Command Palette
Search for a command to run...
万:开放且先进的大规模视频生成模型
万:开放且先进的大规模视频生成模型
摘要
本报告介绍了Wan——一套全面且开源的视频基础模型系列,旨在推动视频生成技术的边界。Wan基于主流的扩散Transformer架构,通过一系列创新实现生成能力的显著提升,包括我们提出的新型变分自编码器(VAE)、可扩展的预训练策略、大规模数据筛选方法以及自动化评估指标。这些贡献共同提升了模型的性能与通用性。具体而言,Wan具备四大核心特性:领先性能:Wan的140亿参数模型在包含数十亿图像与视频的超大规模数据集上进行训练,充分验证了视频生成任务中数据量与模型规模之间的缩放规律。该模型在多个内部与外部基准测试中,持续超越现有开源模型及业界领先商业解决方案,展现出明显且显著的性能优势。全面性:Wan提供两个不同规模的模型——13亿参数(1.3B)与140亿参数(14B),分别兼顾效率与生成效果。同时,其应用覆盖多种下游任务,包括图像到视频生成、指令引导的视频编辑以及个性化视频生成,共支持多达八项具体任务。消费级高效性:1.3B参数版本展现出卓越的资源效率,仅需8.19 GB显存(VRAM),即可在广泛兼容的消费级GPU上运行,极大降低了使用门槛。开放性:我们已将Wan系列的全部内容开源,包括源代码与所有模型权重,致力于推动视频生成技术社区的发展。该开放举措旨在显著拓展视频制作在产业中的创造性可能,并为学术界提供高质量的视频基础模型资源。所有代码与模型均已发布于GitHub:https://github.com/Wan-Video/Wan2.1。
一句话总结
阿里巴巴集团的作者们提出了 Wan,一个可扩展的开源视频基础模型套件,包含一种新颖的时空变分自编码器(VAE)和大规模预训练,实现了文本到视频生成的最先进性能,提供双版本(1.3B 和 14B),支持多语言输出和消费级效率,并通过全面开放和自动化评估推动视频创作的发展。
主要贡献
-
Wan 引入了一种新颖的时空变分自编码器(VAE)和基于扩散 Transformer 的架构,实现了高保真视频生成,具备精确的运动控制、文本可控性,以及对中英文视觉文本的支持,解决了现有开源模型的关键局限。
-
14B 参数模型在包含数十亿图像和视频的大规模数据集上进行训练,展现出多个基准测试中的最先进性能,超越了开源和商业模型;而 1.3B 变体仅需 8.19 GB 显存,实现了卓越的效率,支持消费级 GPU 部署。
-
Wan 完全开源,包含代码、模型、训练流程和自动化评估指标,支持图像到视频、指令引导编辑、个性化、实时视频生成等多种下游任务,显著提升了视频生成社区的可及性与创新水平。
引言
作者借鉴了基于扩散的视频生成的成功经验,特别是扩散 Transformer(DiT)和流匹配(Flow Matching)方法,开发了 Wan——一个高性能、开源的基础视频模型,旨在弥合开源系统与商业系统之间的差距。这项工作对于推动可访问、可扩展的视频合成至关重要,因为此前的开源模型在性能、能力广度和推理效率方面均落后,尤其对硬件资源有限的创意专业人士而言。为应对这些挑战,作者提出了 Wan,一个在包含千亿级图像和视频的超大规模数据集(O(1) 万亿 token)上训练的 140 亿参数模型,实现了运动质量、文本可控性、相机运动和风格多样性方面的最先进结果。该模型结合了时空变分自编码器和完全优化的 DiT 架构,并采用高效的推理技术,包括扩散缓存、量化和并行策略。值得注意的是,作者还发布了轻量级的 1.3B 变体,可在消费级 GPU 上运行(仅需 8.19GB 显存),显著提升了可及性。除了核心模型,作者还提出了一套统一的框架,支持视频编辑、图像到视频生成、个性化、实时流媒体和音频生成,均基于 Wan 的基础构建。此外,作者还开源了完整的训练流程、评估协议和设计洞察,以赋能社区驱动的视频生成创新。
数据集
- 数据集基于数十亿张来自内部版权材料和公开数据的视频与图像构建,强调高质量、多样性和规模。
- 采用四步数据清洗流程,基于以下基本维度过滤低质量内容:文本覆盖度(通过轻量级 OCR)、美学质量(使用 LAION-5B 分类器)、NSFW 内容(通过内部安全模型)、水印/标志(检测并裁剪)、黑边(基于启发式裁剪)、过曝(专家分类器)、合成图像(专用分类器)、模糊(内部模糊评分模型)以及时长/分辨率约束(最低 4 秒,各阶段分辨率阈值)。该流程使初始数据集减少约 50%。
- 通过聚类(100 个聚类)和评分对视觉质量进行优化:数据被划分为聚类以保留长尾多样性,随后进行人工评分(1–5 分),并用于训练专家模型以完成全数据集评分。
- 运动质量在六个层级上评估:最优运动(流畅、丰富运动)、中等质量运动(明显但不完美)、静态视频(低运动、高画质)、相机驱动运动(仅相机移动)、低质量运动(拥挤、遮挡)、抖动画面(已剔除)。在不同训练阶段动态调整采样比例,以平衡运动、质量与类别分布。
- 针对视觉文本生成,作者合成数亿张包含中文字符的白底图像,并收集真实世界中的富文本图像。OCR 模型从图像/视频中提取文本,输入 Qwen2-VL 生成准确、描述性的标题,结合合成与真实数据以提升字形准确性和真实感。
- 训练后数据单独处理:高分图像通过专家(模型得分前 20%)和人工收集进行优化,确保质量、构图和类别多样性,最终获得数百万张精心筛选的图像。对于视频,根据视觉质量与运动分类选择排名靠前的片段,分别建立简单与复杂运动的独立集合,并在 12 个主要类别(如动物、车辆、科技)间保持平衡。
- 使用内部标题模型生成密集视频标题,该模型在开源视觉语言数据集(图像与视频标题、视觉问答、OCR)和内部数据上训练。内部数据包括:名人/地标/角色身份(通过 LLM 和 TEAM 模型检索并结合关键词过滤)、物体计数(使用 LLM 和 Grounding DINO 验证)、OCR 增强标题(使用 OCR 输出作为先验)、相机角度与运动标注(提升运动可控性)、细粒度类别(数百万张图像)、关系理解(空间关系)、重标题(扩展简短标签)、编辑指令(差异描述)、群体图像描述,以及人工标注的密集标题(最高质量,用于最终训练)。
- 在联合训练中,使用相同的 T2V 数据集以支持图像驱动的视频生成。对于图像到视频(I2V),通过首帧与后续帧均值之间的余弦相似度(SigLIP 特征)过滤视频,仅保留高度一致的样本以确保连贯性。
- 对于视频续写任务,基于前 1.5 秒与后 3.5 秒之间的相似性(SigLIP 特征)过滤视频,以确保时间连贯性。
- 对于首尾帧转换任务,优先选择起始与结束帧间存在显著视觉变化的数据,以提升平滑性。
- 对于可控生成与编辑,视频经过镜头切分、分辨率/美学/运动过滤,并通过 RAM 进行首帧标注。Grounding DINO 检测物体以进行二次过滤(尺寸约束),SAM2 实现实例级分割。基于掩码面积阈值进行时间过滤,保留稳定且有意义的实例。
- 个性化数据通过筛选约 1 亿视频构建,使用人工分类器、人脸检测(1 FPS)和 ArcFace 跨帧相似度(剔除含多张人脸或人脸存在率低的视频)。人脸分割去除背景,地标检测实现对齐。最终获得约 1000 万条个性化视频,平均每视频约 5 个分割人脸。
- 为提升面部多样性,将约 100 万条个性化视频输入 Instant-ID,结合随机风格提示(如动漫、电影、Minecraft)和姿态估计,生成多样化人脸。生成的人脸通过 ArcFace 相似度过滤以确保身份一致性,最终获得约 100 万条额外个性化视频,显著增强风格、姿态、光照和遮挡的多样性。
方法
Wan 视频生成框架基于扩散 Transformer(DiT)架构,由三个主要组件构成:时空变分自编码器(Wan-VAE)、扩散 Transformer 和文本编码器。整个流程从输入视频开始,首先由 Wan-VAE 将其压缩至低维潜在空间。该编码器将视频的时空维度压缩 4×8×8 倍,将输入从 [1+T,H,W,3] 转换为 [1+T/4,H/8,W/8,C]。压缩后的潜在表示随后输入扩散 Transformer,该模块建模去噪过程以生成最终视频。文本编码器(具体为 umT5 模型)处理输入文本提示,并通过交叉注意力机制向扩散 Transformer 提供文本条件。这种集成使模型能够生成与所提供文本语义一致的视频。该框架设计为高度可扩展且高效,支持在多种应用场景中生成高质量视频。
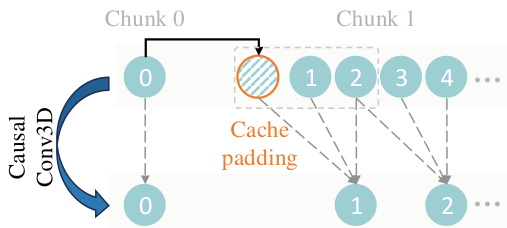
Wan-VAE 是一种专为视频生成挑战设计的新型 3D 因果变分自编码器,旨在解决复杂时空依赖性、高维数据管理与时间因果性等问题。其架构旨在实现高维像素空间与低维潜在空间之间的双向映射。采用 3D 因果卷积结构,首帧进行空间压缩以更好处理图像数据,其余帧则进行时空压缩。为保持时间因果性,所有 GroupNorm 层均替换为 RMSNorm 层,从而支持特征缓存机制。该机制对高效推理至关重要,使模型能够通过分块处理任意长视频,并保留前序块的帧级特征缓存。这确保了上下文块之间的时间连续性,从而支持无限长度视频的稳定推理。特征缓存机制如图所示,展示了模型在处理后续块时如何维护并重用缓存特征。
扩散 Transformer 是 Wan 模型的核心生成组件,由补丁化模块、Transformer 块和去补丁化模块组成。补丁化模块使用核大小为 (1,2,2) 的 3D 卷积,将潜在特征转换为形状为 (B,L,D) 的特征序列,其中 B 为批量大小,L 为序列长度,D 为潜在维度。在每个 Transformer 块中,模型有效建模时空上下文关系,并嵌入文本条件与时间步。交叉注意力机制用于嵌入输入文本条件,确保模型在长上下文建模下仍能遵循指令。此外,采用包含线性层和 SiLU 层的 MLP 处理输入时间嵌入,并分别预测六个调制参数。该设计使参数量减少约 25%,并在相同参数规模下显著提升性能。文本编码器选择 umT5,因其强大的多语言编码能力,能有效理解中英文及视觉文本。实验结果表明,umT5 在组合能力上优于其他单向注意力机制的 LLM,并实现更快收敛。
Wan 模型的训练采用三阶段流程。第一阶段冻结 ViT 和 LLM,仅训练多层感知机以对齐视觉嵌入与 LLM 输入空间。第二阶段使所有参数可训练,第三阶段在少量高质量数据上进行端到端训练。后两个阶段的学习率分别设为 1e−5(LLM 和 MLP)和 1e−6(ViT)。Wan-VAE 采用三阶段训练方法:首先在图像数据上训练结构相同的 2D 图像 VAE;然后将训练良好的 2D 图像 VAE 膨胀为 3D 因果 Wan-VAE,提供初始空间压缩先验,极大提升训练速度。此时,Wan-VAE 在低分辨率(128×128)和小帧数(5 帧)视频上训练以加速收敛。训练损失包括 L1 重建损失、KL 损失和 LPIPS 感知损失,权重系数分别为 3、3e-6 和 3。最后,模型在不同分辨率和帧数的高质量视频上进行微调,并整合来自 3D 判别器的 GAN 损失。
Wan 模型采用流匹配(Flow Matching)框架进行训练,为扩散模型中连续时间生成过程的学习提供了理论基础。训练目标是预测去噪过程的速度,定义为原始潜在 x1 与随机噪声 x0 之间线性插值的导数。模型被训练以预测该速度,损失函数为模型输出与真实速度之间的均方误差(MSE)。训练协议分为三个不同空间分辨率的阶段:第一阶段联合训练 256 px 分辨率图像与 5 秒视频片段(192 px 分辨率,16 fps);第二阶段将图像与视频分辨率均提升至 480 px,同时保持 5 秒视频时长不变;最终阶段将图像与视频空间分辨率均提升至 720 px。这种分辨率渐进式课程有助于缓解长序列长度和 GPU 内存过度消耗的挑战,确保训练稳定与模型收敛。
Wan 模型的训练与推理针对大规模分布式计算进行了优化。模型包含三个模块:VAE、文本编码器和 DiT。VAE 模块 GPU 内存占用极低,可无缝采用数据并行(DP)。相比之下,文本编码器需超过 20 GB GPU 内存,因此需采用模型权重分片以节省后续 DiT 模块的内存。为此,采用数据并行(DP)结合全分片数据并行(FSDP)策略。DiT 模块占整体计算负载的显著比例,通过 FSDP 与上下文并行(CP)结合优化。CP 策略通过分片序列长度维度降低每块 GPU 的激活内存占用。提出一种二维(2D)CP,融合 Ulysses 与 Ring Attention 特性,缓解 Ulysses 的跨机器通信慢问题,并解决 Ring Attention 分片后对大块大小的需求。该设计最大化外层通信与内层计算的重叠,将 2D 上下文并行的通信开销降至 1% 以下。FSDP 组与 CP 组在 FSDP 组内相交,DP 大小等于 FSDP 大小除以 CP 大小。该分布式方案实现了 DiT 模块的高效扩展。
内存优化是 Wan 模型训练与推理的关键。Wan 中的计算成本随序列长度呈二次增长,而 GPU 内存使用随序列长度线性增长。这意味着在长序列场景下,计算时间最终可能超过激活数据卸载所需的 PCIe 传输时间。为解决此问题,优先采用激活卸载以减少 GPU 内存使用,同时不牺牲端到端性能。由于 CPU 内存在长序列场景下也易耗尽,因此结合使用卸载与梯度检查点(GC)策略,优先对 GPU 内存与计算比高的层启用梯度检查点。推理阶段的主要目标是降低视频生成延迟。采用量化与分布式计算技术以减少每步所需时间。利用步骤间注意力相似性以降低整体计算负载。对于无分类器指导(CFG),利用其内在相似性进一步降低计算需求。推理过程通过 2D 上下文并行与 FSDP 的组合优化,使 Wan 14B 模型实现近乎线性的加速。使用 FP8 GEMM 与 8 位 FlashAttention 进一步提升推理效率,DiT 模块实现 1.13× 加速,整体推理效率提升超过 1.27×。
实验
- Wan-VAE 在视频重建方面表现优异,PSNR 高,重建速度比 HunYuan Video 快 2.5 倍,且在纹理、人脸、文字和高运动场景中具有更优的定性结果。
- 在 VBench 排行榜上,Wan 14B 达到 86.22% 的最先进综合得分,包括视觉质量 86.67% 和语义一致性 84.44%,超越商业模型 Sora 和 Hailuo,以及开源模型 CogVideoX 和 HunyuanVideo。
- Wan 1.3B 变体在 VBench 上取得 83.96% 的得分,超越 HunyuanVideo、Kling 1.0 和 CogVideoX1.5-5B,尽管参数更小,仍展现出强大效率与竞争力。
- 消融实验表明,完全共享的 AdaLN 降低参数量而不牺牲性能;umT5 在文本嵌入质量上优于其他文本编码器;带重建损失的 VAE 的 FID 低于带扩散损失的 VAE-D。
- 扩散缓存通过利用采样步骤间注意力与 CFG 的相似性,使推理速度提升 1.62×,支持高效高分辨率生成。
- Wan 在文本到视频生成方面表现出色,生成高质量、动态且具有电影感的视频,准确整合多语言文本并合成复杂运动,经人工评估与基准测试验证。
- 视频个性化在未见身份上实现高 ArcFace 相似度,表明生成视频中身份保持能力强。
- V2A 模型生成的音频比 MMAudio 更具一致性、更清晰、节奏更准确,但目前因训练中未包含语音数据,仍难以处理人声。
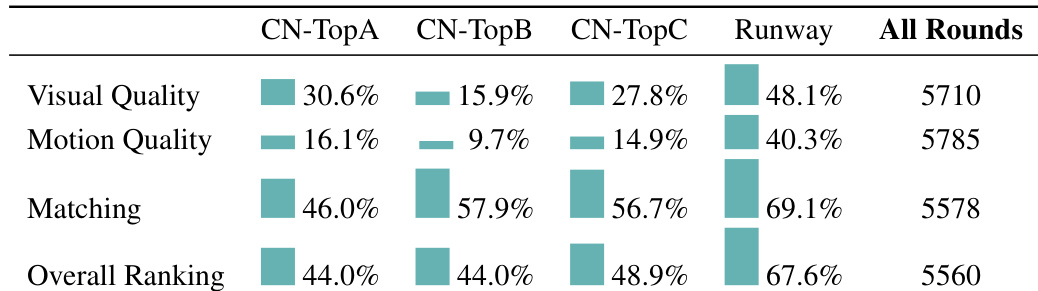
作者采用人工评估框架,从视觉质量、运动质量、匹配度和整体排名等多个维度评估模型性能。结果显示,该模型在运动质量和整体排名上胜率最高,尤其在 CN-TopD 类别中表现突出,但在匹配度方面相比其他模型表现较弱。

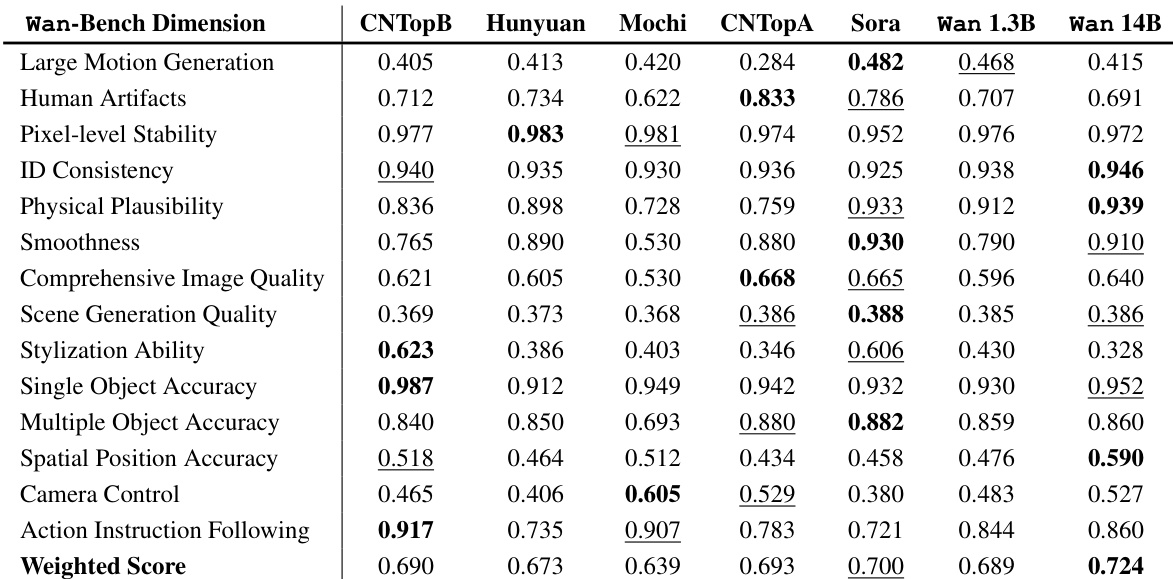
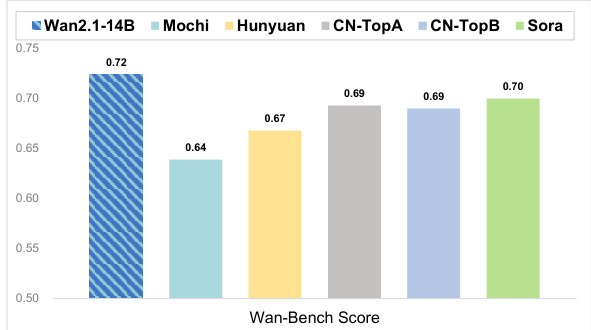
作者使用 Wan-Bench 评估框架,将 Wan-2.1-14B 模型与多个商业及开源文本到视频模型进行对比。结果显示,Wan-2.1-14B 获得最高 Wan-Bench 得分 0.72,优于 Mochi、Hunyuan、CN-TopA、CN-TopB 和 Sora 等模型。
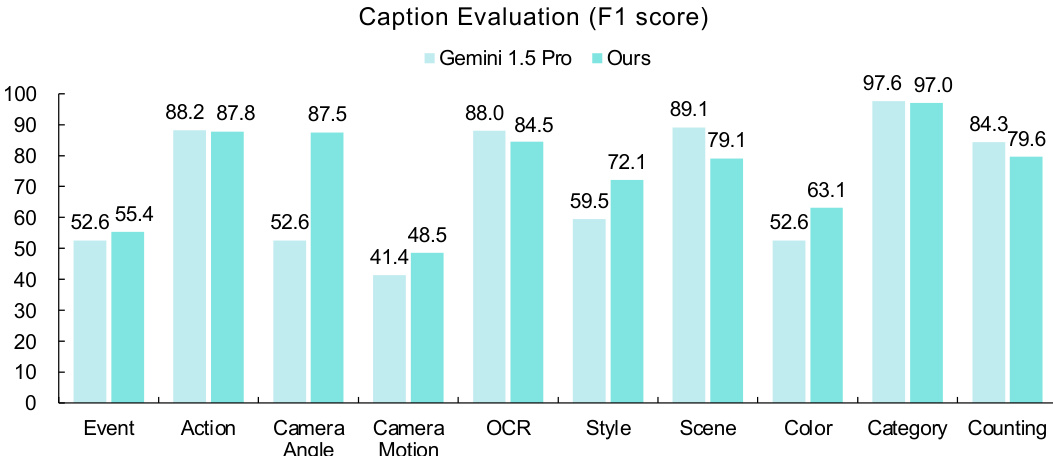
结果显示,所提模型在视频事件、相机角度、相机运动、风格和物体颜色方面优于 Gemini 1.5 Pro,而 Gemini 在动作、OCR、场景、物体类别和物体计数方面表现更优。模型在多数视觉维度上 F1 分数高于 Gemini,尤其在事件、相机角度和风格方面提升最大。
作者使用人工评估框架,将 Wan 14B 模型与多个商业及开源文本到视频模型在多个维度上进行比较。结果显示,Wan 在整体排名上优于竞争对手,匹配度与运动质量胜率最高,并在所有评估轮次中视觉质量与整体排名表现最佳。
作者使用 Wan-Bench 评估框架,将模型与多个最先进的文本到视频系统进行对比,重点关注运动生成、图像质量与指令遵循能力。结果显示,Wan 14B 模型获得最高加权得分,在大多数维度上超越 Sora 和 Hunyuan,尤其在大范围运动生成、物理合理性与动作指令遵循方面表现突出。