互相关分析恢复干音与湿音之间的配对关系,因为未提供显式配对信息。非声乐音轨根据文件名模式过滤掉。仅保留源自单一原始音轨的音轨,以匹配单声道输入、立体声输出的问题设定。
-
立体声输入音轨通过峰值归一化两个声道,计算其差值(侧声道),并丢弃侧声道最大能量超过-10 dB的音轨。随后将两个声道平均以形成单声道源。时间对齐用于确保干音与湿音信号之间的最佳互相关。
-
每个音轨使用pyloudnorm归一化至-18 dB LUFS。提取12秒片段,重叠5秒,最终7秒用于损失计算,重叠部分作为预热。静音段被移除,每个训练步骤最多选择35个片段组成批次。
-
模型每音轨训练2,000步,使用Adam优化器,学习率为0.01。基于最小损失选择最佳检查点。训练在单个RTX 3090 GPU上进行,每音轨耗时20至40分钟。
-
为处理模型未捕捉的非线性效果(如失真或调制),若拟合运行显示高最小损失、损失波动不稳定或无持续下降,则丢弃该运行。这导致MedleyDB中排除6个音轨(约8%),Internal中排除5个(约1.3%)。
-
模型参数初始化接近恒等变换,以确保训练稳定。关键初始化包括:PEQ峰值滤波器增益设为零,LP/HP滤波器截止频率固定,动态范围控制、延迟和FDN混响设置特定初始值。延迟的脉冲响应长度设为4秒,FDN混响设为12秒,阻尼因子范围限制T60不超过9秒,以减少混叠。
-
对130个核心参数(排除代理变量和下三角logits)进行Spearman相关性分析,以研究参数间关系。观察到延迟时间与反馈/增益之间存在高相关性,表明感知效果强度存在权衡。PEQ滤波器增益与Q因子之间、压缩器阈值与增益补偿之间也存在强相关性。
-
值得注意的是,高于19.7 kHz的高频衰减系数与LP滤波器截止频率相关,表明混响通过降低衰减率来补偿高频损失。这提示潜在改进方向,如提高LP截止频率上限或增加湿/干混合控制。
-
按效果类型的相关性分析通过层次聚类揭示三个主要簇:空间效果、HP与LS滤波器,以及其余效果。LS滤波器自相关性较低,与HP滤波器中等相关,表明其独立运行,并与HP滤波器协同塑造低频。
方法
作者利用一种可微分的音频效果模型,旨在反映专业音乐制作实践,同时支持在GPU上的高效训练。整体框架如图所示,将单声道输入信号通过一系列效果处理,生成立体声输出。信号首先通过参数化均衡器(PEQ),然后经过压缩器与扩展器(COMP)作为动态范围控制器。处理后的信号被分为干音和湿音路径。干音经声像定位后与湿音混合,湿音则经过乒乓延迟(DLY)和反馈延迟网络(FDN)混响处理。最终输出为立体声混合。该架构专为单轨、单声道输入、立体声输出场景设计,聚焦于声乐处理,以捕捉真实的效应配置。
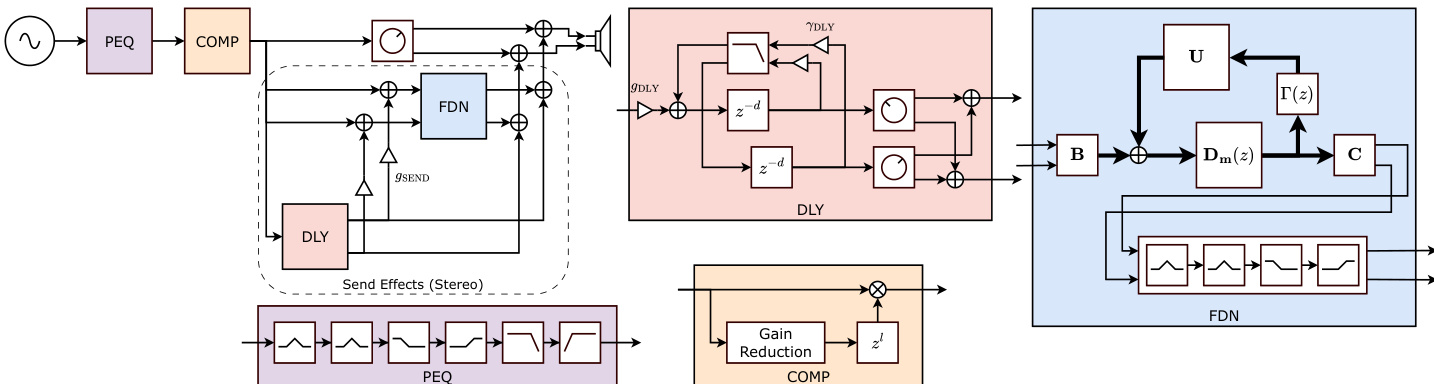
参数化均衡器(PEQ)应用六个滤波器:两个峰值、一个低 shelf、一个高 shelf、一个低通和一个高通,均以Biquad滤波器实现。为加速计算,作者采用并行前缀和算法,将递归滤波计算表示为结合操作,从而在GPU上实现高效反向传播。压缩器与扩展器(COMP)模型使用阈值、比率、攻击/释放时间以及RMS平滑参数,其可微分实现也得益于一阶滤波器的并行扫描。通过截断sinc插值近似连续延迟时间,学习了前瞻功能。
乒乓延迟(DLY)采用两条延迟线,交替在左右声道之间切换,每条线配有独立的声像器和反馈路径中的低通滤波器。延迟时间通过频率采样方法学习,将效果表示为有限脉冲响应的卷积。反馈延迟网络(FDN)混响使用六条延迟线组成的立体声网络,延迟时间互质。FDN的传递函数通过频率采样近似,频率依赖的衰减滤波器通过在49个点采样其幅度响应进行参数化。在脉冲响应上应用混响后PEQ,以校正频率相关的衰减和初始增益。模型还包含效果发送,即延迟信号被发送至混响以进行色彩化,由发送电平参数控制。
该模型总参数量为152,相比更表达性强的模型显著减少,优先考虑紧凑表示以利于分析。参数通过特定函数参数化,确保其始终处于有效范围内。训练过程通过最小化复合损失函数来优化效果参数。该损失结合多尺度STFT(MSS)损失,匹配预测信号与真实信号在三个尺度上的幅度谱图;以及多尺度响度动态范围(MLDR)损失,通过比较不同积分时间下的响度动态来匹配信号的微动态。还包含对代理变量η的正则化项,以促使阻尼正弦近似收敛至单位圆。最终损失为这些分量的加权和,应用于立体声输出的左、右、中、侧四个声道。
实验
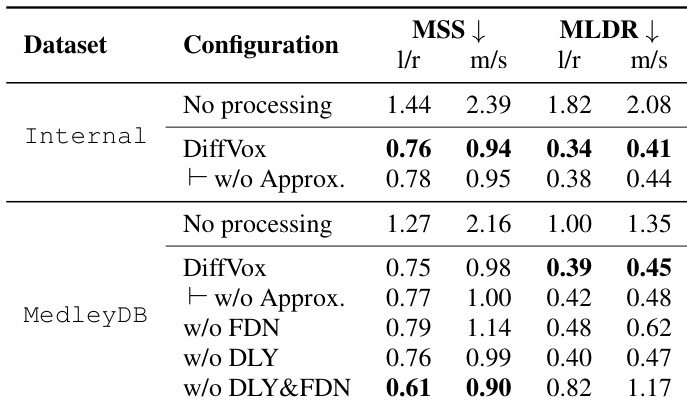
- 包含空间效果(PEQ、压缩器、延迟、FDN)的完整模型DiffVox在MedleyDB上实现了最佳的声音匹配性能,MLDR损失最低,MSS低于仅含延迟或FDN的配置,验证了空间效果在准确匹配微动态和频谱方面的重要性。
- 移除模型中的近似会导致性能轻微下降,这是由于推理时使用无限IR与截断FIR之间的不匹配所致,但DiffVox仍优于无FDN的配置。
- 对参数logits的PCA分析显示,Internal数据集参数分布比MedleyDB更密集,Internal模型的前十个主成分可解释MedleyDB 65%的方差。
- 前两个主成分对应有意义的音频变换:第一个增强空间感和混响衰减,尤其在高频;第二个产生类似电话的带通效应,与McAdam的音色空间一致。
- 多变量正态性检验表明参数分布非正态,说明需要超越高斯假设的更复杂生成模型。
- 该模型成功捕捉了专业声乐效果参数,发布的数据集和代码为未来自动混音和神经音频效果研究提供了支持。
作者使用表格比较了不同音频处理配置在Internal和MedleyDB两个数据集上的声音匹配性能。结果表明,DiffVox模型在微动态匹配方面表现最佳,以MLDR损失衡量,同时相比仅使用延迟或FDN的配置,保持更低的频谱失配分数(MSS),表明其整体声音匹配能力更优。
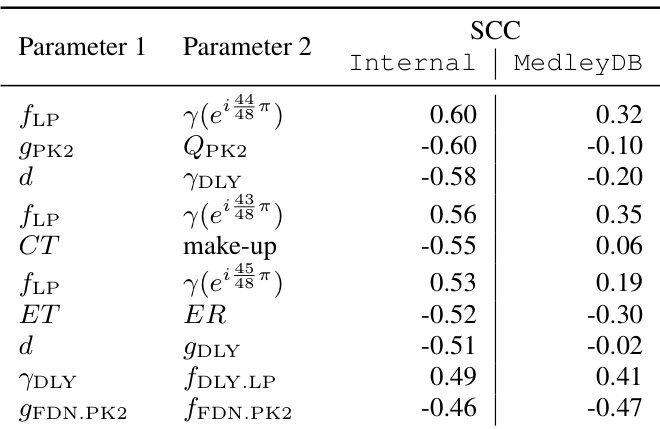
作者使用可微分模型分析声乐效果处理,测试多种配置以评估声音匹配性能。结果表明,完整模型DiffVox在频谱与动态保真度之间实现了最佳平衡,其微动态损失优于简单配置,同时保持低频谱失配。

结果表明,DiffVox在MLDR上实现了最佳匹配性能,且MSS低于仅含延迟或FDN的配置,表明其在捕捉音频的频谱与动态特性方面均具有效性。当移除近似时,性能略有下降,因推理时使用无限IR与截断FIR之间存在不匹配。