Command Palette
Search for a command to run...
Task Tokens:一种适配行为基础模型的灵活方法
Task Tokens:一种适配行为基础模型的灵活方法
Ron Vainshtein Zohar Rimon Shie Mannor Chen Tessler
摘要
机器人控制领域的模仿学习(imitation learning)近期取得了显著进展,催生了基于 Transformer 的行为基础模型(Behavior Foundation Models, BFMs)。这些模型能够为人形智能体(humanoid agents)提供多模态且类人的控制能力。当以高层级目标或 prompt 为条件时,这些模型能够生成相应的解决方案;例如,在以机器人骨盆位置作为条件时,模型可以生成向特定坐标行走的动作。尽管 BFMs 在实现鲁棒行为的 zero-shot 生成方面表现出色,但在处理特定任务时,往往需要进行精细的 prompt engineering,这可能会导致结果并非最优。在本研究中,我们提出了“Task Tokens”——一种在保留 BFM 灵活性的同时,使其能够有效地适配特定任务的方法。我们的方法能够自然地集成到 BFMs 的 Transformer 架构中。Task Tokens 通过训练一个任务特定的编码器(tokenizer)来实现,而原始的 BFM 则保持不变。与标准基准方法相比,我们的方法将每个任务的可训练参数减少了高达 125 倍,且收敛速度提升了多达 6 倍。此外,通过保持原始 BFM 不变,Task Tokens 能够利用预先存在的编码器,从而允许引入用户定义的先验知识(priors),在奖励设计(reward design)与 prompt engineering 之间取得平衡。我们在包括分布外(out-of-distribution)场景在内的多种任务中证明了 Task Tokens 的有效性,并展示了其与其他 prompting 模态的兼容性。
一句话总结
通过在保持原始 transformer 架构冻结的同时训练特定任务的编码器,所提出的 Task Tokens 方法能够将行为基础模型适配到特定的机器人控制任务中,其可训练参数比标准基准线减少高达 125 倍,收敛速度快 6 倍。
核心贡献
- 本文引入了 Task Tokens,这是一种旨在通过训练特定任务的编码器来适配行为基础模型 (BFMs) 的方法,同时保持原始 BFM 参数冻结。
- 该方法直接集成到现有的 transformer 架构中,允许使用预先存在的编码器,并结合用户定义的先验知识,以平衡奖励设计与 prompt engineering。
- 实验结果表明,Task Tokens 在各种任务和分布外场景中,将每个任务的可训练参数减少了高达 125 倍,并实现了比标准基准线快高达 6 倍的收敛速度。
引言
目标条件行为基础模型 (GC-BFMs) 通过将目标直接映射到动作,对于在机器人技术和动画中生成多样化、类人运动至关重要。虽然这些模型擅长复现常见动作,但在适配分布外约束或用户定义的专门任务时却面临困难。现有的解决方案(如 prompt engineering 或微调)通常效率低下,或者存在降低模型内存储的基础知识的风险。本文利用 Task Tokens 方法来弥补这一差距,提供了一种在保留底层基础模型自然行为的同时,纳入特定任务优化机制的方法。
方法
本文提出了一种名为 Task Tokens 的参数高效方法,旨在不微调底层基础模型的情况下,将目标条件行为基础模型 (GC-BFM)(具体为 MaskedMimic)适配到特定的下游任务。该方法在实现特定任务优化的同时,保留了 BFM 的零样本能力和通用行为先验。
核心架构依赖于 MaskedMimic 基于 transformer 的特性,即处理 token 序列。该方法集成了三个不同的输入源来引导模型。如框架图所示:

这些来源包括:Prior Tokens,允许用户定义行为先验(如文本提示或关节条件);State Tokens,使用预训练编码器表示当前环境状态 sti;以及 Task Tokens,由专门的 Task Encoder 生成。冻结的 GC-BFM 集成这些输入以产生任务优化的动作 ati。
Task Encoder 被设计为一个轻量级的通用模块,实现为带有 ReLU 激活函数的全连接多层感知机 (MLP)。它处理在 agent 自中心参考系中表示的任务目标观测 gti,并预测一个 Task Token τti∈R512。例如,在转向任务中,输入 gti 可能包括目标方向、朝向和期望速度。为了确保与 MaskedMimic 的预训练表示对齐,编码器还被提供了本体感受信息。生成的 Task Token 与 BFM 输入空间中的其他 token 拼接,创建一个 token "句子",其中特定任务信号充当引导模型走向目标行为的专门单词。
为了优化 Task Encoder,本文采用了近端策略优化 (PPO)。在训练过程中,BFM 根据组合后的 token 序列预测动作概率。PPO 目标函数是针对特定任务的奖励和 BFM 的动作概率进行计算的。至关重要的是,梯度通过冻结的 GC-BFM 流动,从而仅更新 Task Encoder 参数。这种设计防止了基础模型先验知识的退化,而这种退化在全量微调中可能会发生。
对于需要顺序执行的复杂任务,本文实现了多阶段提示。该机制使用有限状态机 (FSM) 在使用单个 Task Token 的同时,在不同的 prior tokens 之间进行切换。如下图所示,这允许 agent 根据与目标的几何距离,在不同的行为阶段之间进行转换,例如从移动阶段转换到打击阶段:
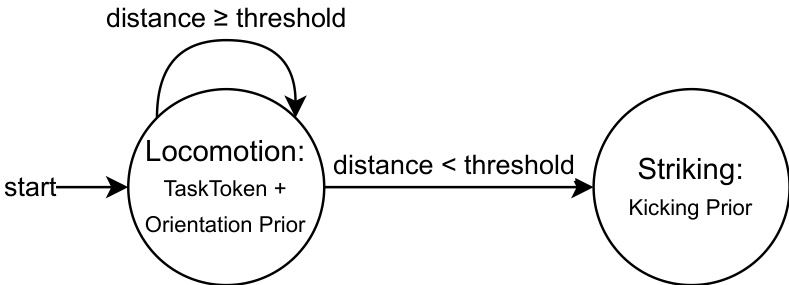
实验
研究人员在多种类人控制任务(包括伸手、转向和打击)中评估了 Task Tokens 方法,以评估其将行为基础模型适配到特定目标的能力。实验验证了这种混合方法在保持原始模型的鲁棒性和多模态提示能力的同时,实现了快速收敛和高成功率。来自人类研究和分布外测试的定性结果证实,该方法能够产生自然的、类人的运动,并能很好地泛化到变化的各种环境条件(如重力和摩擦力的变化)。
本文在五个不同的任务中比较了各种类人控制方法的成功率。结果显示,Task Tokens 在大多数环境中都实现了高性能,与已有的基准线相比展现出强大的竞争力。Task Tokens 在 Direction、Steering 和 Reach 任务中保持了高成功率。该方法在多个任务类别中的表现与 PPO 和 AMP 等先进基准线相当。虽然某些基准线在 Strike 和 Long Jump 任务中表现出更高的成功率,但 Task Tokens 在大多数评估场景中仍然有效。
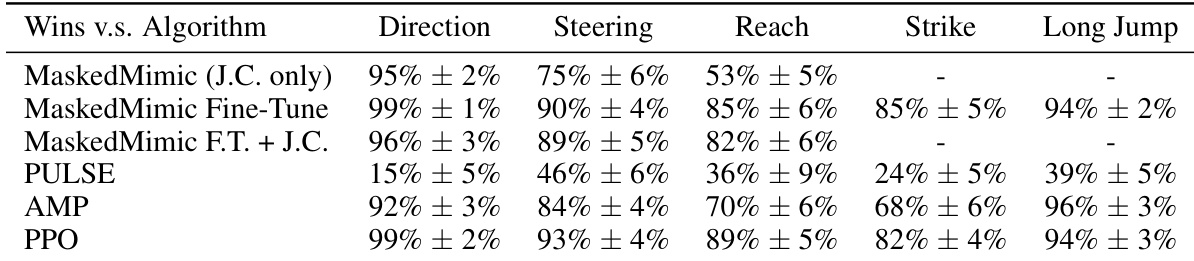
本文通过将 Task Tokens 的成功率与各种基准线进行比较,评估了其在多个类人控制任务中的表现。结果表明,Task Tokens 在大多数环境中实现了高成功率,有效地将基础模型适配到新任务。在大多数评估任务中,Task Tokens 的表现与微调方法相当或优于微调方法。与原始的零样本 MaskedMimic 方法相比,该方法在 Reach 和 Steering 等任务的成功率方面表现出显著提升。虽然微调在 Strike 任务中取得了很高的成功率,但 Task Tokens 在大多数其他场景中仍保持着强劲的表现。

本文在五个类人控制任务中将 Task Tokens 方法与几种基准线进行了对比。结果显示,Task Tokens 在大多数环境中实现了高成功率,展示了有效的任务适配能力,同时在面对专门方法时保持了竞争力的性能。与大多数基准线相比,Task Tokens 在 Reach、Direction 和 Steering 任务中取得了更高的成功率。该方法在 Long Jump 任务上表现非常出色,达到了最先进的分层方法的性能水平。虽然 MaskedMimic Fine-Tune 和 PULSE 等其他方法在 Strike 任务中表现强劲,但 Task Tokens 在整个任务集中依然具有高度竞争力。

本文进行了消融研究,以评估不同的 Task Encoder 架构如何影响转向任务的表现。结果表明,更大的 MLP 编码器以及加入当前姿态信息通常有助于提高成功率。使用更大的 MLP 编码器往往能提高转向任务的成功率。在编码器中加入当前姿态信息,在配合使用较大的 MLP 时会带来更好的性能。在测试的配置中,较大 MLP 与当前姿态信息的结合产生了最高的成功率。
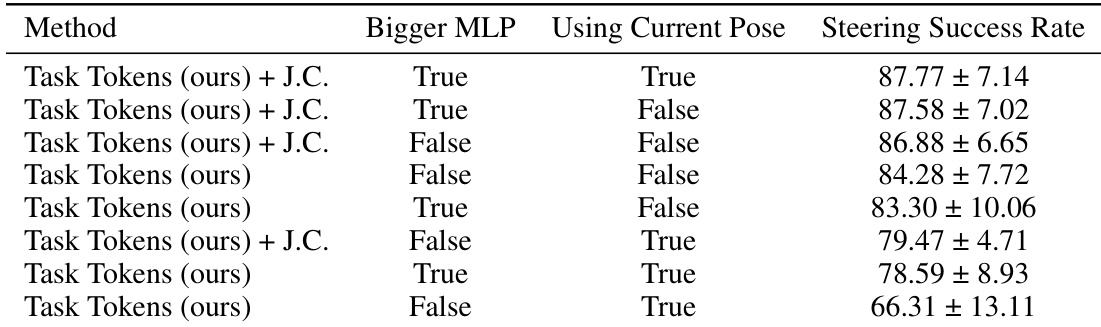
本文通过在五个类人控制任务中将 Task Tokens 的成功率与几种已有的基准线进行比较,并对编码器架构进行消融研究,从而评估了 Task Tokens 方法。结果表明,Task Tokens 提供了有效的任务适配,并实现了极具竞争力的性能,在大多数场景下通常优于或匹配先进的微调及分层方法。此外,消融研究表明,通过利用更大的 MLP 编码器并结合当前姿态信息可以优化性能。