Command Palette
Search for a command to run...
YOLOE:实时感知任何事物
YOLOE:实时感知任何事物
Ao Wang Lihao Liu Hui Chen Zijia Lin Jungong Han Guiguang Ding
摘要
目标检测与分割在计算机视觉应用中被广泛使用,然而传统的模型(如YOLO系列)尽管在效率和准确性方面表现优异,却受限于预定义类别,难以适应开放场景下的动态变化。近年来,开放集检测方法通过引入文本提示、视觉提示或无提示范式,试图突破这一局限,但往往因计算开销大或部署复杂,导致性能与效率之间难以兼顾。针对这一问题,本文提出YOLOE,一种在单一高效模型中统一整合检测与分割能力,并支持多种开放提示机制的新方法,实现了真正的“实时看见任何事物”(seeing anything in real time)。针对文本提示,我们提出可重参数化区域-文本对齐(Re-parameterizable Region-Text Alignment, RepRTA)策略。该方法通过一个可重参数化的轻量级辅助网络对预训练文本嵌入进行精细化调整,并在推理阶段实现零开销的视觉-文本对齐,无需额外计算或参数迁移。针对视觉提示,我们设计了语义激活视觉提示编码器(Semantic-Activated Visual Prompt Encoder, SAVPE)。该结构采用解耦的语义分支与激活分支,有效提升视觉特征表达能力,在保持极低计算复杂度的前提下显著增强检测精度。在无提示场景下,我们提出懒惰区域提示对比(Lazy Region-Prompt Contrast, LRPC)策略。该方法利用模型内部构建的大词汇量及专用嵌入机制,实现对所有物体的自动识别,彻底摆脱对昂贵语言模型的依赖。大量实验表明,YOLOE在零样本迁移能力、泛化性能、推理效率和训练成本方面均表现出色。特别地,在LVIS数据集上,YOLOE-v8-S仅需YOLO-Worldv2-S约三分之一的训练成本,推理速度提升1.4倍,同时在平均精度(AP)上领先3.5个百分点。当迁移至COCO数据集时,YOLOE-v8-L在闭集模型YOLOv8-L的基础上分别实现了0.6 AP^b和0.4 AP^m的性能提升,且训练时间减少近4倍。相关代码与模型已开源,地址为:https://github.com/THU-MIG/yoloe。
一句话总结
清华大学的研究者提出 YOLOE,一种高效统一的开放集目标检测与分割模型,融合可重参数化区域-文本对齐(Re-parameterizable Region-Text Alignment)、语义激活视觉提示编码器(Semantic-Activated Visual Prompt Encoder)和懒惰区域-提示对比(Lazy Region-Prompt Contrast),在文本、视觉及无提示场景下均实现实时性能,且开销极小,零样本准确率与训练效率均优于现有方法。
主要贡献
- YOLOE 突破了封闭集目标检测与分割模型的局限性,实现了在多种开放提示机制(文本、视觉、无提示)下实时统一的检测与分割,且不牺牲效率或精度。
- 提出三个创新组件:RepRTA 通过可重参数化的轻量网络实现高效文本提示对齐;SAVPE 采用解耦的语义与激活分支,以低复杂度完成视觉提示编码;LRPC 利用内置大词汇量与专用嵌入实现无语言模型的提示自由检测。
- 大量实验表明,YOLOE 在 LVIS 和 COCO 数据集上达到最先进的零样本性能,相比 YOLO-Worldv2 和 YOLOv8,AP 提升最高达 3.5,推理速度提升 1.4 倍,训练时间减少 4 倍,同时保持极小的模型开销。
引言
研究者针对开放世界场景中对实时、灵活目标检测与分割日益增长的需求,提出模型需能响应多样提示(文本、视觉或无提示),而无需依赖预定义类别。尽管先前工作在开放词汇检测方面取得进展,但现有方案通常仅针对单一提示类型,导致效率低下:文本提示方法因跨模态融合带来高计算成本,视觉提示方法依赖重型 Transformer 或外部编码器,而无提示方法则依赖大型语言模型,增加延迟与内存占用。为此,研究者提出 YOLOE,一种统一且高效的模型,可在单一架构中支持全部三种提示类型。其核心创新包括:一个可重参数化的区域-文本对齐模块,以零推理开销提升文本提示性能;一个轻量级语义激活视觉提示编码器,以极低复杂度生成提示感知特征;以及一种懒惰区域-提示对比策略,实现无需语言模型的提示自由检测。结果表明,YOLOE 在所有提示类型下均达到最先进性能,同时显著降低训练成本与推理延迟——在边缘设备上相比 YOLO-Worldv2 和 T-Rex2,AP 提升最高达 3.5,推理速度提升 1.4 倍。
数据集
- YOLOE 训练所用数据集结合了 Objects365 与 GoldG(包含 GQA 和 Flickr30k),提供多样且大规模的图像数据,用于目标检测与分割任务。
- Objects365 提供通用物体实例,GoldG 通过 GQA 与 Flickr30k 的图像-标题对增强视觉-语言理解能力。
- 高质量分割掩码使用 SAM-2.1-Hiera-Large 生成,以真实边界框作为提示;面积不足的掩码被过滤以保证质量。
- 小掩码采用 3×3 高斯核进行平滑处理,大掩码则使用 7×7 核,以提升边缘连续性。
- 掩码优化采用先前工作的方法,通过迭代简化轮廓来减少噪声,同时保留整体形状与结构。
- 训练流程使用 AdamW 优化器,初始学习率为 0.002,批量大小为 128,权重衰减为 0.025。
- 数据增强包括颜色抖动、随机仿射变换、随机水平翻转和马赛克增强,以提升模型鲁棒性。
- 在迁移至 COCO 进行线性探测与全量微调时,使用相同的优化器与超参数,但学习率降低至 0.001。
方法
研究者采用统一的 YOLO 架构,整合在多种开放提示机制下的目标检测与分割任务。如框架图所示,模型首先通过主干网络处理输入图像,随后经 PAN(路径聚合网络)生成多尺度特征图(P3、P4、P5)。这些特征被送入三个并行分支:回归分支用于边界框预测,分割分支用于生成原型与掩码系数,嵌入分支用于生成物体嵌入。嵌入分支源自标准 YOLO 的分类头,其最终卷积层的输出通道数调整为匹配嵌入维度,而非封闭集场景中的类别数量。
对于文本提示,模型采用可重参数化区域-文本对齐(RepRTA)策略。该策略使用预训练文本编码器获取文本嵌入,并通过一个轻量级辅助网络在训练过程中进行优化。如图所示,该网络仅包含一个前馈块,旨在增强文本嵌入而几乎不引入计算开销。优化后的嵌入作为分类权重,与锚点处的物体嵌入进行对比以确定类别标签。该过程形式化为 Label=O⋅PT,其中 O 表示物体嵌入,P 表示提示嵌入。
对于视觉提示,模型引入语义激活视觉提示编码器(SAVPE)。该编码器包含两个解耦分支:语义分支与激活分支。语义分支处理 PAN 输出的多尺度特征,生成与提示无关的语义特征。激活分支如图所示,接收视觉提示(如掩码)与图像特征,经卷积处理后输出提示感知权重。这些权重用于调制语义特征,其聚合结果即为最终的视觉提示嵌入。该设计实现了对视觉线索的高效处理,且复杂度极低。
在无提示场景中,模型采用懒惰区域-提示对比(LRPC)策略。该方法将任务重构为检索问题:训练一个专用提示嵌入以识别对应物体的锚点。仅对这些识别出的锚点与内置大词汇表进行匹配,以检索类别名称,从而跳过对无关点的昂贵计算。该懒惰检索机制确保高效率而不牺牲性能。整体框架设计支持三种提示类型于单一高效模型中,实现各类开放集场景下的实时性能。
实验
- YOLOE 在 LVIS 上验证了卓越的零样本检测与分割性能,YOLOE-v8-L 达到 33.0% AP,相比 YOLOv8-Worldv2 在各尺度上提升 3.5–0.4 AP,T4 与 iPhone 12 上推理速度提升 1.2–1.6 倍。
- YOLOE-v8-M / L 在零样本分割中分别达到 20.8 / 23.5 AP^m,超越微调后的 YOLO-Worldv2-M / L 3.0 / 3.7 AP^m,证明其在无 LVIS 数据下仍具备强大泛化能力。
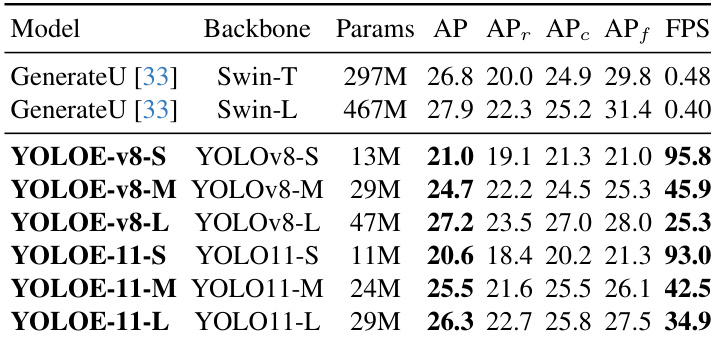
- 在无提示评估中,YOLOE-v8-L 达到 27.2 AP 与 23.5 AP_r,相比 GenerateU + Swin-T 提升 0.4 AP 与 3.5 AP_r,同时参数量减少 6.3 倍,推理速度提升 53 倍。
- YOLOE 在 COCO 上表现出强迁移能力:训练时间不足 2% 时,YOLOE-11-M / L 在线性探测中达到 YOLO11-M / L 性能的 80% 以上;训练时间仅为 3 倍时,YOLOE-v8-S 在检测与分割任务上均优于 YOLOv8-S。
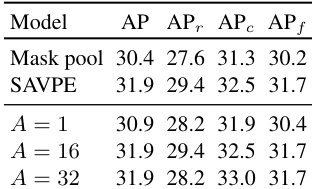
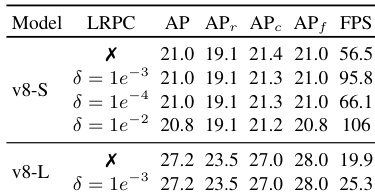
- 消融实验验证了 SAVPE 的有效性(相比掩码池化提升 1.5 AP)与 LRPC 的高效性(速度提升 1.7 倍,AP 下降极小),多任务学习虽带来轻微检测性能损失,但实现了分割能力。
- 零样本、文本提示、视觉提示与无提示设置下的可视化结果展示了 YOLOE 在多样化真实场景中的鲁棒性与通用性。
研究者通过多数据集评估,验证了 YOLOE 在检测与分割任务中的能力,表明其可在不同数据集上同时支持边界框与掩码输出。结果表明,YOLOE 能有效处理多样数据类型,包括检测与定位任务,适应不同图像与标注数量。

研究者通过调整激活分支中的组数来评估 SAVPE 的有效性,结果显示性能在不同组数下保持稳定。具体而言,组数从 1 增至 16 时,AP 有微小提升,当 A = 16 时达到 31.9 AP,表明性能与复杂度之间取得良好平衡。
结果表明,YOLOE-v8-S 达到 21.0 AP 与 95.8 FPS,相比 GenerateU-Swin-T 在 AP 上表现更优,同时参数量显著减少,推理速度大幅提升。YOLOE-11-L 达到 26.3 AP 与 34.9 FPS,展现出更强性能,且相比 YOLOE-v8-L 使用更高效的主干网络。
结果表明,引入 LRPC 显著提升推理速度而未牺牲性能:YOLOE-v8-S 与 YOLOE-v8-L 在 T4 与 iPhone 12 上分别实现 1.7× 与 1.3× 速度提升,同时保持相近的 AP 与 APf 值。LRPC 的有效性进一步通过随阈值 δ 增大而显著减少保留锚点数量得到验证,从而降低计算开销。
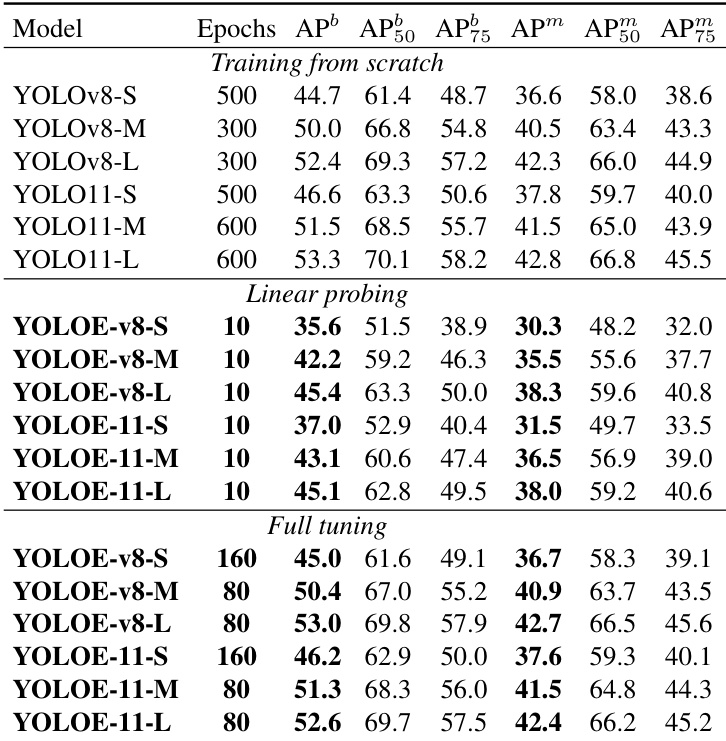
研究者使用表格对比 YOLOE 模型在不同训练策略(从头训练、线性探测、全量微调)下与 YOLOv8 和 YOLO11 的性能。结果表明,YOLOE 在所有设置下均达到竞争性或更优表现,YOLOE-v8-L 与 YOLOE-11-L 在全量微调中取得最高 AP 与 APm 值,同时相比 YOLOv8 与 YOLO11 模型展现出显著的推理加速优势。