Command Palette
Search for a command to run...
在视频生成的下一帧预测模型中打包输入帧上下文
在视频生成的下一帧预测模型中打包输入帧上下文
Lvmin Zhang Maneesh Agrawala
摘要
我们提出一种名为 FramePack 的神经网络结构,用于训练视频生成中的下一帧(或下一帧片段)预测模型。FramePack 通过帧级重要性对输入帧上下文进行压缩,使得在固定上下文长度内能够编码更多帧,且重要性更高的帧可获得更长的上下文。帧的重要性可通过时间接近度、特征相似性或混合度量方式来衡量。该压缩方法支持推理阶段处理数千帧,并可在相对较大的批量大小下进行训练。此外,我们还提出了若干防漂移(drift prevention)策略,以缓解观测偏差(误差累积)问题,包括早期设定终点、调整采样顺序以及采用离散的历史表示方法。消融实验验证了这些防漂移方法在单向视频流与双向视频生成任务中的有效性。最后,我们展示了现有视频扩散模型可通过 FramePack 进行微调,并分析了不同压缩调度策略之间的差异。
一句话总结
斯坦福大学与麻省理工学院的作者提出 FramePack,一种利用帧级重要性加权进行视频上下文压缩的神经架构,可在固定 Transformer 上下文长度下实现数千帧的高效训练与推理;通过动态优先处理关键帧并引入离散历史表示等防漂移技术,显著提升了长时视频生成性能,尤其在双向与流式场景中表现优异。
主要贡献
- FramePack 提出一种新颖的帧压缩机制,根据时间接近度、特征相似性或混合度量对输入帧进行优先排序,能够在固定 Transformer 上下文长度内高效编码数千帧,同时保留关键的时间依赖关系。
- 该方法通过早期建立端点、调整采样顺序和离散历史表示等防漂移技术,有效缓解误差累积与观测偏差,降低训练与推理过程中的漂移问题。
- FramePack 能够高效微调现有视频扩散模型(如 HunyuanVideo、Wan),提升可扩展性,在消费级硬件上支持长视频生成,并在单向与双向设置下的消融实验中均表现出色。
引言
下一帧预测类视频扩散模型面临遗忘与漂移之间的关键权衡:强记忆机制有助于维持时间一致性,但会加剧误差传播;而减少误差累积的方法则削弱了时间依赖性,导致遗忘加剧。先前方法在可扩展性方面表现不佳,主要受限于 Transformer 中二次方复杂度的注意力机制以及对冗余时间数据处理效率低下。作者提出 FramePack,一种通过基于时间接近度与特征相似性的度量对输入帧进行压缩的记忆结构,实现固定长度上下文处理,从而支持高效长视频生成。为应对漂移问题,作者提出反漂移采样策略,通过双向上下文规划打破因果链,并设计反漂移训练方法,将帧历史离散化以对齐训练与推理过程。这些技术使得即使在消费级硬件上,也能实现数千帧的稳定、高质量视频生成,并可应用于 HunyuanVideo、Wan 等现有模型的微调。
方法
作者采用一种名为 FramePack 的神经网络架构,以解决在受限上下文长度下训练下一帧预测视频生成模型的挑战。核心框架通过为每帧分配重要性权重,实现输入帧上下文的压缩,从而在固定上下文长度内编码大量帧。该方法通过基于预测目标相关性的渐进式压缩实现,重要性更高的帧获得更长的上下文表示。整体框架基于潜变量表示,符合现代视频生成模型的通用范式,且适用于基于扩散的架构(如 Diffusion Transformers, DiTs)。模型在 T 个输入帧的基础上预测 S 个未知帧,其中 T 通常远大于 S。主要目标是应对原始 DiT 模型中随总帧数 T+S 线性增长的上下文长度爆炸问题。
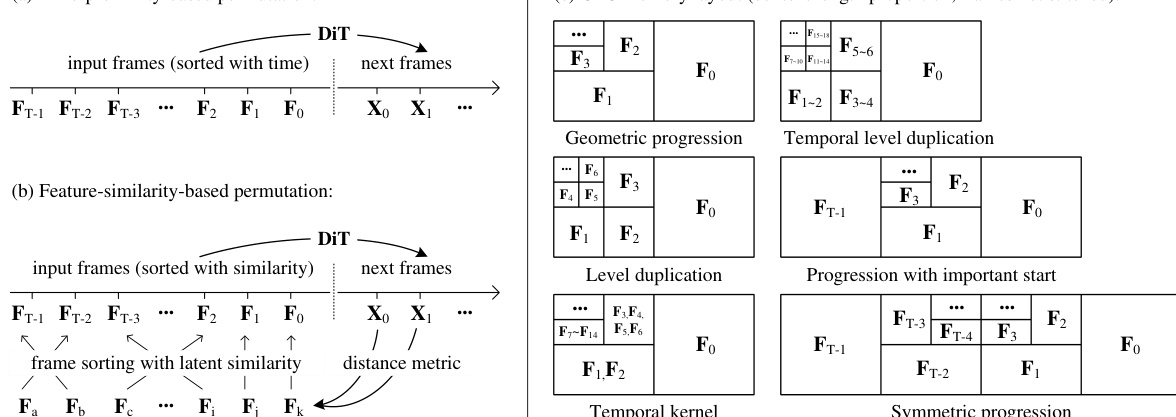
如图所示,该框架支持多种打包策略。第一种为基于时间接近度的打包方法,按输入帧与预测目标的时间距离排序,最近帧最为重要。每帧 Fi 被赋予一个上下文长度 ϕ(Fi),由几何级数定义为 ϕ(Fi)=Lf/λi,其中 Lf 为每帧的上下文长度,λ>1 为压缩参数。该方法使总上下文长度随 T 增加而收敛至有界值,从而实现压缩瓶颈对输入帧数量的不变性。压缩通过调整 Transformer 输入层的 patchify 核大小实现,不同核大小对应不同压缩率。作者讨论了多种核结构,包括几何级数、时间层级重复、层级重复和对称级数,以实现灵活高效的压缩。为支持高效计算,作者主要采用 λ=2,并指出通过在 2 的幂次序列中复制或删除特定项,可实现任意压缩率。框架还为不同压缩率使用独立的 patchify 参数,并通过插值预训练投影权重初始化。针对可能低于最小单位尺寸的尾帧,考虑三种处理方式:删除、逐步增加上下文长度或全局平均池化。
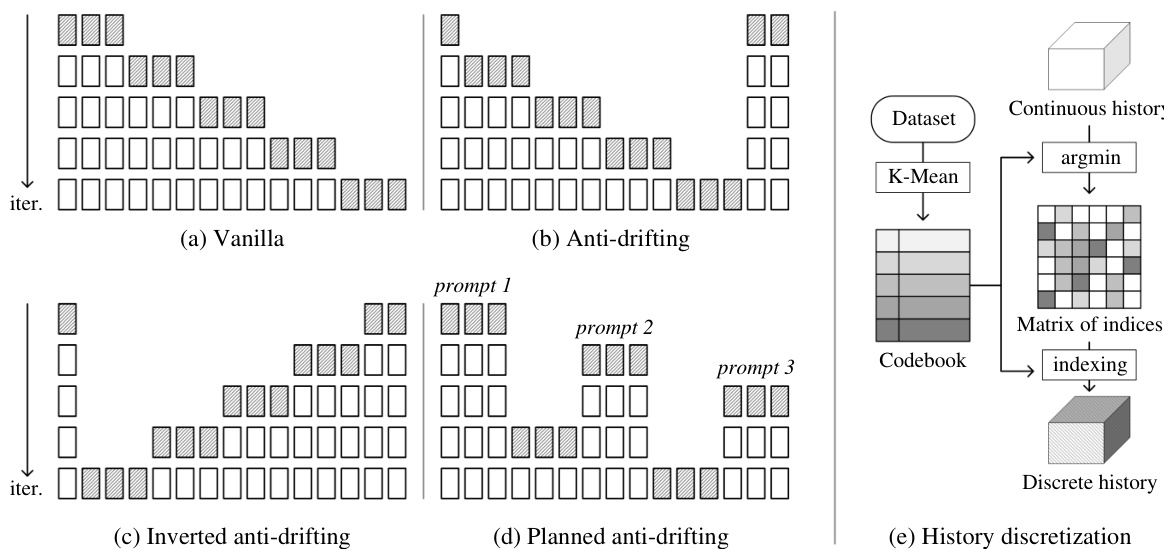
作者还提出一种基于特征相似性的打包方法,根据输入帧与估计下一帧段的相似性进行排序。该方法使用余弦相似度度量 simcos(Fi,X^),衡量每帧历史与预测帧段之间的相似性。该方法可与平滑的时间接近度建模结合,形成混合度量 simhybrid(Fi,X^),在特征相似性与时间距离之间取得平衡。该混合方法特别适用于需要返回先前视角的数据集,如视频游戏或电影生成。框架还包含多种防漂移方法,以应对观测偏差与误差累积。一种方法是规划端点:首次迭代同时生成视频的起始与结束部分,后续迭代填充中间空白。该双向策略比严格因果系统更具抗漂移能力。另一种方法为反向采样,适用于图像到视频生成场景,其中首帧为用户输入,末帧为生成端点。该方法确保所有生成均朝向逼近高质量用户输入。可通过不同提示规划多个端点,以支持更动态的运动与复杂叙事。最后,作者引入历史离散化,使用 K-Means 聚类生成的码本将连续潜变量历史转换为离散整数标记。这缩小了训练与推理分布之间的模式差距,缓解漂移问题。离散历史以索引矩阵形式表示,并在训练中使用。
实验
- 反向防漂移采样在 7 项指标中的 4 项表现最佳,且在所有漂移指标上均表现出色,证明其在保持高质量的同时显著缓解视频漂移。
- 原始采样结合历史离散化在人类偏好评分(ELO)上表现具有竞争力,且动态范围更大,表明在记忆保留与漂移抑制之间实现了良好平衡。
- DiffusionForcing 消融实验表明,更高的测试时噪声水平(σ_test)会降低对历史的依赖,缓解漂移但增加遗忘;最优权衡出现在 σ_test = 0.1。
- 历史引导增强了记忆能力,但加剧了漂移,因误差累积加速,验证了遗忘与漂移之间的固有权衡。
- 在 480p 分辨率下,FramePack 在单个 8xA100-80G 节点上支持最大批量大小达 64,实现实验室规模的高效训练。
- 消融研究确认,整体架构设计主导性能差异,同一采样方法内部的微小变化影响较小。
作者通过全面的消融研究评估了不同 FramePack 配置的影响,重点关注其对视频质量、漂移和人类偏好带来的影响。结果表明,反向防漂移采样在所有漂移指标中表现最佳,并在人类评估中得分最高;而原始采样结合离散历史则在漂移抑制与动态范围之间提供了良好平衡。
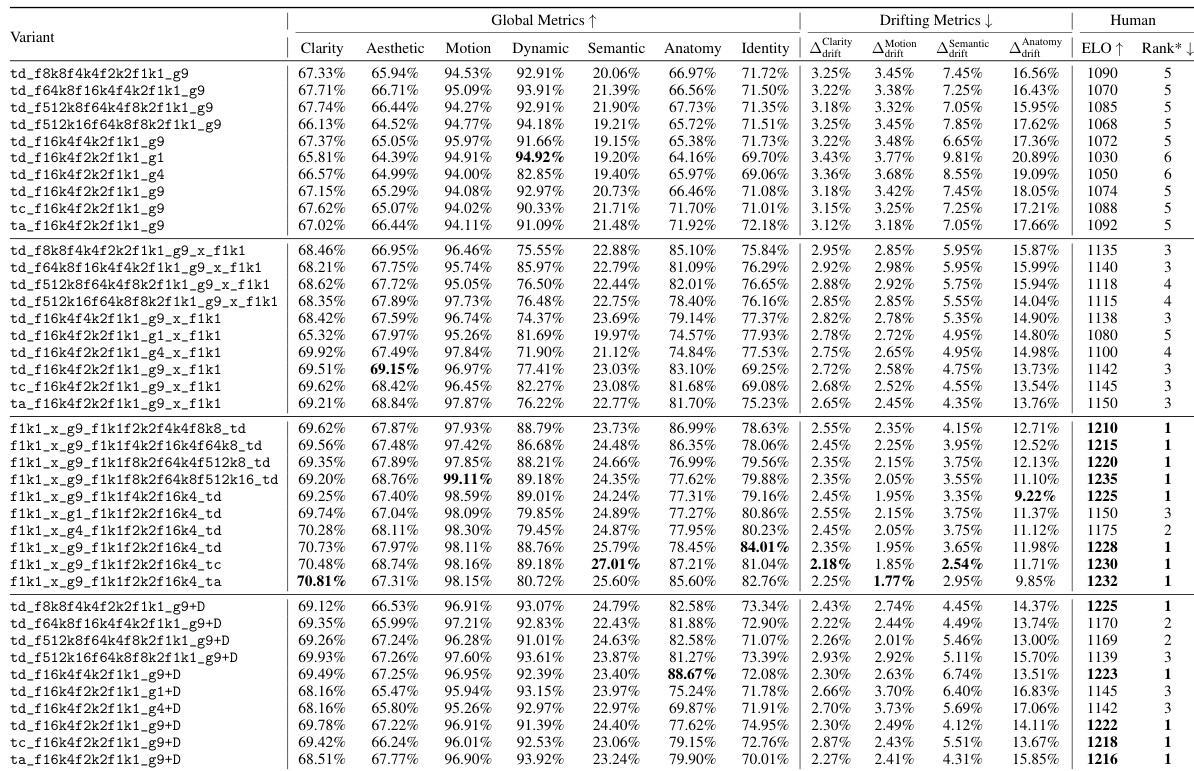
作者通过一系列消融研究评估了不同视频生成方法的性能,重点关注全局质量指标、漂移指标与人类评估结果。结果表明,反向防漂移采样在所有漂移指标中表现最佳,且在人类偏好评估中排名最高;而原始采样结合离散历史在低漂移与高动态范围之间实现了出色平衡。
