Command Palette
Search for a command to run...
UniDepthV2:更简单的通用单目度量深度估计
UniDepthV2:更简单的通用单目度量深度估计
Luigi Piccinelli Christos Sakaridis Yung-Hsu Yang Mattia Segu Siyuan Li Wim Abbeloos Luc Van Gool
摘要
准确的单目度量深度估计(Monocular Metric Depth Estimation, MMDE)对于解决三维感知与建模中的下游任务至关重要。然而,近期MMDE方法所展现出的卓越精度仅局限于其训练数据分布范围内。即便面对适度的域间差异,这些方法也难以实现有效泛化,严重制约了其实际应用潜力。为此,本文提出一种新型模型UniDepthV2,能够仅凭单张图像,在跨域场景下重建具有度量意义的三维场景。与现有MMDE范式不同,UniDepthV2在推理阶段直接从输入图像中预测具有度量意义的三维点,无需任何额外信息,致力于实现通用且灵活的MMDE解决方案。具体而言,UniDepthV2引入了一个自提示可调的相机模块,用于预测稠密的相机表征,以条件化深度特征。同时,该模型采用伪球面输出表示结构,有效解耦相机与深度特征的表示关系。此外,本文提出一种几何不变性损失(geometric invariance loss),以增强相机提示后深度特征的不变性。相较于前代模型UniDepth,UniDepthV2通过引入一种新的边缘引导损失(edge-guided loss),显著提升了度量深度输出中边缘的定位精度与清晰度;同时对网络架构进行了重新设计,使其更加简洁、高效;并新增不确定性输出层,为需要置信度信息的下游任务提供支持。在十个深度估计数据集上的零样本(zero-shot)评估结果一致表明,UniDepthV2在性能与跨域泛化能力方面均显著优于现有方法。相关代码与模型已开源,地址为:https://github.com/lpiccinelli-eth/UniDepth
一句话总结
来自苏黎世联邦理工学院、马克斯·普朗克苏黎世联邦理工学院学习系统中心以及丰田欧洲公司的作者提出 UniDepthV2,一种通用的单目度量深度估计模型,能够直接从单张图像预测度量3D点,而无需在推理时依赖相机参数。该模型引入了自提示相机模块和伪球面输出表示,以解耦相机与深度优化,从而在多种领域中实现稳健的泛化能力。新颖的边缘引导损失提升了深度的锐度和边缘定位精度,几何不变性损失则增强了在几何增强下的一致性。该架构相较于前代模型更为简化且高效,在十个数据集的零样本设置下达到最先进性能,适用于机器人、自动驾驶和三维建模等领域。
主要贡献
-
UniDepthV2 通过实现无需依赖外部相机参数或领域特定训练的单图像通用深度预测,解决了可泛化单目度量深度估计(MMDE)这一关键挑战,从而克服了先前方法在未见场景和相机设置下的泛化能力差的问题。
-
模型引入了具有伪球面输出表示的自提示相机模块,解耦了相机与深度维度,并结合几何不变性损失,强制在不同视图增强下保持一致性,提升了鲁棒性,使在多样化环境中实现精确的度量3D重建成为可能。
-
UniDepthV2 通过新颖的边缘引导损失提升了深度精度和边缘锐度,并引入像素级不确定性输出,在十个多样化数据集上实现了最先进零样本性能,同时保持了简化且高效的架构。
引言
单目度量深度估计(MMDE)在机器人、自动驾驶和三维建模中的三维感知中至关重要,但先前的方法由于在训练中依赖特定相机内参和场景尺度,难以在不同领域间实现泛化。现有方法在真实、非受控环境中常因相机参数和场景几何显著变化而失效,且受限于噪声大、稀疏的真值深度数据,导致预测结果模糊且不准确。作者提出 UniDepthV2,一种通用的 MMDE 框架,能够从单张图像预测度量3D点,而无需任何外部信息(如相机参数)。其核心创新在于一个自提示相机模块,可生成密集的非参数化相机表示,结合伪球面输出空间,解耦相机与深度优化。该设计,连同几何不变性损失和新颖的边缘引导损失,实现了更锐利的深度预测和在多样化领域中的稳健泛化。UniDepthV2 还引入了像素级不确定性输出,用于支持置信度感知的下游任务,并在十个数据集的零样本评估中达到最先进性能,包括 KITTI 基准。
数据集
-
数据集包含 23 个公开来源,总计 1600 万张图像,用于训练 UniDepthV2。这些数据集包括 A2D2、Argoverse2、ARKit-Scenes、BEDLAM、BlendedMVS、DL3DV、DrivingStereo、DynamicReplica、EDEN、HOI4D、HM3D、Matterport3D、Mapillary-PSD、MatrixCity、MegaDepth、Ni-anticMapFree、PointOdyssey、ScanNet、ScanNet++、TartanAir、Taskonomy、Waymo 和 WildRGBD。
-
每个数据集根据其场景数量贡献训练样本,训练采样按场景数量加权。数据经过几何和光度增强:随机缩放、裁剪、平移、亮度、伽马、饱和度和色相偏移。每批次图像的宽高比在 2:1 到 1:2 之间随机采样。
-
模型使用所有 23 个数据集的加权混合进行训练,评估时不应用测试时增强。训练流程采用从 DINO 预训练权重初始化的 ViT 主干网络,使用 AdamW(β₁ = 0.9,β₂ = 0.999),初始学习率为 5×10⁻⁵,权重衰减为 0.1,采用余弦退火调度。训练运行 300k 次迭代,使用 16 块 NVIDIA 4090 GPU,半精度训练,耗时约 6 天。
-
训练了三种模型变体——UniDepthV2-Small、-Base 和 -Large,分别使用不同的 ViT 主干网络。消融研究使用较短的 100k 步调度,仅使用 ViT-S 主干,因此消融最终模型与主 UniDepthV2-Small 结果不可直接比较。
-
评估时,模型在十个未见数据集上以零样本方式测试,分为三个领域:室内(SUN-RGBD、IBims、TUM-RGBD)、室外(ETH3D、Sintel、DDAD、NuScenes)和挑战性场景(HAMMER、Booster、FLSea)。使用 δ₁^SSI(深度精度)、F_A(1/20 最大深度范围内的 F1-AUC)和 ρ_A(15° 以内角度误差的 AUC)进行评估,未在 KITTI 或 NYU-Depth V2 上进行微调。
-
置信度预测通过 AUSE 和 nAUSE(归一化 AUSE)评估,用于衡量在渐进遮蔽下不确定性排序质量,通过 Spearman’s ρ 评估预测不确定性与真实误差之间的单调性。这些指标在不假设相机参数分布的前提下计算,确保在多样化相机模型和未校正图像中的一致性。
-
最终模型还通过在 KITTI 和 NYU-Depth V2 上微调后评估其域内性能,符合标准实践。
方法
作者采用模块化架构设计 UniDepthV2,旨在从单张单目图像中联合估计深度和相机内参,而无需依赖外部标定信息。该框架如图所示,由编码器主干、相机模块和深度模块组成。编码器基于视觉 Transformer(ViT),处理输入图像生成多尺度特征图 Fi∈Rh×w×C,供相机和深度模块使用。相机模块从 ViT 主干的类别令牌初始化,通过自注意力层处理这些令牌,预测针孔相机的内参,即焦距 fx,fy 和主点 cx,cy。这些参数用于计算相机射线,随后归一化至单位球面,并转换为密集的角表示 C。该表示通过正弦编码进一步嵌入,生成相机嵌入 E,作为深度模块的提示。深度模块通过在编码器特征 Fi 与相机嵌入 E 之间应用交叉注意力机制,基于这些嵌入进行条件化处理,生成相机提示的深度特征 Fi∣E。这些条件化特征随后由类似特征金字塔网络(FPN)的解码器处理,生成对数深度预测 Zlog,并上采样至原始图像分辨率。最终的 3D 输出 O 由预测的相机射线 C 和深度值 Z 拼接而成,其中 Z 为 Zlog 的逐元素指数运算结果。
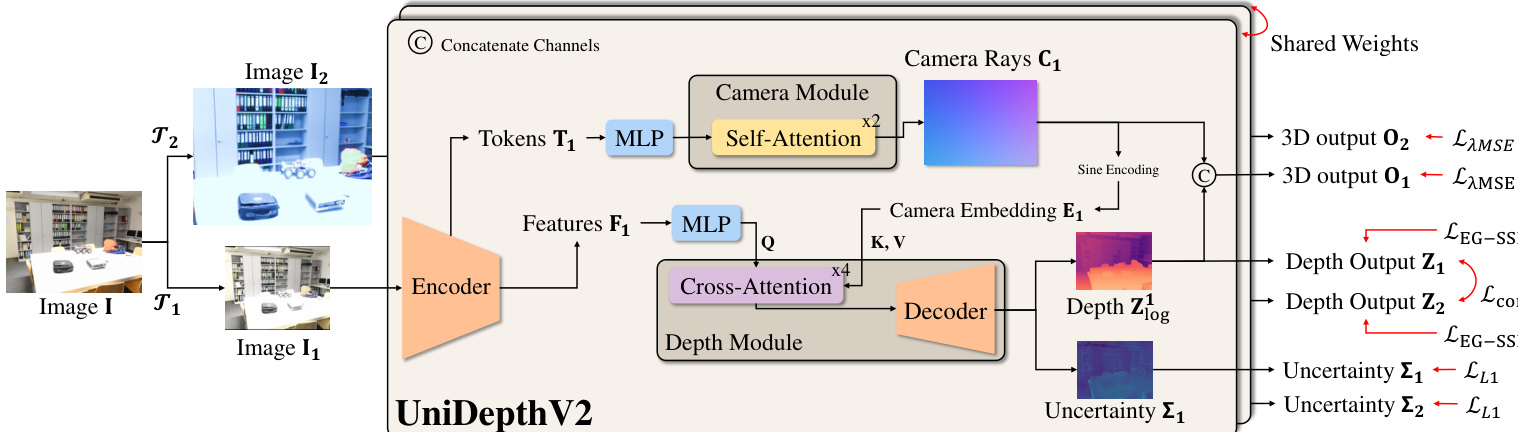
模型的输出空间由伪球面表示 (θ,ϕ,zlog) 定义,该表示将相机的角信息(方位角 θ 和仰角 ϕ)与深度信息(zlog)解耦。如框架图所示,这种设计确保相机与深度分量在设计上正交,与笛卡尔坐标 (x,y,z) 的纠缠特性形成对比。该空间中的反投影操作涉及拼接相机与深度表示,而非笛卡尔空间中齐次射线与深度的乘法。相机模块的输出为密集张量 C∈RH×W×2,表示每个像素的方位角和仰角,随后嵌入形成条件提示 E。
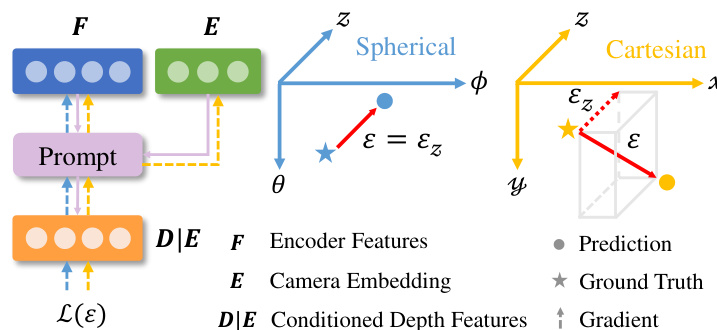
为确保深度预测的鲁棒性和一致性,作者引入几何不变性损失。该损失强制在输入图像进行几何增强(如缩放和平移)时,深度特征保持一致,模拟从不同相机观察同一场景的情形。该损失在两个增强视图的相机感知深度输出 Z1 和 Z2 上计算,形式为一个视图的变换深度图与另一视图的停止梯度版本之间的双向 L1 距离。该机制促使模型学习对特定相机参数不变的深度预测,从而提升泛化能力。此外,采用一种边缘引导的归一化损失(LEG-SSI)以提高局部几何精度。该损失聚焦于图像中高对比度区域,这些区域很可能存在深度不连续,对预测和真值深度图在这些补丁内进行局部归一化。该归一化使损失对深度尺度和偏移变化具有鲁棒性,确保模型能区分真实的几何边缘与虚假的纹理变化。整体优化由在伪球面输出空间中重新表述的均方误差(MSE)损失引导,该损失包含深度维度的尺度和偏移不变性项,并结合几何不变性损失、边缘引导损失和不确定性预测损失。
实验
- 在涵盖室内、室外和挑战性领域(水下、透明物体)的十个零样本验证集上评估,UniDepthV2 超过或匹配所有基线方法,包括需要真值相机参数的方法,在 F_A 上相比第二佳方法最高提升 18.1%。
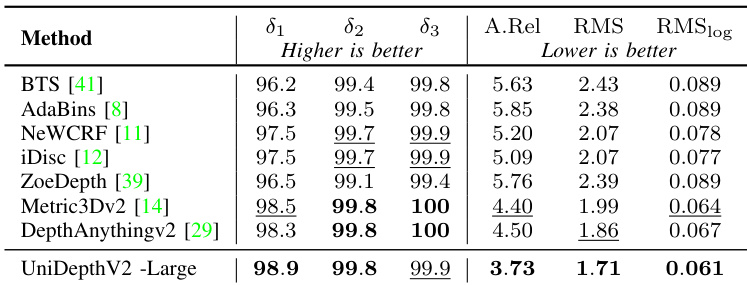
- 在 NYU 和 KITTI 基准上,UniDepthV2 展现出强大的微调性能,当适配至特定领域时,超越在大规模多样化数据集上预训练的模型,尤其在室外场景(KITTI)中表现突出。
- 在 ETH3D、IBims-1 和 Sintel 上实现最先进边缘检测 F_1,即使在固定高分辨率的严格评估条件下仍保持竞争力。
- UniDepthV2 在推理效率方面属于最快模型之一,在高达约 200 万像素的分辨率下,速度比基线快至 2 倍,同时内存使用量相当,尽管增加了相机预测模块。
- 消融研究显示,架构改进——移除球谐编码和注意力机制、用 ResNet 块替换 MLP 解码器、增加多分辨率特征融合——使计算量减少三分之二,同时保持性能。
- 所提出的 LEG−SSI 损失使 δ1 提升 4.7%,F_A 提升 1.8%,增强了深度精度和 3D 估计,间接提升了相机参数估计效果。
- 在多个解码器尺度上应用相机条件化比单点条件化性能更优,且在输出空间(Z)中应用几何一致性损失已足够且更简单。
- UniDepthV2 中的伪球面输出表示相比笛卡尔回归在深度、3D 和相机精度上均有提升。
- 不同域内的不确定性估计校准良好(nAUSE: 0.199–0.221,ρ: 0.68–0.74),但在零样本条件下退化(nAUSE: 0.54–0.65,ρ: 0.29),表明在新领域中预测具有信息量但可靠性较低。
- 失败案例包括非针孔相机、镜子、光学错觉和扭曲画作;UniDepthV2 无法校正非针孔畸变,因其基于针孔相机表示,且在模糊镜像解释上存在困难。
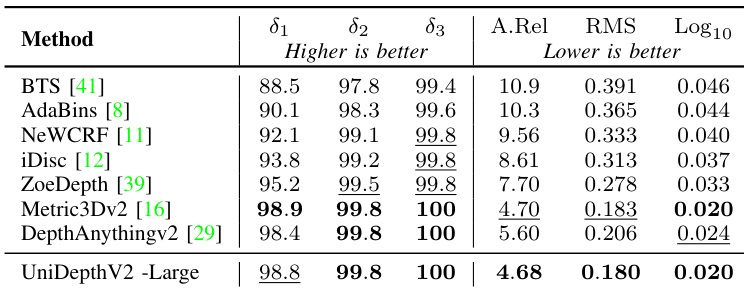
结果表明,UniDepthV2 -Large 在所有指标上均优于其他方法,δ₁、δ₂、δ₃ 和 A.Rel 得分最高,同时 RMS 和 RMSlog 错误最低。该模型超越所有基线方法,包括需要真值相机参数的方法,证明了其在零样本深度估计中的有效性。
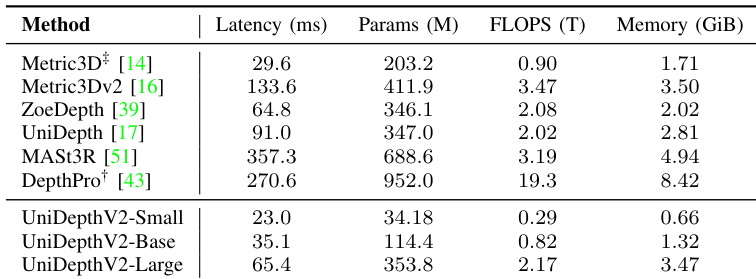
作者将 UniDepthV2 各变体与多种最先进方法的推理效率进行比较,结果显示 UniDepthV2-Small 在保持竞争性参数量和 FLOPS 的同时,实现了最低延迟和内存使用。尽管 UniDepthV2-Large 计算需求更高,但仍保持高效,在速度和内存占用方面优于大多数基线。
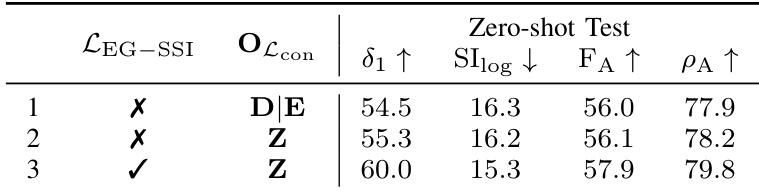
结果表明,添加 LEG−SSI 损失并在输出空间(Z)中应用一致性损失,显著提升了深度精度和 3D 估计,当两个组件同时使用时性能最佳。该组合相比基线使 δ1 提升 5.5%,F_A 提升 1.9%。
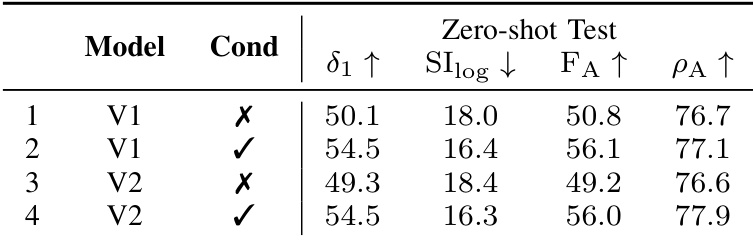
作者通过受控消融研究评估相机条件化和模型版本对深度估计性能的影响。结果表明,引入相机条件化显著提升了所有指标,最佳性能由带条件化的 UniDepthV2 实现,其在 δ₁、F_A 和 ρ_A 上均达到最高值。
结果表明,UniDepthV2 -Large 在所有指标上均表现最佳,在零样本验证集上超越或匹配所有基线。其在 δ₁、δ₂、δ₃ 和 Log10 上得分最高,同时在 A.Rel、RMS 和 Log10 上达到最低值,表明其具有卓越的深度精度和尺度不变性能。