Command Palette
Search for a command to run...
稳定虚拟相机:基于扩散模型的生成式视图合成
稳定虚拟相机:基于扩散模型的生成式视图合成
Jensen Zhou Hang Gao Vikram Voleti Aaryaman Vasishta Chun-Han Yao Mark Boss Philip Torr Christian Rupprecht Varun Jampani
摘要
我们提出Stable Virtual Camera(Seva),一种通用的扩散模型,能够根据任意数量的输入视角和目标相机位姿,生成场景的新视角。现有方法在实现大幅视角变化或生成时序连贯的样本方面存在困难,且通常依赖于特定任务的配置。我们的方法通过简洁的模型设计、优化的训练策略以及灵活的采样机制,在测试阶段实现了对多种视图合成任务的广泛泛化能力,有效克服了上述局限。结果表明,Seva生成的图像在不依赖额外基于3D表示的蒸馏过程的情况下,仍能保持高度的一致性,从而显著简化了真实场景中的视图合成流程。此外,我们还证明,该方法可生成长达半分钟、且具有无缝循环闭合效果的高质量视频。大量基准测试结果表明,Seva在不同数据集和设置下均显著优于现有方法。项目主页(含代码与模型):https://stable-virtual-camera.github.io/。
一句话总结
来自 Stability AI、牛津大学和加州大学伯克利分校的作者提出 SEVA,一种通用扩散模型,能够在无需 3D 蒸馏的情况下,实现跨多样化相机轨迹的高保真、时间连贯的视图合成,其简单而灵活的设计在真实场景应用中展现出更优的一致性和可扩展性。
主要贡献
-
STABLE VIRTUAL CAMERA (SEVA) 通过在非受控环境中实现高质量图像与视频生成,解决了生成式新视图合成的挑战,支持任意数量的输入与目标视图,无需刚性任务配置或显式 3D 表示,适用于多样化相机轨迹。
-
该方法引入了一种两阶段过程化采样策略和训练方案,联合优化大视角变化与时间平滑性,实现长达 30 秒的无缝视频生成,具备精确相机控制与闭环能力,且无需依赖 NeRF 蒸馏。
-
在 10 个数据集上的广泛基准测试表明,SEVA 超越了先前最先进方法,在其原生设置下相比 CAT3D 提升 +1.5 dB PSNR,并在真实用户采集数据上展现出强大泛化能力,输入视图数量范围从 1 到 32。
引言
作者利用扩散模型应对在非受控、真实世界场景中生成式新视图合成(NVS)的挑战,此类场景中输入视图稀疏且相机控制灵活。先前方法存在两个关键局限:要么难以处理大视角变化,要么无法生成时间平滑的视频输出;且多数方法需依赖 NeRF 蒸馏以保证 3D 一致性,使流程复杂化。此外,现有模型通常为特定任务设计——或优化于基于集合的视图生成,或针对轨迹式视频合成——限制了其灵活性。作者提出 STABLE VIRTUAL CAMERA (SEVA),一种统一的基于扩散的 NVS 模型,摒弃显式 3D 表示,实现任意相机轨迹下高质量、时间连贯的视图合成,支持任意数量的输入与目标视图。其方法结合了精心设计的训练策略,覆盖小与大视角变化,以及一种两阶段过程化采样方法,确保平滑插值与长轨迹稳定性。SEVA 在多种数据集与设置中均达到最先进性能,实现高达 30 秒的高保真视频,具备无缝闭环能力,且无需 NeRF 蒸馏。
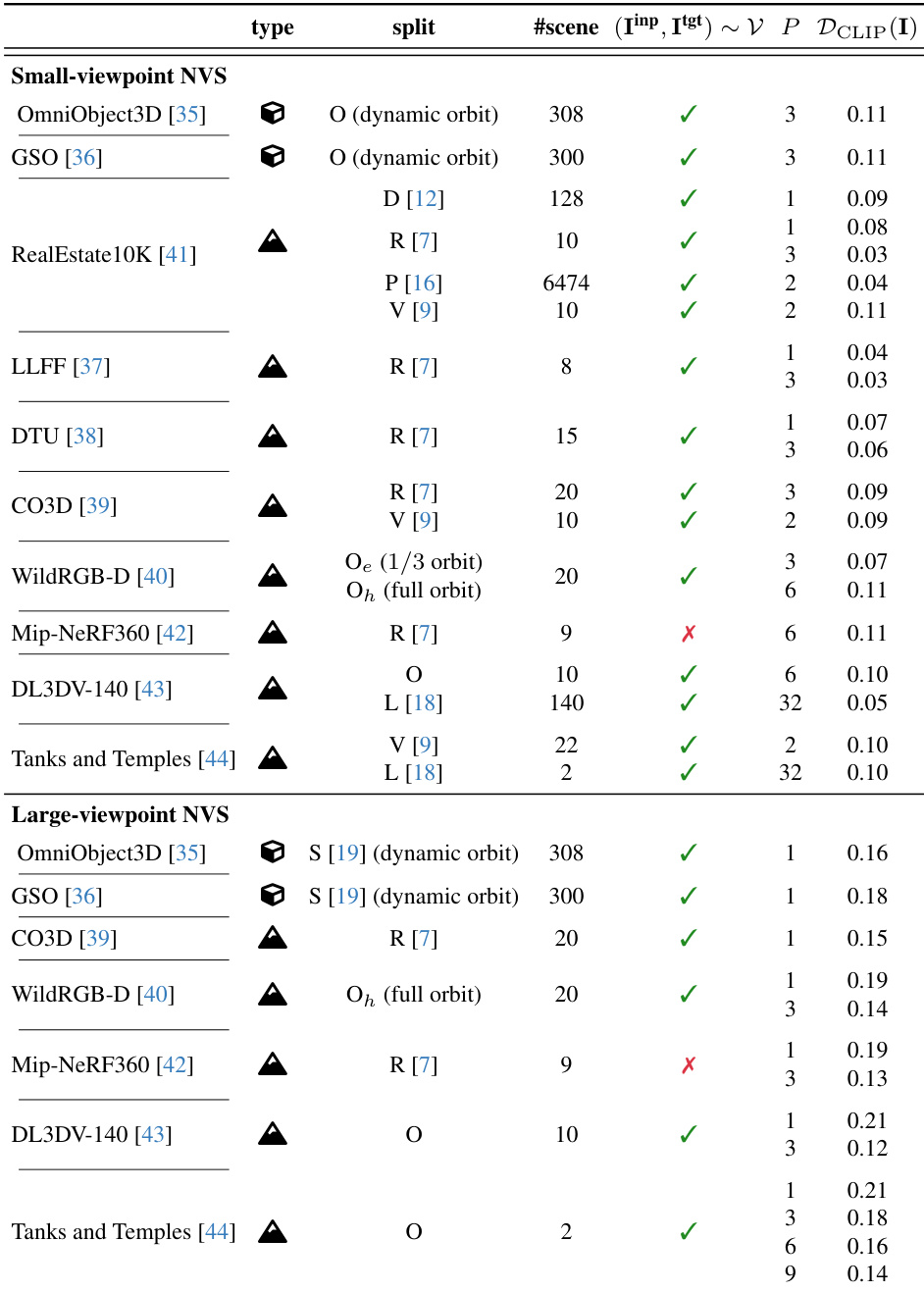
数据集
- 基准数据集包含 10 个公开可用的数据集,涵盖物体级、以物体为中心的场景和完整场景类别,包括 OmniObject3D、GSO、LLFF、DTU、CO3D、WildRGBD、RealEstate10K、Mip-NeRF 360、DL3DV-140 和 Tanks and Temples。
- 数据集按先前研究中的多个划分方式组织——4DiM (D)、ViewCrafter (V)、pixelSplat (P)、ReconFusion (R)、SV3D (S)、Long-LRM (L),以及一个新定义的划分 (O),该划分在未特别说明时使用所有可用场景。
- 对于 O 划分,测试场景选择如下:Tanks and Temples 中的 TRAIN 和 TRUCK;DL3DV-140 中 10 个由唯一 ID 标识的特定场景;WildRGBD 中 20 个场景,每个包含特定物体与场景标识(如 BALL/SCENE_563);其余所有数据集均使用完整测试集。
- 输入视图(P)从稀疏(P=1)到半密集(P=3),支持在不同输入灵活性范式下的评估。
- 基准测试根据输入与目标视图之间的 CLIP 特征差异,区分小视角与大视角新视图合成(NVS)。平均 CLIP 距离 ≤ 0.11 的任务归类为小视角(强调插值平滑性),> 0.11 的则为大视角(评估生成能力)。
- 对 WildRGBD,定义两种难度级别:O_e(易)使用原始序列的三分之一(约 120° 旋转),O_h(难)使用完整序列(约 360° 旋转)。两种情况下均均匀子采样 21 帧,P 帧随机选为输入,其余作为目标。
- 对 DL3DV-140 和 Tanks and Temples,目标帧按原始序列每第 8 帧选取。其余帧通过在结合相机平移与方向的 6D 向量上使用 K-means(K=32)聚类,以确保输入覆盖多样性。
- 作者在多个划分上使用数据进行训练与评估,模型性能在小视角与大视角设置下均有报告。对于 P=1,通过扫过相机归一化单位长度以解决尺度模糊问题。
- 所有结果均采用与先前工作相同的输入与目标视图配置计算,仅 O 划分使用自定义场景与视图选择。
- 构建了包括基于 CLIP 的差异与视图选择逻辑在内的元数据,以实现不同 NVS 任务间一致且可复现的评估。
方法
作者采用多视图扩散模型架构,记为 pθ,以应对新视图合成(NVS)任务。该模型基于 Stable Diffusion 2.1(SD 2.1)框架,包含一个自编码器(VAE)和一个潜在去噪 U-Net。核心架构通过将 U-Net 低分辨率残差块中的 2D 自注意力层扩展为 3D 自注意力,以处理多视图输入,使模型能够捕捉跨视图的空间与时间依赖性。为进一步增强模型容量,在每个自注意力块后通过跳跃连接沿视图轴添加 1D 自注意力。模型训练为“M-in N-out”扩散模型,其中上下文窗口长度 T=M+N 在训练期间固定。训练过程采用两阶段课程:第一阶段使用 T=8 的上下文窗口与大批次,第二阶段将上下文窗口扩大至 T=21 并减小批次大小。该课程有助于防止训练发散。模型条件输入包括:输入视图的 VAE 潜在表示、其对应的相机位姿(以 Plücker 嵌入编码)以及来自 CLIP 图像嵌入的高层语义信息。相机位姿相对于首个输入相机进行归一化,并缩放至 [−2,2]3 立方体内。条件信息通过拼接与自适应层归一化施加。模型在 576×576 分辨率的正方形图像上进行训练。
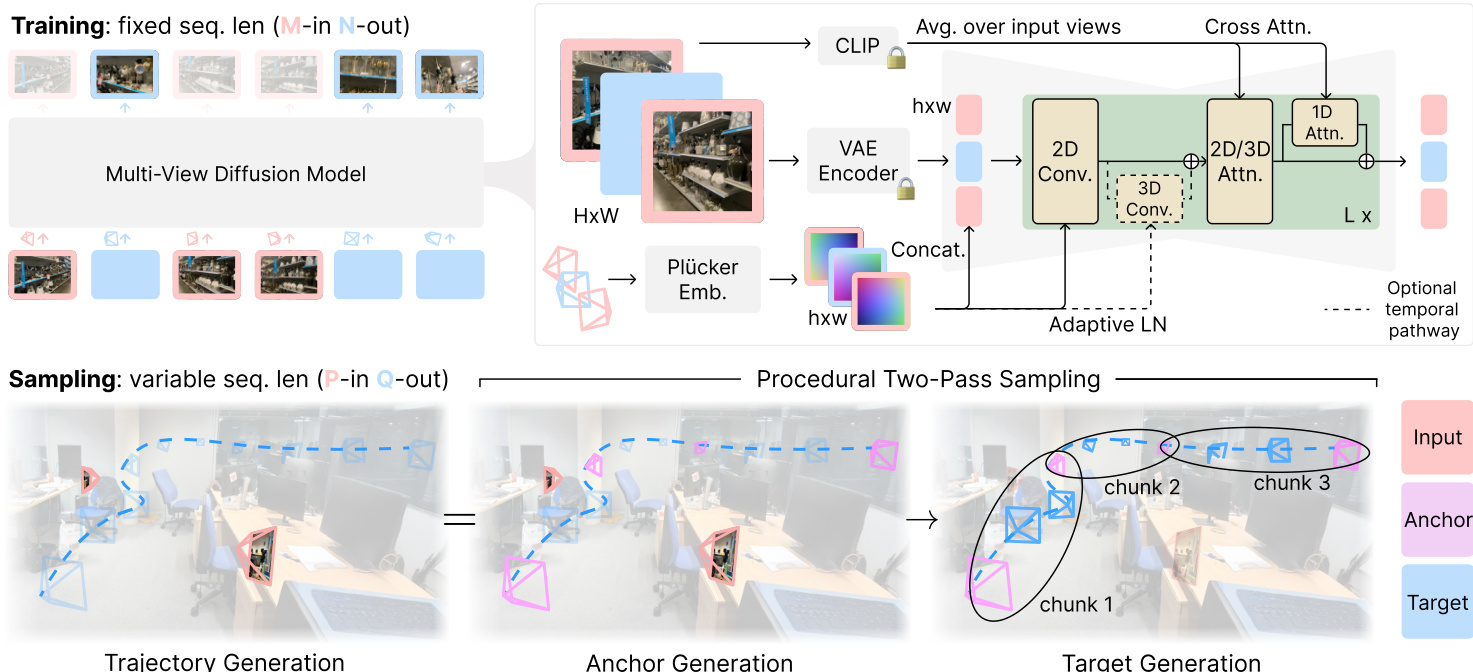
在测试阶段,模型用于处理广泛的 NVS 任务,可建模为“P-in Q-out”问题,其中 P 与 Q 为可变参数。作者提出一种过程化两阶段采样策略,以应对 P+Q>T 的情况。第一阶段,模型使用所有可用输入帧生成一组锚点帧 Iacr。第二阶段,目标帧以块为单位生成,利用先前生成的锚点帧维持一致性。对于集合 NVS,采用最近邻过程化采样策略,将目标帧与其最近的锚点帧分组;对于轨迹 NVS,则采用插值过程化采样策略,先生成部分目标帧作为锚点,其余帧在它们之间进行插值。该方法确保生成视图间的时间平滑性与 3D 一致性。
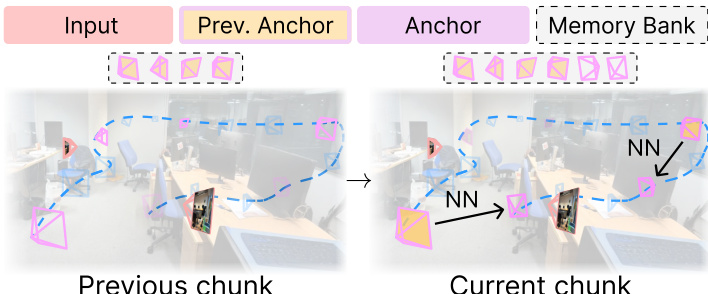
在目标视图数量 Q 显著大于上下文窗口 T 的场景中,引入记忆库以维持长期 3D 一致性。该记忆库存储先前生成的锚点视图及其对应相机位姿。在生成新锚点时,模型从该记忆库中检索其空间最近邻,确保生成视图与全局场景结构一致。该策略在长轨迹与大规模集合 NVS 任务中尤为有效,其中维持大量帧间的一致性至关重要。
实验
- SEVA 模型在生成能力、插值平滑性与输入灵活性三个关键指标上均表现优异,展现出在多种 NVS 任务(包括集合 NVS、轨迹 NVS 与长轨迹 NVS)中的强泛化能力。
- 在小视角集合 NVS 上,SEVA 达到最先进 PSNR 结果,LLFF(P=3)上提升 +6.0 dB,且在半密集视图场景中超越专用模型(如 T&T 上 P=32 时提升 +1.7 dB);在 RE10K(P=2)上相比先前扩散模型提升 +4.2 dB。
- 在大视角集合 NVS 上,SEVA 优势更为显著,在 Mip360(P=3)上相比 CAT3D 提升 +0.6 dB PSNR,并在 DL3DV 与 T&T 等挑战性场景中保持强劲性能。
- 在轨迹 NVS 中,SEVA 生成了逼真的平滑过渡,跨越复杂相机路径,PSNR 与时间质量(MS↑)及 3D 一致性(TSED↓,PSNR↑)均有显著提升,尤其在使用插值过程化采样与可选时间路径时表现更优。
- 在长轨迹 NVS 中,SEVA 通过空间记忆库在 1000+ 帧上维持 3D 一致性,相比时间邻域查找显著减少伪影,展现出在开放导航中的鲁棒性。
- SEVA 在零样本场景下可泛化至更长上下文窗口与更高图像分辨率,生成高质量输出,支持竖屏与横屏方向,在半密集视图设置中 3D 一致性进一步提升。
- 模型对多种输入类型(单视图、稀疏视图、文本提示图像)展现出强零样本泛化能力,生成区域多样且合理,通过多随机种子验证。
结果表明,SEVA 在多个数据集的小视角集合 NVS 中达到最先进性能,尤其在稀疏视图场景中实现显著 PSNR 提升。在大视角集合 NVS 中,SEVA 展现出强大生成能力,在 DL3DV 与 T&T 等挑战性场景中表现优异,PSNR 与感知质量均有显著提升。
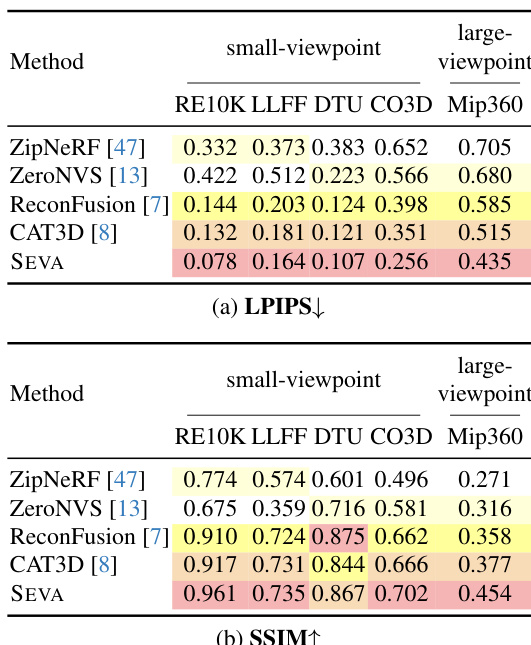
结果表明,SEVA 在大多数小视角集合 NVS 划分中达到最先进性能,尤其在稀疏视图场景中相比先前方法实现显著 PSNR 提升。模型在半密集视图场景中也展现出强泛化能力,尽管未专门针对该设置设计,仍优于某些数据集上的专用模型。
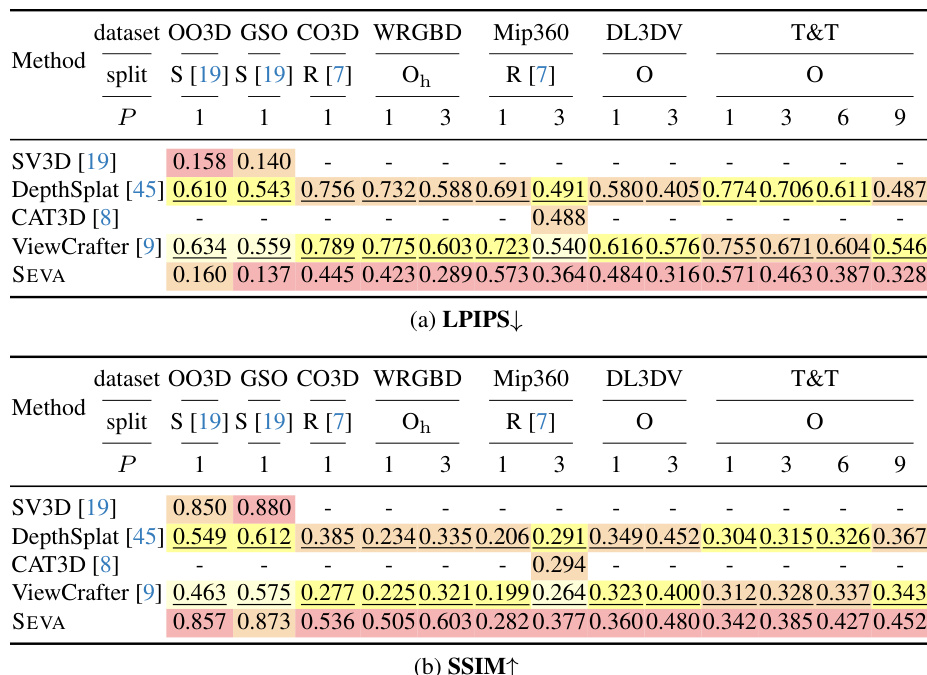
结果表明,SEVA 的两阶段过程化采样结合插值过程化采样在所有指标上均表现最佳,PSNR 与 MS 分数最高。时间路径的引入进一步提升了时间质量,而单阶段方法因闪烁增加与 3D 一致性下降而表现较差。
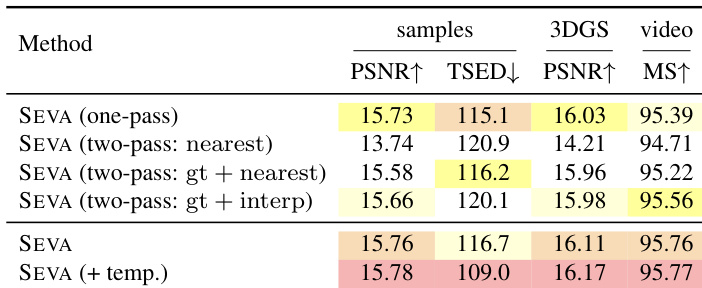
结果表明,SEVA 在大多数小视角集合 NVS 设置中达到最先进性能,尤其在稀疏视图场景中相比先前方法实现显著 PSNR 提升。模型在大视角集合 NVS 与轨迹 NVS 中也表现出强泛化能力,生成逼真输出,过渡平滑且 3D 一致性高,即使在处理复杂相机运动与长轨迹时亦然。
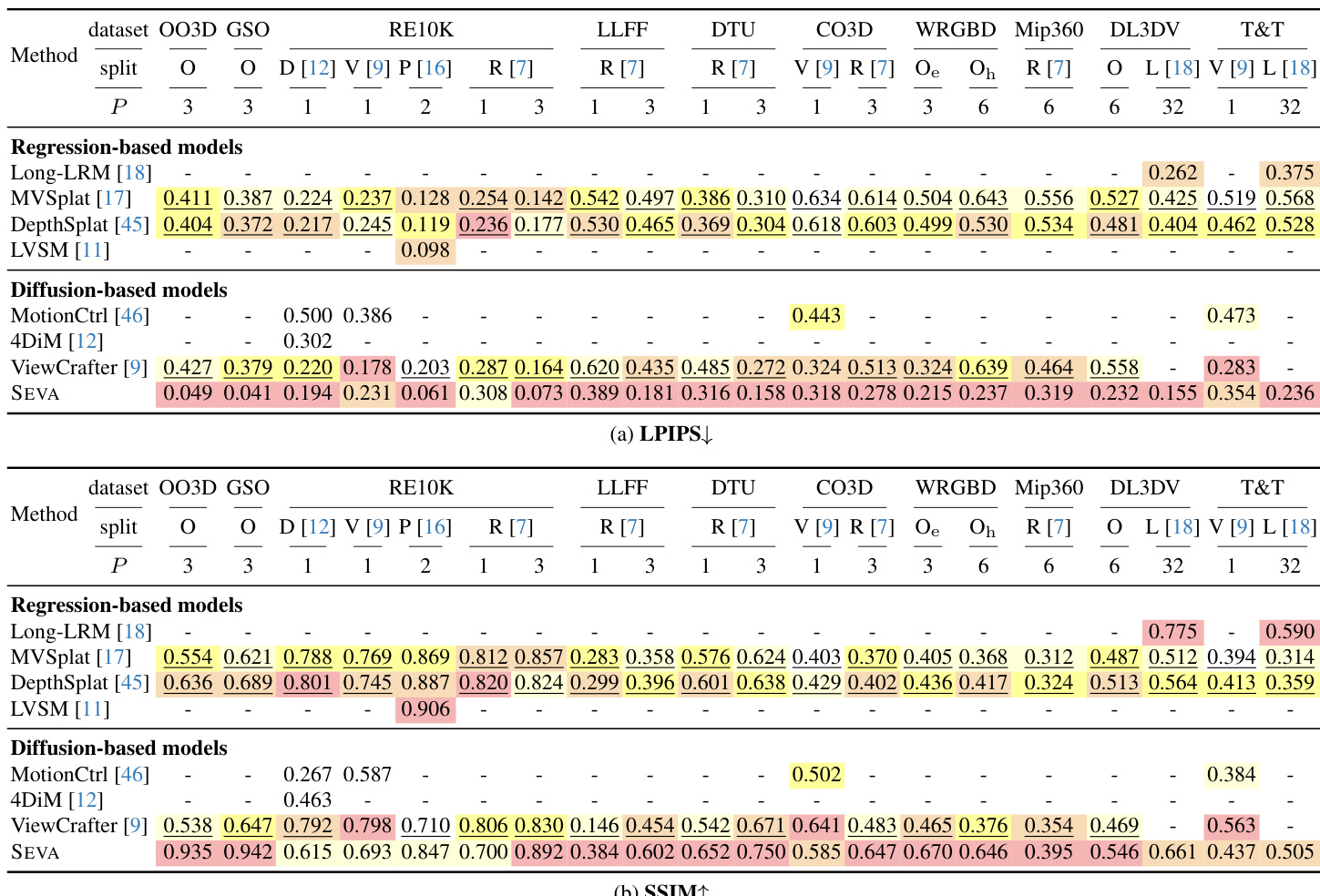
作者使用表 2 评估 SEVA 在小视角新视图合成(NVS)上于多种数据集与输入范式下的性能。结果表明,SEVA 在多数划分中达到最先进 PSNR,尤其在稀疏视图场景(P ≤ 8)中表现突出,在半密集视图场景(P = 32)中也表现良好,尽管未专门为此设置优化。模型在 OO3D 与 GSO 等物体数据集上表现尤为强劲,超越所有其他方法。