Command Palette
Search for a command to run...
140万开源蒸馏推理数据集,助力大型语言模型训练
140万开源蒸馏推理数据集,助力大型语言模型训练
Han Zhao Haotian Wang Yiping Peng Sitong Zhao Xiaoyu Tian Shuaiting Chen Yunjie Ji Xiangang Li
摘要
AM-DeepSeek-R1-Distilled 是一个大规模的、包含思维轨迹的通用推理任务数据集,由高质量且具有挑战性的推理问题构成。这些问题源自多个开源数据集,经过语义去重和细致清洗,以消除测试集污染。数据集中所有回答均来自推理模型(主要为 DeepSeek-R1)的蒸馏结果,并经过严格的验证流程:数学问题通过与标准答案比对进行验证,代码问题通过测试用例进行验证,其他类型任务则借助奖励模型进行评估。基于该数据集仅通过简单监督微调(SFT)训练得到的 AM-Distill-Qwen-32B 模型,在 AIME2024、MATH-500、GPQA-Diamond 和 LiveCodeBench 四个基准测试中均超越了 DeepSeek-R1-Distill-Qwen-32B 模型;此外,AM-Distill-Qwen-72B 模型在所有基准测试中也优于 DeepSeek-R1-Distill-Llama-70B 模型。为推动高性能推理导向大型语言模型(LLMs)的发展,我们已将包含140万道问题及其对应回答的完整数据集公开发布至研究社区。该数据集已发布于:https://huggingface.co/datasets/a-m-team/AM-DeepSeek-R1-Distilled-1.4M。
一句话总结
来自 a-m-team 的作者介绍了 AM-DeepSeek-R1-Distilled,这是一个包含 140 万道经过验证推理路径的高质量问题数据集,源自 DeepSeek-R1 的知识蒸馏,使得通过 SFT 训练的 AM-Distill-Qwen 模型在关键基准测试中超越了更大规模的前辈模型,推动了具备推理能力的大语言模型发展。
主要贡献
- AM-DeepSeek-R1-Distilled 数据集通过整合来自多样化开源来源的 140 万道精心筛选的问题,解决了高质量、大规模推理数据的需求,经过严格的语义去重和污染清除,确保了数据的纯净性与挑战性。
- 该数据集包含从 DeepSeek-R1 蒸馏而来的推理路径,并通过多种方法进行验证——数学问题采用答案校验,代码问题使用测试用例,其他任务则借助奖励模型,确保训练数据的高准确性和可靠性。
- 通过简单的监督微调(SFT)在该数据集上训练的模型,如 AM-Distill-Qwen-32B 和 AM-Distill-Qwen-72B,在四个主要基准测试中均优于其 DeepSeek-R1 对应模型,证明了该数据集在提升推理能力方面的有效性。
引言
作者利用新发布的 140 万条蒸馏推理示例的开源数据集,以增强大语言模型的训练,尤其针对需要结构化推理和意图理解的任务。该数据集旨在支持指令调优,提供高质量、难度分级的查询,涵盖从基础事实回忆到专家级问题解决的广泛认知需求。此前相关工作常依赖有限或专有的数据集,且难度标注不一致,阻碍了模型的泛化能力和可靠评估。本研究的主要贡献在于构建了一个大规模、公开可用的数据集,具备细粒度的难度标注,从而实现对大语言模型推理能力更精确的训练与基准测试。
数据集
- AM-DeepSeek-R1-Distilled 数据集包含 140 万条高质量的推理问题-回答配对,数据来源包括开源数据集与模型蒸馏内容的结合。
- 其中 50 万条完全源自开源数据集,涵盖数学、代码、科学问答和通用对话数据;其余 90 万条的指令来自开源材料,而回答则由 DeepSeek-R1 蒸馏生成。
- 数据来源包括高质量基准测试如 NuminaMath、MetaMathQA、OpenCoder、Omni-MATH、PRIME、CodeIO、MATH-lighteval,以及社区提供的数据集如 OpenThoughts、OpenR1Math、KodCode 和 Dolphin-R1。通用对话数据来自 InfinityInstruct 和 Orca。
- 数据集分为四大主要类别——数学、代码、科学问答和通用对话,并通过 Qwen2.5-7B-Instruct 生成额外的细粒度标签(如创意写作、指令遵循),以增强多样性与可用性。
- 为确保数据质量与挑战性,作者使用大语言模型对指令难度进行评分,并对简单和中等难度样本进行下采样,聚焦于更复杂的推理任务。
- 采用基于嵌入和相似度阈值的严格语义去重策略,结合优先规则,每个聚类仅保留一个代表性条目,确保唯一性与多样性。
- 所有回答均经过多阶段验证:数学问题通过基于规则的检查(math-verify)和大语言模型评估;代码问题在沙箱环境中使用测试用例进行测试;非代码/数学任务则由奖励模型(Decision-Tree-Reward-Llama-3.1-8B)和 Qwen2.5-7B-Instruct 评估,仅保留得分高于阈值的结果。
- 基于规则的检查确保格式合规(如正确使用 和 标签),并剔除存在过度 n-gram 重复的响应。
- 每条记录包含丰富的元数据:语言(英文、中文或其他)、token/词数、类别、难度评分,以及参考答案或测试用例。
- 数据集采用统一、标准化的格式,便于无缝集成到训练流程中。
- 作者使用该数据集对 AM-Distill-Qwen-32B 和 AM-Distill-Qwen-72B 模型进行监督微调(SFT),在 AIME2024、MATH-500、GPQA-Diamond 和 LiveCodeBench 上达到最先进性能。
- 训练过程中混合使用全部 140 万条数据,未进行显式划分,但数据的高难度与长推理链设计旨在支持更长的思维链(Chain-of-Thought)训练。
- 该数据集已在 Hugging Face 上发布,采用仅限研究用途的许可协议,附带警告:模型生成的回答可能存在不准确,使用前需谨慎审查。
实验
- 在多个基准测试上评估 AM-Distill-Qwen-32B 和 AM-Distill-Qwen-72B 模型,采用一致的生成设置:最大长度 32,768 token,温度 0.6,top-p 0.95,AIME 2024 使用 16 个样本,其他基准使用 4 个样本以估算 pass@1。
- AM-Distill-Qwen-32B 在准确率上优于 DeepSeek-R1-Distill-Qwen-32B:AIME2024(72.7% vs. 72.6%)、MATH-500(96.2% vs. 94.3%)、GPQA Diamond(64.3% vs. 62.1%)、LiveCodeBench(59.1% vs. 57.2%),整体平均准确率从 71.6% 提升至 73.1%。
- AM-Distill-Qwen-72B 超越 DeepSeek-R1-Distill-Llama-70B:AIME2024(76.5% vs. 70.0%)、MATH-500(97.0% vs. 94.5%)、GPQA Diamond(65.9% vs. 65.2%)、LiveCodeBench(59.7% vs. 57.5%)。
- 结果验证了在 AM-DeepSeek-R1-Distilled-1.4M 数据集上训练能显著提升模型在多样化基准上的推理能力。
- 数据集难度分布显示 51.8% 为中等难度,25.7% 为高难度,表明其聚焦于具有挑战性的推理任务。
作者使用 AM-Distill-Qwen-32B 和 AM-Distill-Qwen-72B 模型在四个基准上评估性能,结果均优于基线模型。结果显示,AM-Distill-Qwen-32B 在所有基准上均取得更高准确率,尤其在 MATH-500(96.2% vs. 94.3%)和 GPQA Diamond(65.9% vs. 62.1%)上提升显著;AM-Distill-Qwen-72B 则在 AIME 2024(76.5% vs. 70.0%)和 MATH-500(97.0% vs. 94.5%)上显著超越 DeepSeek-R1-Distill-Llama-70B。
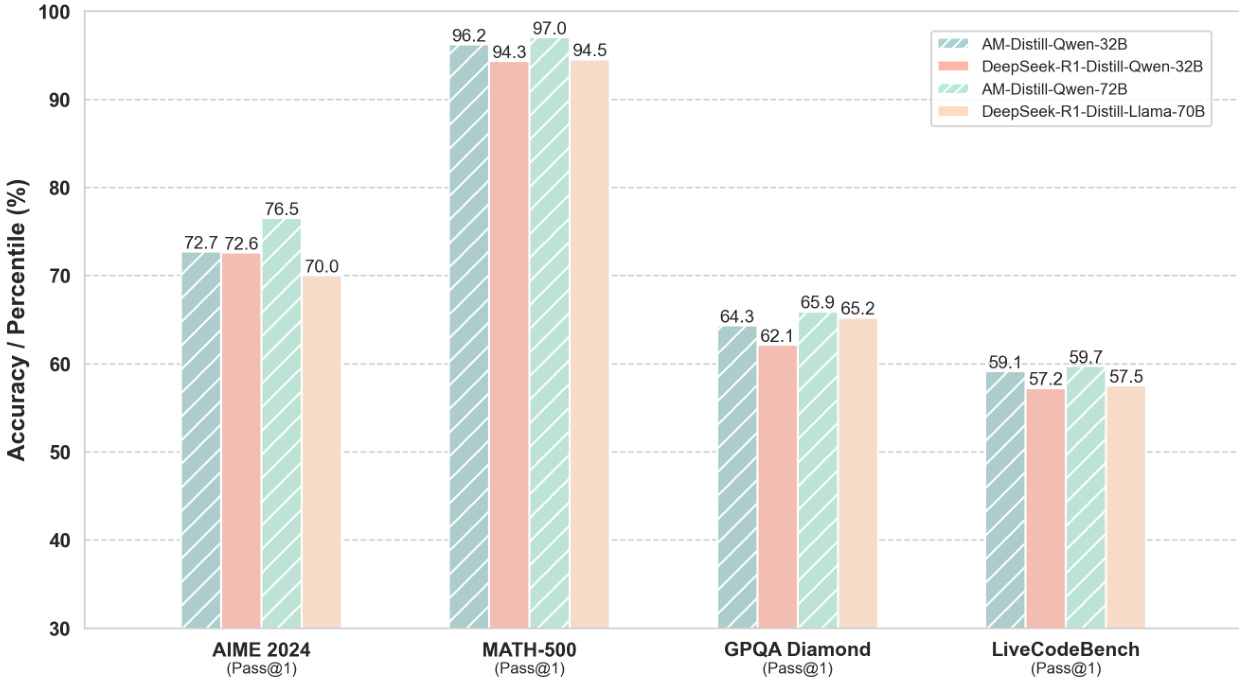
作者使用在 AM-DeepSeek-R1-Distilled-1.4M 数据集上训练的 AM-Distill-Qwen-32B 模型,在所有基准上均实现优于 DeepSeek-R1-Distill-Qwen-32B 的性能,平均准确率从 71.6% 提升至 73.1%。结果表明,AM-Distill-Qwen-72B 模型进一步提升了性能,平均准确率达到 74.8%,在所有评估任务中均优于 DeepSeek-R1-Distill-Llama-70B。
