Command Palette
Search for a command to run...
ROCKET-2:通过跨视角目标对齐引导视觉-运动策略
ROCKET-2:通过跨视角目标对齐引导视觉-运动策略
Cai Shaofei Mu Zhancun Liu Anji Liang Yitao
摘要
我们旨在开发一种语义清晰、空间敏感、领域无关且对人类用户直观的目标指定方法,以指导智能体在三维环境中的交互行为。具体而言,本文提出一种新颖的跨视角目标对齐框架,允许用户通过自身摄像头视角中的分割掩码来指定目标物体,而非依赖智能体自身的观测结果。我们指出,当人类与智能体的摄像头视角存在显著差异时,仅依靠行为克隆(behavior cloning)无法有效对齐智能体行为与人类意图。为解决这一问题,我们引入两项辅助目标:跨视角一致性损失(cross-view consistency loss)与目标可见性损失(target visibility loss),以显式增强智能体的空间推理能力。基于此,我们构建了ROCKET-2——一种在Minecraft环境中训练的先进智能体,其推理效率相较ROCKET-1提升了3至6倍。实验表明,ROCKET-2能够直接理解来自人类摄像头视角的目标指令,显著提升了人机交互效果。尤为突出的是,ROCKET-2展现出零样本泛化能力:尽管仅在Minecraft数据集上进行训练,但通过简单的动作空间映射,即可成功适应并泛化至其他三维环境,如Doom、DMLab和Unreal。
一句话总结
北京大学与加州大学洛杉矶分校联合CraftJarvis团队提出ROCKET-2,一种视觉运动策略,使人类代理可通过自身摄像头视角的分割掩码指定目标,将目标输入与代理视角解耦。通过引入跨视角一致性损失和目标可见性损失,该模型实现了稳健的空间推理,推理速度比ROCKET-1快3至6倍,无需实时分割。值得注意的是,ROCKET-2在Doom、DMLab和Unreal Engine等多样化的3D环境中展现出零样本泛化能力,彰显其作为具身人工智能通用决策代理的巨大潜力。
主要贡献
- 本文提出一种新颖的跨视角目标对齐框架,使人类用户能够通过自身摄像头视角的分割掩码在3D环境中指定目标对象,将目标指定与代理视角解耦,从而提升人机交互的直观性与灵活性。
- 为克服部分可观测性与视角差异的挑战,作者提出两种辅助损失——跨视角一致性损失与目标可见性损失——使ROCKET-2能够自主在不同摄像头视角间追踪目标,无需实时分割,推理速度相比ROCKET-1提升3至6倍。
- ROCKET-2展现出强大的零样本泛化能力,尽管仅在Minecraft数据上训练,仍能通过简单的动作空间映射成功适应Doom、DMLab和Unreal等多样化3D环境,凸显所提跨视角对齐方法的领域无关特性。
引言
作者致力于解决在部分可观测3D环境中实现直观、高效人机交互的挑战,传统目标指定方法(如语言或代理中心视觉线索)在空间模糊性、实时性约束和泛化能力方面存在局限。先前依赖代理视角分割或轨迹草图的方法在目标被遮挡或人类与代理视角差异较大时失效,限制了可扩展性与鲁棒性。为此,作者提出ROCKET-2,一种通过目标条件模仿学习训练的视觉运动策略,结合新颖的跨视角目标对齐框架。其核心创新在于允许人类使用自身摄像头视角的分割掩码指定目标,而代理则学习将这些目标与自身第一人称观测对齐。这一能力由两种辅助损失实现:跨视角一致性损失,用于在不同视角间精确预测目标中心;目标可见性损失,用于检测遮挡。结果,ROCKET-2在推理阶段无需实时分割,推理速度比ROCKET-1快3至6倍。尤为突出的是,尽管仅在Minecraft数据上训练,ROCKET-2仍通过简单的动作空间映射在Doom、DMLab和Unreal Engine等多样化3D环境中实现零样本泛化,凸显其领域无关设计与可扩展、通用策略学习的潜力。
数据集
- 数据集包含来自Minecraft的16亿帧人类游戏数据,由OpenAI(Baker et al., 2022)收集,涵盖精细的交互事件,如挖掘、制作、物品使用和战斗。
- 每个交互事件均标注帧级对象掩码,标识参与的目标实体,确保同一事件的所有掩码对应同一对象。
- 训练时,每个交互事件中随机选取一帧带掩码的图像作为跨视角目标指定,使模型学习其当前第一人称视角与来自其他视角的高层目标之间的对齐。
- 使用的交互类型——使用、破坏、接近、制作、击杀实体——遵循ROCKET-1的分类体系,覆盖广泛的任务结构与物体功能。
- 数据集支持在多样化技能上训练ROCKET-2,包括战斗、末影之门发现、桥梁建造、矿石挖掘和制作,通过跨视角输入中的掩码与圆形区域增强视觉目标理解。
- 训练过程中,模型利用这些交互类型及其关联掩码帧的混合,发展出稳健的3D视觉目标对齐与动作预测能力。
方法
作者采用多阶段架构,解决具身环境中跨视角目标指定的挑战,使视觉运动策略能够解析来自任意摄像头视角的人类提供的分割掩码。整体框架如图所示,通过一系列空间与时间模块处理代理当前观测与跨视角目标条件,生成动作、目标中心点与可见性预测。
方法首先对视觉输入进行编码。对于每帧 ot,使用DINO预训练的ViT-B/16编码器处理RGB图像,生成196个token序列 {o^ti}i=1196。同时,分割掩码 mt 由可训练的ViT-tiny/16编码,生成对应token序列 {m^ti}i=1196。跨视角条件 (og,mg) 通过拼接对应视觉与掩码token的特征通道进行融合,再经前馈网络生成融合条件表示 hgi。
请参考框架图理解空间融合过程。当前观测的token序列与融合后的跨视角条件序列拼接为长度为392的单一序列。应用非因果Transformer编码器对该序列进行空间融合,生成帧级表示 xt。此步骤使模型能够将代理视角的视觉特征与人类目标视角的语义信息对齐,利用自注意力机制捕捉两视角间的空间关系。
为捕捉时间依赖性,将帧级表示 xt 输入因果TransformerXL架构。该模块处理表示序列 {xi}i=1t 与交互事件 cg,生成时间上下文 ft。该Transformer的因果特性确保时间 t 时策略决策仅基于过去与当前观测,这对实时控制至关重要。时间上下文 ft 随后输入轻量网络,预测动作 a^t、目标物体中心 p^t 与目标物体可见性 v^t。模型通过最小化这些预测的交叉熵损失进行训练,该损失包含动作的行为克隆损失以及中心点与可见性预测的辅助损失。
实验
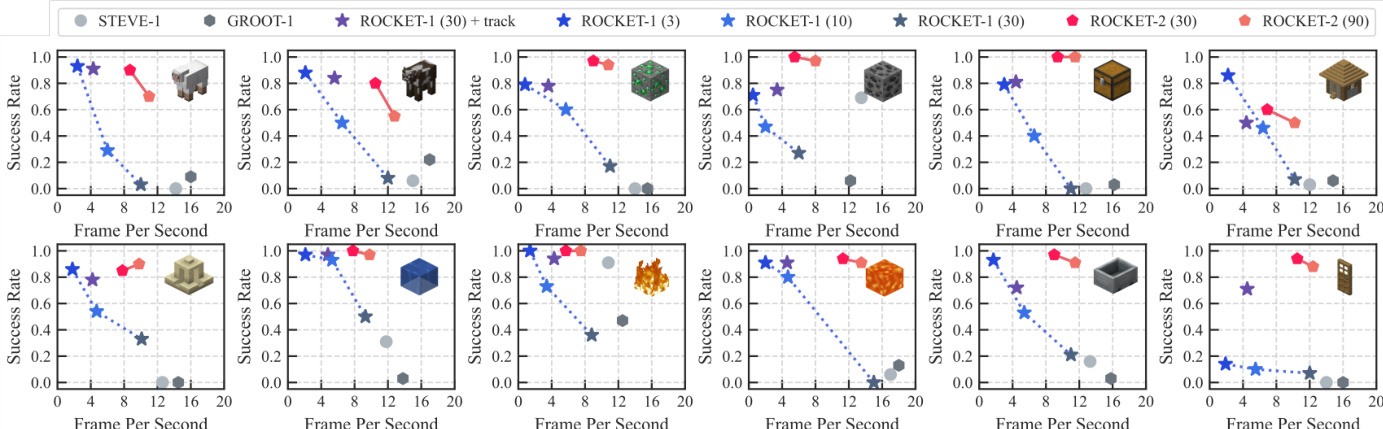
- ROCKET-2在Minecraft交互基准测试中推理速度比ROCKET-1快3至6倍,多数任务上达到或超越其峰值性能,关键交互任务(如Hunt、Mine、Navigate)成功率超过90%。
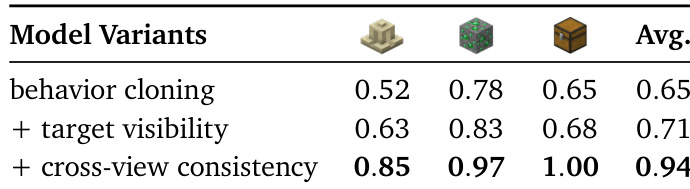
- 在Minecraft交互基准测试中,ROCKET-2在使用全部辅助损失(行为克隆 + 目标可见性 + 跨视角一致性)时达到94%的平均成功率,显著优于仅行为克隆的变体(65%),凸显基于视觉的辅助目标的关键作用。
- ROCKET-2在未见3D环境(Unreal Engine)中展现出零样本泛化能力,在ATEC 2025机器人挑战赛中成功率达38%,比强基线高出12%,尽管未进行微调且观测分辨率不同(640×480 vs. 640×360)。
- 跨回合跨视角目标对齐使ROCKET-2能够解析来自不同回合与生物群系的目标指定,即使无视觉地标重叠,仍能成功推断语义意图(如建造桥梁或寻找房屋)。
- 地标注意力可视化证实ROCKET-2隐式学习了空间对齐能力,能有效匹配视角间非目标地标,即使在几何形变与距离变化下仍保持一致,表明其具备稳健的跨视角感知能力。
- ROCKET-2通过基于规则的动作映射,在多样化3D环境(Unreal Engine、Doom、DeepMind Lab、Steam游戏)中表现出强泛化能力,无需环境特定适配即可完成复杂任务,如击败末影龙与建造桥梁。
作者使用Minecraft交互基准评估代理在六类任务中的表现,以成功率与推理速度为指标。结果表明,ROCKET-2在显著更高的帧率下实现与ROCKET-1相当或更优的成功率,展示出3至6倍的推理速度提升,且未牺牲任务性能。
作者通过消融实验评估辅助目标对模型性能的影响,比较三种变体:仅行为克隆、行为克隆+目标可见性损失、完整模型(含跨视角一致性损失)。结果表明,加入目标可见性损失使平均成功率提升6%,而引入跨视角一致性损失进一步提升至94%,证明这些辅助损失在增强跨视角目标对齐方面的有效性。
作者使用ATEC 2025机器人挑战赛评估ROCKET-2在未见Unreal Engine环境中的零样本泛化能力,其在未微调情况下仍比强基线高出12%。结果表明,ROCKET-2成功率达38%,在57个代理中排名第一,而YOLO-Gemma 3基线成功率为26%,排名20。

作者采用ViT-base/16(DINO-v1)作为视图编码器骨干网络,ViT-tiny/16(1通道)作为掩码编码器骨干网络,使用PyTorch Transformer作为空间变换器,TransformerXL用于时间建模。模型使用AdamW优化器,学习率为0.00004,采用128步轨迹块,配置4个空间与时间Transformer块。
结果表明,ROCKET-2在保持与ROCKET-1相当或更优性能的同时,显著提升推理速度,因其将目标指定与代理当前视角解耦,并采用跨视角分割,每60步仅更新一次第三人称视角。该设计使推理速度比依赖每3至30步频繁生成掩码的ROCKET-1快3至6倍。
