Command Palette
Search for a command to run...
R1-Onevision:通过跨模态形式化推进泛化多模态推理
R1-Onevision:通过跨模态形式化推进泛化多模态推理
摘要
大规模语言模型在复杂文本任务中已展现出卓越的推理能力。然而,多模态推理——即需要融合视觉与文本信息的推理——仍面临重大挑战。现有的视觉-语言模型往往难以有效分析和推理视觉内容,导致在复杂推理任务中表现欠佳。此外,缺乏全面的评估基准也限制了对多模态推理能力的准确衡量。本文提出R1-Onevision,一种旨在弥合视觉感知与深度推理之间鸿沟的多模态推理模型。为实现这一目标,我们设计了一种跨模态推理流程,将图像转化为形式化的文本表征,从而支持精确的语言驱动推理。基于该流程,我们构建了R1-Onevision数据集,该数据集在多个领域提供了详尽、分步骤的多模态推理标注。在此基础上,我们通过监督微调与强化学习进一步优化R1-Onevision模型,以培养其先进的推理能力与强大的泛化性能。为进一步全面评估不同层级下的多模态推理表现,我们提出了R1-Onevision-Bench,一个与人类教育阶段相契合的基准测试体系,涵盖从小学到大学乃至更高层次的各类考试题目。实验结果表明,R1-Onevision在多个具有挑战性的多模态推理基准上达到当前最优性能,显著优于GPT-4o、Qwen2.5-VL等先进模型。
一句话总结
浙江大学、微信视觉(腾讯公司)和中国人民大学的研究人员提出了 R1-Onevision,一种多模态推理模型,能够将图像转化为形式化的文本表示,实现精确的语言推理。该模型通过跨模态流程和与人类教育阶段对齐的新基准,在复杂任务上超越了 GPT-4o 和 Qwen2.5-VL。
主要贡献
- 现有的视觉-语言模型在多模态推理方面表现不佳,主要由于视觉感知与深度文本推理的整合不足,难以处理复杂的结构化视觉任务,如基于图表的问题求解。
- 作者提出了一种跨模态推理流程,将图像转化为形式化文本表示,支持精确、分步推理,并构建了 R1-Onevision 数据集,涵盖多个领域且带有详细标注的推理轨迹。
- R1-Onevision 在多模态推理基准上达到最先进性能,超越 GPT-4o 和 Qwen2.5-VL 等模型,并通过与中学至大学教育阶段对齐的 R1-Onevision-Bench 新基准进行评估。
引言
作者针对大语言模型中多模态推理的挑战展开研究,即如何将视觉感知与深度、结构化推理有效结合仍存在困难。以往模型要么依赖僵化的预定义推理模板,限制灵活性;要么仅模仿真实答案而缺乏真实推理过程,导致泛化能力差,难以应对复杂视觉任务。此外,现有基准范围狭窄,多集中于数学等特定领域,且与真实世界教育发展进程脱节。为克服这些局限,作者提出 R1-Onevision,一种基于跨模态推理流程的多模态推理模型,将图像转化为形式化文本表示,实现精确的语言推理。他们构建了 R1-Onevision 数据集,涵盖多个领域的详细、分步推理标注,并通过监督微调与基于规则的强化学习训练模型,提升推理质量与泛化能力。此外,作者引入 R1-Onevision-Bench,一个与人类教育阶段对齐的综合性基准,支持跨学科与难度层级的推理性能评估。该方法在多个基准上取得最先进结果,超越 GPT-4o 和 Qwen2.5-VL 等模型。
数据集
- 数据集 R1-Onevision 用于通过监督微调(SFT)提升视觉语言模型的推理能力。
- 它支持结构化、一致的输出格式开发,促进大规模模型的高级推理能力,为后续强化学习奠定坚实基础。
- R1-Onevision-Bench 基准源自该数据集,涵盖五大核心领域:数学、生物、化学、物理和推理。
- 基准包含 38 个子类别,按五个难度等级组织:初中、高中、大学及社会测试,反映认知复杂度的逐步提升。
- 数据覆盖从中学到大学水平的真实世界推理任务,包含多种需深度思考与多模态理解的问题类型。
- 基准设计模拟人类教育发展过程,支持对模型在学术与实践推理领域表现的评估。
- 任务经过精心筛选,各类别与年级均提供示例,确保推理挑战的全面覆盖。
- 训练中使用 SFT 数据混合,模型在精选的高质量多模态问题与答案上进行微调。
- 未提及显式裁剪策略,但数据包含支持复杂推理的图像-文本对。
- 元数据围绕领域、子类别、难度等级与教育年级构建,支持细粒度评估与分析。
方法
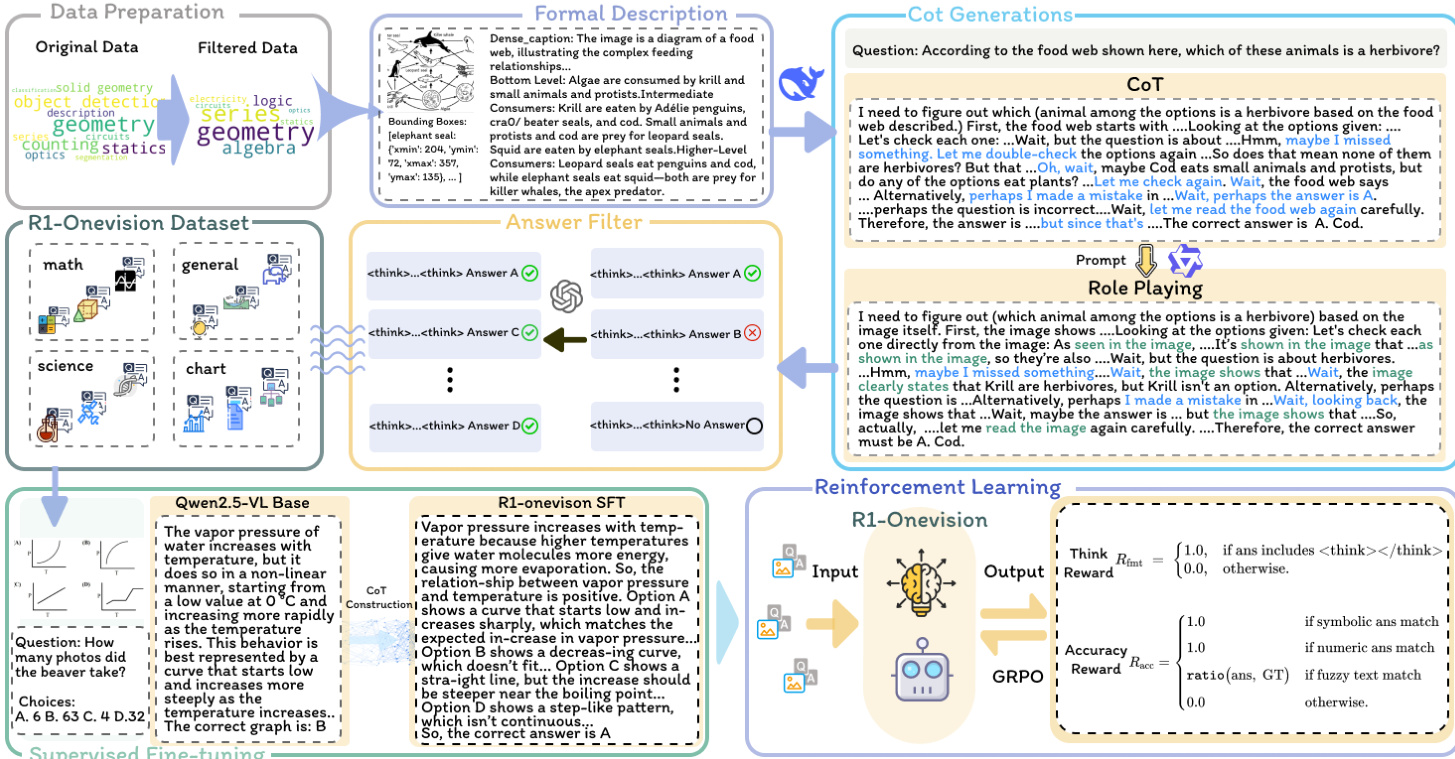
作者利用全面的跨模态推理流程,通过整合视觉形式化表示,弥合语言推理模型与视觉模型之间的差距。该流程旨在通过提供视觉内容的结构化、形式化描述,使语言模型能够基于图像元素进行推理。框架始于数据收集与筛选,整合涵盖自然图像、基于 OCR 的文本提取、图表、数学表达式与科学推理问题的多样化多模态数据集,仅保留支持结构化推理的数据。经筛选的数据通过 GPT-4o、Grounding DINO 与 EasyOCR 的组合处理,生成视觉内容的形式化描述。对于图表与示意图,GPT-4o 生成结构化表示,如电路图的 SPICE、流程图的 PlantUML 或 Mermaid.js、UI 布局的 HTML、表格的 CSV/JSON。自然场景通过 Grounding DINO 提取边界框标注,再由 GPT-4o 生成细粒度空间描述。纯文本图像则通过 EasyOCR 提取带位置信息的文本,再由 GPT-4o 重建原始文档。对于同时包含视觉与文本内容的图像,流程整合 GPT-4o 生成的描述、Grounding DINO 的边界框与 EasyOCR 提取的文本,确保双模态信息的完整捕获。数学图像则通过提示 GPT-4o 提出推理策略以引导推断。

流程进一步通过提示语言推理模型(具体为 DeepSeek R1)生成推理过程,输入为从形式化描述中提取的密集描述与问题。为克服传统思维链(CoT)方法缺乏直接视觉理解的局限,作者引入角色扮演策略,模拟人类式的视觉理解。该方法通过反复回看图像、细化理解并提升推理过程保真度,确保模型推理直接基于视觉输入,而非依赖文本描述。生成的推理过程随后进入质量保障环节,使用 GPT-4o 剔除不准确、无关或不一致的 CoT 步骤,确保多模态推理数据集的高质量。
最终生成的数据集 R1-Onevision 是一个精心构建的资源,旨在推动多模态推理的边界。其涵盖科学、数学、图表数据与一般现实场景等多个领域,总计超过 15.5 万条精心筛选的样本。该数据集为视觉推理模型的开发提供了丰富资源。
作者采用两阶段后训练策略以增强多模态推理能力。第一阶段为监督微调(SFT),用于稳定模型推理过程并标准化输出格式。第二阶段为基于规则的强化学习(RL),进一步提升在多样化多模态任务中的泛化能力。RL 阶段基于 SFT 训练的模型,采用基于规则的奖励机制优化结构化推理并确保输出有效性。定义了两项奖励规则:准确率奖励与格式奖励。准确率奖励通过正则表达式提取最终答案,并与真实答案比对,评估其正确性。对于数学等确定性任务,最终答案必须以指定格式(如框内)呈现,以支持可靠的规则验证。在目标检测等任务中,奖励由与真实答案的交并比(IoU)得分决定。格式奖励通过要求响应必须严格遵循格式:模型推理过程需被 </tool_call> 和 </tool_call> 标记包围,并通过正则表达式确保标记存在且顺序正确。
为实现一致策略更新与稳健奖励信号的平衡,作者采用分组相对策略优化(GRPO)。对于生成答案中的每个 token,GRPO 计算其在新策略(π(θ))与参考策略下的对数概率,再计算概率比并裁剪至区间 [1−ϵ,1+ϵ],防止更新幅度过大。归一化奖励作为优势项,用于 PPO 风格损失函数:
Lclip=−E[min(ratiot⋅Advt, clippedratiot⋅Advt)].其中,Advt 表示优势函数,衡量某一动作相较于基线策略值的优劣程度。为进一步保持与参考分布的接近性,引入 KL 散度惩罚项(权重为 β),得到整体损失:
LGRPO(θ)=−E[min(ratiot⋅Advt,clippedratiot⋅Advt)−β⋅KL(πθ(y∣x),πref(y∣x))].该组合确保模型在不损害训练稳定性的情况下高效整合基于规则的奖励。
实验
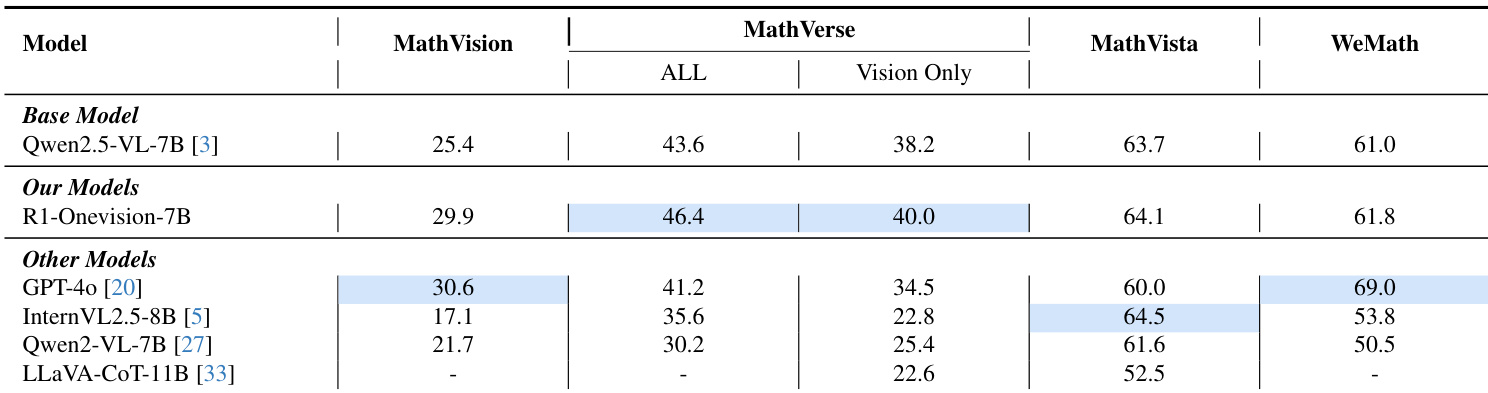
- 在 MathVista、MathVision、MathVerse 和 WeMath 基准上评估 R1-Onevision,展现出对最先进多模态模型的一致优势,尤其在细粒度视觉-文本对齐与思维链推理方面表现突出。
- 在 MathVision 上达到 29.9% 准确率,与 GPT-4o 相当,并在 MathVerse ALL 上超越 GPT-4o 5.2%、在 MathVerse Vision Only 上超越 5.5%、在 MathVista 上超越 4.1%,验证了其增强的推理能力。
- 在 R1-Onevision 基准上,Qwen2.5-VL-72B 平均准确率达 52%,与 Claude-3.5 持平,略低于 Gemini-2.0-Flash;而 R1-Onevision(3B)在 MathVision 上达 23.6%,在 MathVerse(ALL)上达 38.6%,即使在小模型上也表现出强劲性能。
- SFT 后接 RL 显著提升性能,RL 提供增量改进,证实两种训练策略在增强演绎推理方面的互补作用。
- 消融实验验证了方法在不同模型规模下的可扩展性,R1-Onevision(3B)相比基础模型有显著提升,表明其广泛适用性。
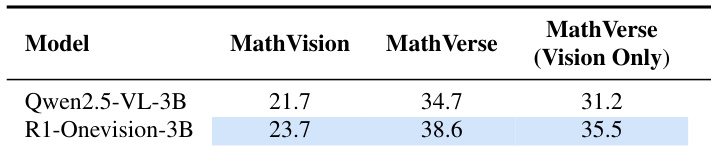
作者以 Qwen2.5-VL-3B 模型为基础,评估 R1-Onevision 方法的有效性。结果显示,R1-Onevision-3B 在所有三个基准上均优于基础模型,分别在 MathVision、MathVerse 和 MathVerse(Vision Only)上提升 2.0、3.9 和 4.3 个百分点。
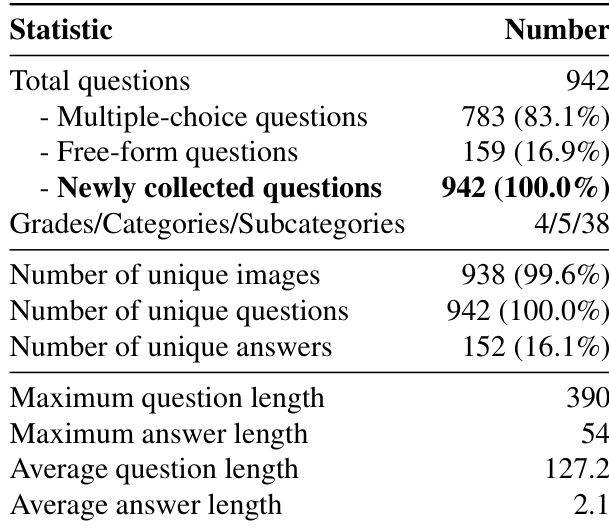
作者对 R1-Onevision 基准进行了全面分析,该基准共包含 942 道题目,包括 783 道选择题与 159 道开放题,均为新收集数据。基准按四个难度等级与五个学术类别组织,重点通过多样化的独特图像、问题与答案评估多模态推理能力。
作者使用标准生成焓表计算化学反应的标准焓变,应用公式 ΔH° = ΣΔH°f(产物) - ΣΔH°f(反应物)。模型正确识别相关数值,逐步完成计算,最终得出 -205.4 kJ·mol⁻¹ 的答案,与选项 A 一致。

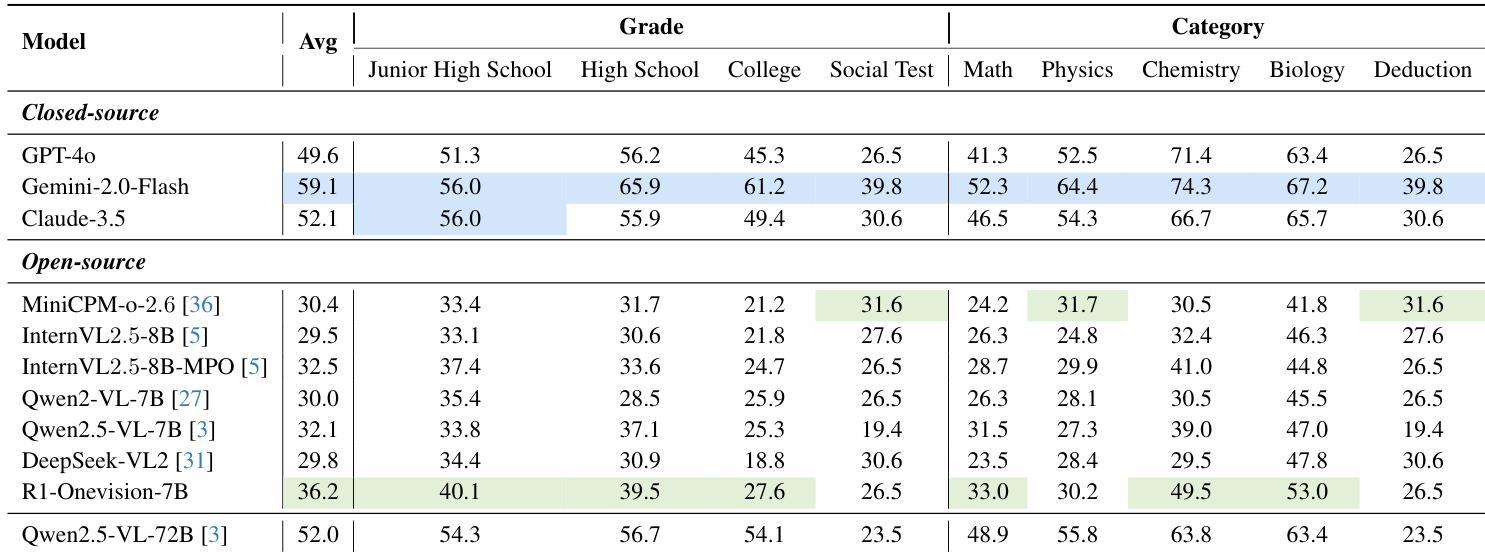
作者使用表 3 比较闭源与开源多模态模型在 R1-Onevision 基准上的表现,该基准按难度等级与学科领域分类。结果显示,闭源模型如 Gemini-2.0-Flash 达到最高平均准确率,超过 50%;而开源模型如 Qwen2.5-VL-72B 达到 52% 平均准确率,缩小了与顶级闭源模型的差距。
作者使用 R1-Onevision-7B 评估其在多个多模态推理基准上的性能,结果显示其在所有任务上均优于基础 Qwen2.5-VL-7B 模型。结果表明,R1-Onevision-7B 在 MathVision 上达到 29.9% 准确率,超过基础模型的 25.4%;在 MathVerse(ALL)上达 46.4%,在 MathVerse(Vision Only)上达 40.0%,显著提升了视觉-文本对齐与推理能力。