Command Palette
Search for a command to run...
OpenCodeReasoning:面向竞赛编程的数据蒸馏技术推进
OpenCodeReasoning:面向竞赛编程的数据蒸馏技术推进
Wasi Uddin Ahmad Sean Narenthiran Somshubra Majumdar Aleksander Ficek Siddhartha Jain Jocelyn Huang Vahid Noroozi Boris Ginsburg
摘要
自基于推理的大型语言模型问世以来,许多研究已成功通过知识蒸馏将推理能力迁移到学生模型中,显著缩小了具备推理能力的模型与标准大语言模型在编程任务上的性能差距。然而,当前大多数关于推理模型蒸馏的进展仍受限于专有数据集,或缺乏对数据构建、筛选及后续训练过程的详细说明。为解决这一问题,我们构建了一个高质量的监督微调(Supervised Fine-Tuning, SFT)数据集,并基于该数据集在不同规模的模型上实现了当前最优的编程能力表现。我们所蒸馏的模型仅通过SFT训练,便在LiveCodeBench上达到61.8%的得分,在CodeContests上达到24.6%的得分,超越了采用强化学习训练的同类模型。随后,我们对构建该数据集所依赖的数据来源、代码执行过滤机制的影响,以及指令与解法多样性的重要性进行了深入分析。研究发现,代码执行过滤反而对基准测试的准确率产生了负面影响,因此我们决定优先保障指令多样性,而非过度强调解法的正确性。此外,我们还分析了这些模型在推理过程中所采用的token效率与推理模式。为促进社区发展,我们将公开发布所构建的数据集及蒸馏后的模型,以推动该领域的透明化与进一步研究。
一句话总结
NVIDIA 的研究者提出了一种新的监督微调代码数据集,通过执行过滤实现指令多样性而非解法正确性,使蒸馏模型在 Live-CodeBench(61.8%)和 CodeContests(24.6%)上达到最先进水平,无需强化学习,为代码生成中的高效、透明模型训练提供了启示。
主要贡献
-
本文解决了将推理能力蒸馏至小型语言模型时缺乏透明、开放获取数据集的问题,提出了 OPENCODEREASONING——一个大规模合成数据集,包含 736,712 个 Python 代码样本,覆盖 28,904 道编程竞赛题目,支持卓越的监督微调(SFT)性能,且不依赖专有数据或强化学习。
-
仅使用该数据集进行 SFT 训练,作者在多个代码基准测试中取得最先进结果,包括 Live-CodeBench 上的 61.8% pass@1 和 CodeContests 上的 24.6%,优于所有开源权重的 SFT 模型以及多个 SFT+RL 方案,证明高质量 SFT 数据可弥合与复杂训练范式之间的性能差距。
-
消融实验表明,数据整理过程中对代码执行结果的过滤会损害基准测试表现,因此作者优先考虑指令多样性而非解法正确性,同时分析了 token 效率与推理模式,为未来数据集设计与模型蒸馏提供了可操作的洞见。
引言
研究者利用合成数据生成与监督微调技术,提升小型语言模型在编程竞赛任务中的表现,应对高质量、可扩展训练数据日益增长的需求。以往工作严重依赖专有数据集或涉及强化学习的复杂训练流程,限制了可复现性与可访问性。尽管部分开源权重模型通过纯 SFT 训练取得良好效果,但通常仍落后于 SFT+RL 模型,原因在于其数据集规模较小或多样性不足。本文提出 OpenCodeReasoning,一个大规模开源数据集,包含 736,712 个基于 Python 的推理示例,源自 28,904 道编程竞赛问题,使纯 SFT 模型超越以往开源模型,甚至部分专有模型。分析表明,指令多样性比解法正确性更为关键,因为代码执行过滤可能损害基准性能,且大规模合成数据的有效扩展可显著缩小与 RL 训练模型的差距。
数据集
- OPENCODEREASONING 数据集包含 736,712 个带有推理轨迹的 Python 代码解决方案,由 DeepSeek-R1 生成,覆盖 28,904 个独特的编程竞赛问题。
- 数据来源包括 TACO、APPS、CodeContests 和 CodeForces,通过 OpenR1 项目获取,采用精确匹配去重策略消除重叠,形成多样且无冗余的问题集合。
- 通过余弦相似度(阈值 0.7)与人工介入验证(使用 Llama-3.3-70B-Instruct 和 Qwen2.5-32B-Instruct)进行了严格的基准污染检查,确认与评估基准无语义重叠。
- 解决方案由具备推理能力的大语言模型生成,随后进行后处理:推理轨迹在 和 标签内被验证并提取,代码块使用
python orcpp 分隔符隔离。 - 过滤掉推理轨迹中包含代码的响应,确保推理与代码的清晰分离,该步骤仅移除极少量样本。
- 使用 Tree Sitter 验证代码块的语法正确性,仅保留格式正确的代码。
- 最终数据集包含 736,712 个 Python 样本和 355,792 个 C++ 样本,各来源的详细 token 统计信息见图 2。
- 该数据集用于微调 Qwen2.5 模型(7B、14B、32B),混合来自不同来源的解决方案,利用全部 736,712 个样本,在 LiveCodeBench 和 CodeContests 上实现最先进性能。
- 训练采用推理与代码的均衡混合,代码不嵌入推理部分,处理流程确保格式一致且代码可执行,质量高。
方法
研究者利用 DeepSeek-R1 模型为每个问题生成多个解决方案,主要为 Python,同时为 IOI 基准的初步实验生成额外的 C++ 解决方案。生成过程采用 Nucleus Sampling,温度为 0.6,top-p 为 0.95,确保输出多样且聚焦。为强制结构化推理,模型在推理时被显式提示包含推理轨迹,通过注入特定标签实现。该方法基于 SGLang 实现,支持最大输出序列长度为 16k token 的高效推理。

如图所示,初始分割提示为解决问题提供思维链,并指导模型识别并分割推理为不同模式,如问题重述、新想法生成、自我评估、验证、回溯和子目标生成。输出格式要求模型为每个片段标注模式名称,并关联对应文本内容。

最终分割提示通过聚焦思维链中未标注的片段(由 <unannotated> 和 </unannotated> 标签界定)来优化任务。模型需识别每个片段所用的推理模式,并生成结构化输出,包含内容、模式分配理由及模式名称。这种两阶段提示策略使模型能够系统性地分解并标注复杂的推理过程。
实验
- 从 25k 到 736k 样本分阶段扩展数据量,显示数据规模与代码基准性能之间存在强正相关性,尤其在引入 CodeContests 中的难题时提升最为显著。
- 在 LiveCodeBench 和 CodeContests 上,OCR-Qwen-32B-Instruct 分别达到 61.8 和 24.6 的 pass@1,超越 QwQ-32B,接近 DeepSeek-R1 的性能(65.6 和 26.2),凸显大规模数据与蒸馏的有效性。
- 消融实验表明,使用错误代码解决方案(通常来自更难问题)进行微调,其准确率高于仅使用正确解法,说明具有挑战性、易出错的样本能提供有价值的推理信号。
- 在训练中加入 C++ 解法可提升 C++ 特定 IOI 基准的表现,但对 Python 导向基准无益,表明语言特定数据对最优结果至关重要。
- 分析显示,OCR-32B 模型生成的推理轨迹比 QwQ-32B 短 20–30%,同时保持相当的准确率,且在难题上更长的推理并未提升性能,反而常导致推理循环或准确率下降。
- 正确解法表现出更高的自我评估与子目标生成能力,以及更丰富的推理模式多样性,这些特征与正确性显著相关,表明其在有效解题中至关重要。
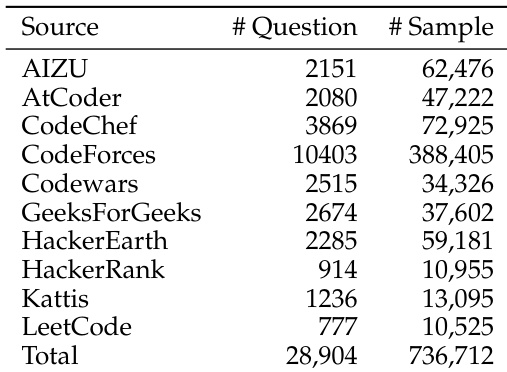
结果表明,随着问题难度从简单到中等再到困难,正确解法中回溯与自我评估模式显著增加,而错误解法在所有难度级别上均保持高水平的回溯。数据还显示,自我评估与子目标生成在正确解法中更为普遍,表明这些模式有助于提升解法准确性。
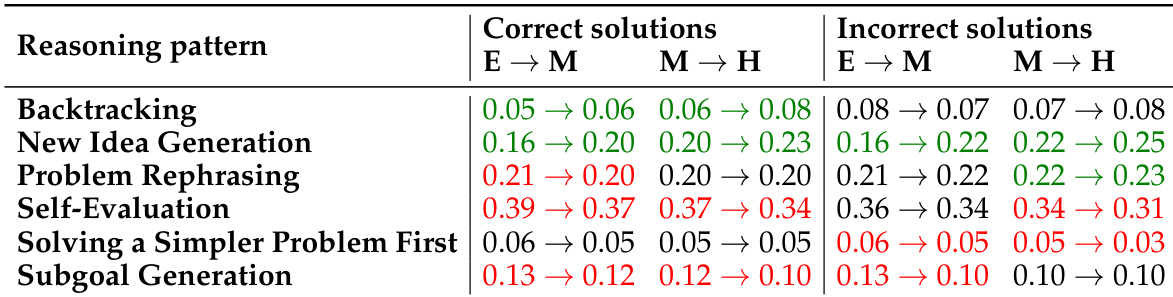
研究者使用 OpenCodeReasoning 数据集微调 Qwen2.5 模型,在 LiveCodeBench 上实现最先进性能。结果显示,其 OCR-Qwen-32B-Instruct 模型优于所有开源权重模型,包括 QwQ-32B 和 OlympicCoder-32B,并与专有模型 DeepSeek-R1 相差甚微。
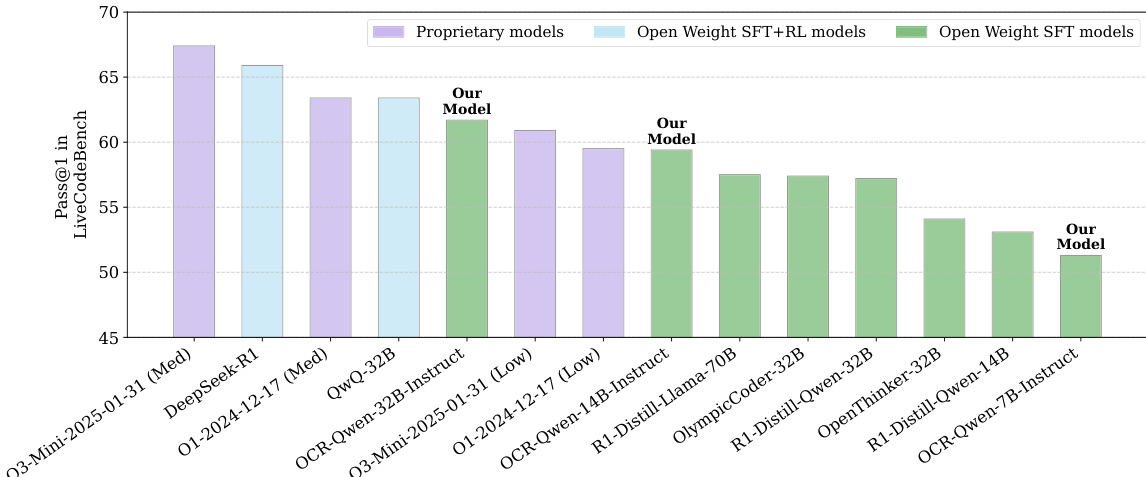
研究者使用 OpenCodeReasoning 数据集(整合来自 CodeForces、CodeChef 和 LeetCode 等多个来源的数据)训练并评估代码生成模型。结果显示,该数据集包含 736,712 个样本,覆盖 28,904 个唯一问题,其中 CodeForces 贡献了最多样本与问题。
结果显示,对错误解法进行微调在 LiveCodeBench 和 CodeContests 上的表现优于仅使用正确解法,尽管错误解法来自更具挑战性的问题。这表明,即使大型模型生成的错误输出也能在蒸馏过程中产生积极影响,可能因其关联于需要更复杂推理的难题。

研究者通过在 Python 与 C++ 样本的混合数据集上微调 Qwen-2.5-14B-Instruct 和 Qwen-2.5-32B-Instruct 模型,评估了在训练数据中加入 C++ 解法的影响。结果显示,虽然 C++ 数据的加入未提升 Python 基准表现,但显著提高了 C++ 特定 IOI 基准的准确率,表明多语言数据可增强目标语言的性能。