Command Palette
Search for a command to run...
从少到多的泛化:通过上下文生成实现更强的可控性
从少到多的泛化:通过上下文生成实现更强的可控性
Shaojin Wu Mengqi Huang Wenxu Wu Yufeng Cheng Fei Ding Qian He
摘要
尽管基于主体的图像生成因其广泛的应用前景在图像生成领域得到了深入研究,但在数据可扩展性与主体可扩展性方面仍面临挑战。针对第一个挑战,从构建单主体数据集向多主体数据集迁移并实现规模化,尤为困难。针对第二个挑战,当前多数方法聚焦于单主体生成,难以有效应用于多主体场景。为此,本文提出一种高度一致的数据合成流程,以应对上述难题。该流程充分利用扩散变换器(diffusion transformers)固有的上下文内生成能力,生成具有高一致性的多主体配对数据。此外,本文提出UNO模型,其包含渐进式跨模态对齐机制与通用旋转位置编码(universal rotary position embedding),是一种基于文本到图像模型迭代训练的多图像条件驱动的主体到图像生成模型。大量实验表明,所提方法在单主体与多主体驱动生成任务中均能实现高度一致性,同时保持良好的可控性。
一句话总结
字节跳动的作者提出 UNO,一种基于渐进式跨模态对齐和通用旋转位置编码的多图像条件主体到图像模型,通过利用基于扩散 Transformer 的数据合成管道,克服了先前方法在可扩展性和可扩展性方面的局限,实现了在单主体和多主体场景下高一致性、可控制的生成。
主要贡献
- 现有的主体驱动图像生成方法在数据可扩展性和主体可扩展性方面面临显著限制,因为现实世界的数据集难以捕捉多样化的主体变化,且大多数模型受限于单主体场景。
- 作者提出 UNO,一种通过从文本到图像基础模型迭代训练构建的多图像条件主体到图像模型,通过引入渐进式跨模态对齐和通用旋转位置编码,缓解多主体控制中的属性混淆问题。
- 一种新颖的数据合成管道利用扩散 Transformer 的上下文生成能力,生成高分辨率、高一致性的多主体配对数据,使模型在 DreamBench 和多主体基准测试中均达到最先进性能,兼具主体保真度和文本可控性。
引言
作者针对可扩展、可控制的图像生成挑战,要求模型在遵循多样化文本提示的同时忠实再现特定视觉主体。这对电影制作和设计等现实应用至关重要,其中主体一致性和提示保真度均不可或缺。先前方法面临根本性的数据瓶颈:现实世界中的配对数据稀缺,尤其是在多主体场景中;而合成数据通常存在分辨率低、质量差或领域覆盖有限的问题。现有模型通常在固定且有限的数据上训练,导致主体相似性与文本可控性之间存在权衡,且难以扩展至新主体。
为克服这一问题,作者提出一种模型-数据协同进化范式,即能力较弱的模型生成越来越高质量的合成数据以训练更先进的模型。这实现了数据丰富性和模型可控性的持续提升。技术上,他们提出 UNO,一种基于扩散 Transformer 的多图像条件主体到图像模型,从文本到图像基础模型迭代训练而来。UNO 具备渐进式跨模态对齐和通用旋转位置编码(UnoPE),以缓解主体控制扩展时的属性混淆。关键创新在于一种系统性的合成数据管道,利用上下文生成生成高分辨率、高一致性的多主体配对数据,通过多阶段过滤实现。
主要贡献是一个可扩展、自我改进的框架,通过实现从少到多的泛化打破数据瓶颈。UNO 在单主体和多主体生成基准测试中均达到最先进性能,展现出强大的主体保真度和文本可控性,且不牺牲可扩展性。
数据集
- 数据集通过多阶段管道合成,生成高分辨率、主体一致的图像对,解决了主体驱动图像生成中高质量、多样化数据稀缺的问题。
- 数据集由两个主要子集组成:单主体上下文数据和多主体上下文数据,均通过基于 DiT 的文本到图像(T2I)模型生成。
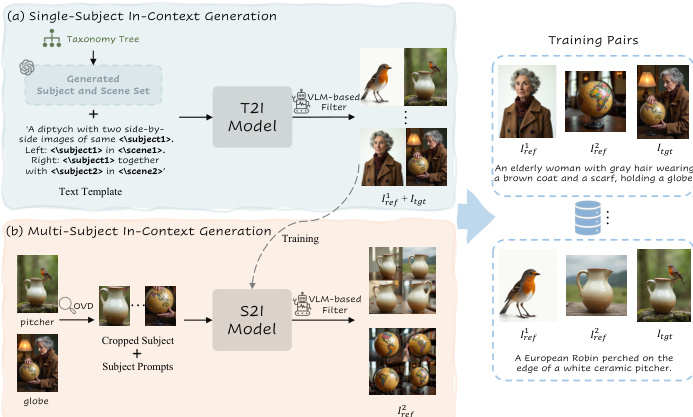
- 单主体数据源自基于 Object365 的 365 个基础类构建的分类树,通过大型语言模型(LLM)扩展生成多样化的主体实例(如年龄、职业、着装)和场景描述,生成数百万个用于 T2I 生成的文本提示。
- 生成的图像对经过两步过滤管道处理:首先,使用 DINOv2 计算参考图像与目标图像之间的相似性,剔除一致性低的配对;其次,使用视觉-语言模型(VLM)评估外观、细节和属性,生成最终一致性评分,用于保留高质量样本。
- 多主体数据通过先在单主体数据上训练主体到图像(S2I)模型,再利用其生成新主体的参考图像。开放词汇检测器(OVD)识别目标图像中的额外主体,但不直接使用裁剪版本,而是通过 S2I 模型生成新的、上下文一致的参考图像,避免复制粘贴伪影。
- 最终的多主体数据包含三元组图像:Iref1、Iref2 和 Itgt,其中两个参考图像均保持主体一致性,目标图像包含多个主体的连贯场景。
- 数据集支持三种高分辨率格式:1024×1024、1024×768 和 768×1024,支持多样化的训练场景。
- 模型训练采用渐进式框架:第一阶段在单主体数据上微调预训练的 T2I 模型,构建 S2I 模型;第二阶段在多主体数据上继续训练,提升多主体一致性。
- 引入通用旋转位置编码(UnoPE),以减少主体控制扩展过程中的属性混淆。
- 最终数据集用于混合训练划分,单主体与多主体数据比例可调,基于 VLM 的过滤确保仅保留高质量配对,直接提升下游任务在 DINO 和 CLIP-I 等指标上的表现。
方法
作者采用扩散 Transformer(DiT)架构作为其模型-数据协同进化范式的基石,旨在实现具有增强可控性的主体到图像(S2I)生成。核心框架始于一个文本到图像(T2I)DiT 模型,该模型在潜在块上使用全 Transformer 层,与传统的 U-Net 主干结构不同。该模型包含多模态注意力机制,其中来自文本和图像输入的位置编码标记被投影为查询、键和值表示,使跨模态交互在统一空间内实现。DiT 模型的输入由编码后的文本标记 c 与噪声潜在 zt=E(Itgt) 拼接而成,其中 E(⋅) 为 VAE 编码器。
为将此 T2I 模型适配于 S2I 生成,作者引入一种两阶段迭代训练框架,称为 UNO,逐步对齐模型的跨模态能力。训练过程从单图像条件开始,模型在单个参考图像 Iref1 和文本提示条件下进行训练。该阶段的输入 z1 由文本标记 c、噪声潜在 zt 和编码后的参考图像标记 E(Iref1) 拼接而成。此初始阶段建立主体一致生成的基线。随后,模型进入第二阶段训练,使用多个参考图像 Iref=[Iref1,Iref2,…,IrefN],输入 z2 由文本标记、噪声潜在和所有参考图像的编码标记拼接而成。从单图像到多图像条件的演进使模型能够学习更复杂的上下文关系。
UNO 框架的关键组件是通用旋转位置编码(UnoPE),用于解决将多个参考图像整合到 DiT 位置编码方案中的挑战。原始 DiT 架构根据潜在网格中的空间位置为图像标记分配位置索引 (i,j),而文本标记则分配固定索引 (0,0)。为在引入参考图像标记时保持原始模型的隐式位置对应关系,UnoPE 采用相同格式,但将位置索引从噪声图像标记的最大高度和宽度开始分配。对于参考图像 zrefN,调整后的位置索引定义为 (i′,j′)=(i+w(N−1),j+h(N−1)),其中 w(N−1) 和 h(N−1) 为前一个参考图像潜在表示的宽度和高度。这确保参考图像位于位置空间中一个独立且不重叠的区域,防止模型过度依赖参考图像的空间结构,转而关注从文本提示中提取的语义信息。
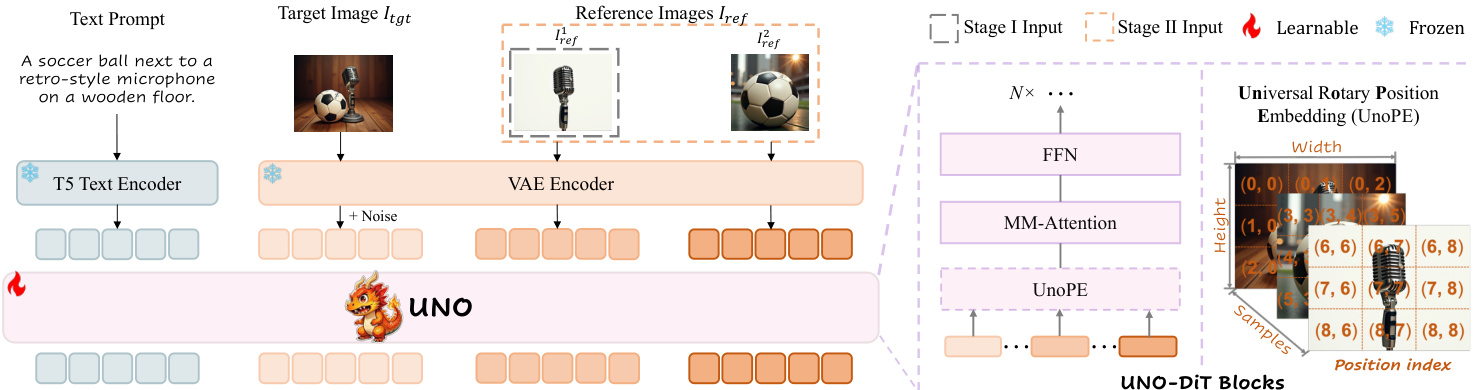
UNO-DiT 模块构成模型的核心,用于处理这些多模态输入。该架构包含前馈网络(FFN)和多模态注意力(MM-Attention)层,UnoPE 模块为参考图像标记提供必要的位置嵌入。模型以迭代方式训练:在单图像数据上的初始训练建立主体到图像能力,随后在多图像数据上的训练使模型能够处理更复杂的多主体生成任务。这种渐进式训练策略结合新颖的 UnoPE,使模型能够解锁基础 T2I 模型的上下文生成能力,形成高度可控且主体一致的 S2I 生成系统。
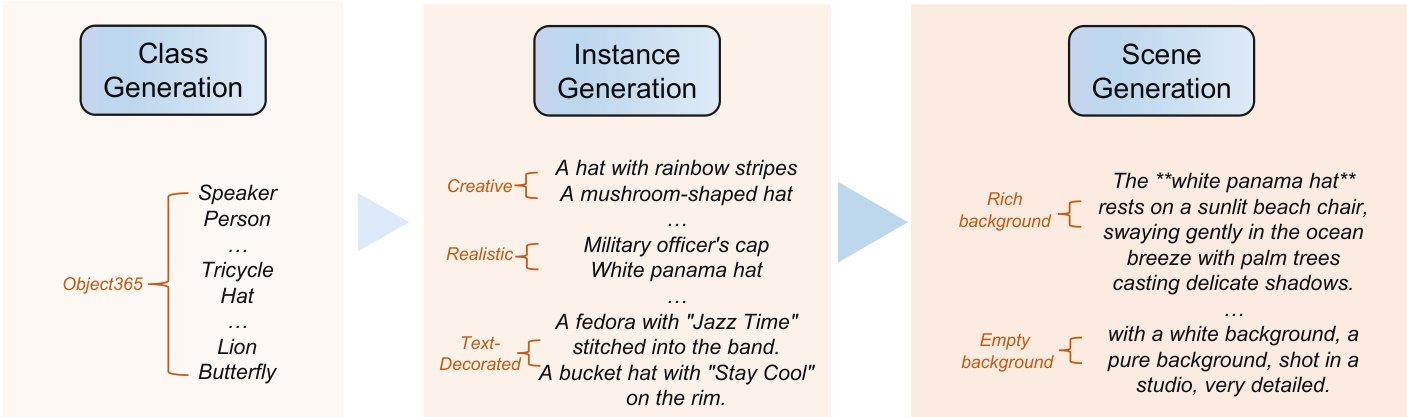
用于训练的合成数据通过一个复杂的上下文数据整理框架生成。该管道首先构建分类树以生成多样化的主体实例和场景。随后使用双联文本模板引导最先进的 T2I 模型(如 FLUX.1)生成主体一致的图像对数据。生成的数据通过 DINOv2(基于特征的相似性)和结合思维链(CoT)推理的视觉-语言模型(VLM)进行质量与一致性过滤,提供对主体一致性的细粒度评估。此整理后的数据(包含单主体和多主体配对)用于训练 UNO 模型,形成一个闭环系统,使模型与数据共同演化。
实验
- 使用 UNO(一种基于 DiT 架构的免调优方法)在 8 块 A100 GPU 上以 LoRA(秩 512)进行训练,开展单主体和多主体驱动的图像生成实验。
- 验证渐进式跨模态对齐:先在单主体数据(5,000 步)上训练,再在多主体数据(5,000 步)上训练,显著提升主体一致性和文本保真度。
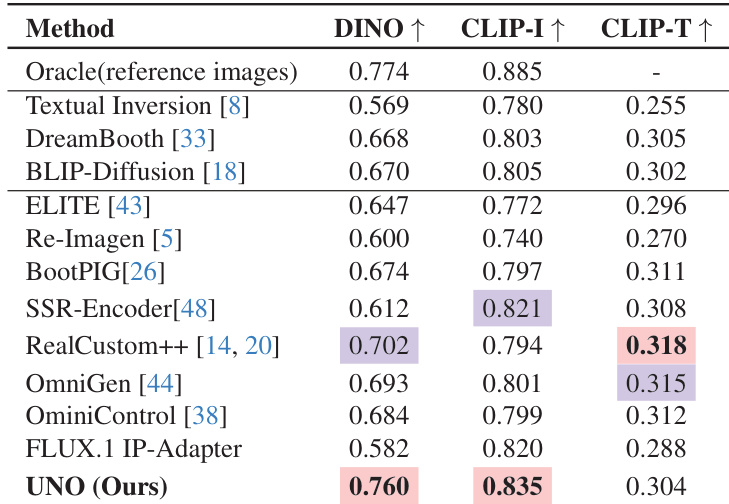
- 在 DreamBench 上,UNO 在零样本单主体生成中达到最先进结果,CLIP-I 得分为 0.835,DINO 得分为 0.760,超越现有免调优和调优方法。
- 在多主体生成中,UNO 达到最高 DINO 和 CLIP-I 得分,CLIP-T 得分具有竞争力,展现出强大的主体一致性和对文本编辑的遵循能力。
- 用户研究(n=30)确认 UNO 在五个维度上优于基线:主体相似性、文本保真度(主体与背景)、构图质量及视觉吸引力。
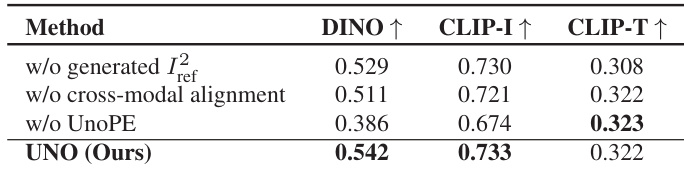
- 消融实验表明,上下文数据生成、渐进式跨模态对齐和所提出的 UnoPE 位置编码对性能至关重要;移除任一组件均导致主体相似性和文本对齐显著下降。
- LoRA 秩分析表明,性能在秩 128 以上趋于饱和,选择秩 512 以在性能与效率间取得最佳平衡。
- 在虚拟试穿、身份保留、Logo 设计和风格化生成等多样化应用中展现出强泛化能力,尽管这些领域训练数据有限。
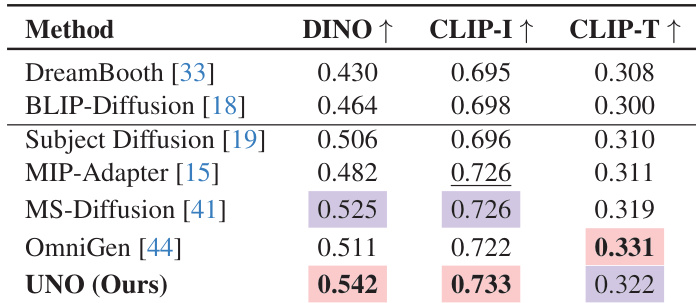
结果表明,UNO 在所有对比方法中取得最高 DINO 和 CLIP-I 得分,分别为 0.542 和 0.733,表明主体相似性更优。其 CLIP-T 得分为 0.322,具有竞争力,表明在单主体驱动生成中具备强文本保真度。
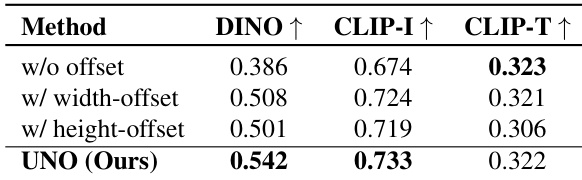
作者评估了不同位置索引偏移方法对模型性能的影响,结果表明所提出的 UNO 方法在 DINO 和 CLIP-I 得分上均达到最高,表明主体相似性提升,同时保持了具有竞争力的 CLIP-T 得分以保障文本保真度。引入高度偏移和宽度偏移组件带来逐步提升,UNO 超越了单独的偏移变体及无偏移基线。
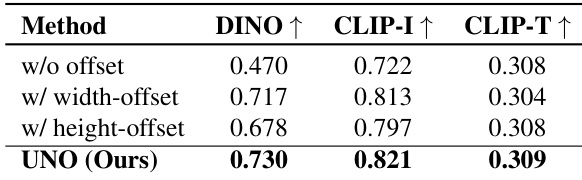
结果表明,所提出的 UnoPE 方法(包含高度偏移)在 DINO 和 CLIP-I 得分上分别达到最高值 0.730 和 0.821,优于无偏移或仅含宽度偏移的变体。模型同时保持了 0.309 的竞争力 CLIP-T 得分,表明在提升主体相似性的同时仍具备强文本保真度。
作者使用表 4 评估渐进式跨模态对齐对模型性能的影响。结果表明,移除跨模态对齐导致 DINO 和 CLIP-I 得分显著下降,表明主体相似性降低,而 CLIP-T 得分相对稳定。采用渐进式对齐的模型取得最高 DINO 和 CLIP-I 得分,证明其在提升主体一致性方面的有效性。
结果表明,UNO 在单主体驱动生成中取得最高 DINO 和 CLIP-I 得分,分别为 0.760 和 0.835,超越所有对比的调优与免调优方法。模型同时取得 0.304 的竞争力 CLIP-T 得分,表明在主体相似性卓越的同时具备强文本保真度。