Command Palette
Search for a command to run...
MegaTTS 3:稀疏对齐增强的潜在扩散Transformer用于零样本语音合成
MegaTTS 3:稀疏对齐增强的潜在扩散Transformer用于零样本语音合成
摘要
尽管近期的零样本文本到语音(Zero-shot Text-to-Speech, TTS)模型在语音质量与表现力方面取得了显著进步,主流系统在语音-文本对齐建模方面仍存在若干问题:1)缺乏显式语音-文本对齐建模的模型在实际应用中对复杂句式表现鲁棒性较差;2)基于预设对齐的模型受限于强制对齐带来的自然度瓶颈。本文提出了一种名为 MegaTTS 3 的新型TTS系统,其核心创新在于引入了一种稀疏对齐算法,用于引导潜在扩散Transformer(Latent Diffusion Transformer, DiT)。具体而言,我们为MegaTTS 3提供稀疏的对齐边界信息,以降低对齐建模的难度,同时不压缩搜索空间,从而在保持高自然度的同时实现精准对齐。此外,系统采用多条件无分类器引导(multi-condition classifier-free guidance)策略,实现对口音强度的灵活调节,并结合分段修正流(piecewise rectified flow)技术,显著加速语音生成过程。实验结果表明,MegaTTS 3在零样本TTS任务中达到了当前最优的语音质量,并支持对口音强度的高自由度控制。尤为突出的是,该系统仅需8次采样步即可生成高质量的一分钟语音。音频样例可访问:https://sditdemo.github.io/sditdemo/。
一句话总结
浙江大学、字节跳动和内蒙古大学的季子悦等人提出 MegaTTS 3,一种基于稀疏对齐算法引导潜在扩散 Transformer 的零样本语音合成系统,能够在不牺牲自然度的前提下实现鲁棒的语音-文本对齐;同时,多条件无分类器引导与分段修正流技术实现了细粒度口音控制和超快生成速度——仅用 8 步即可生成高质量的一分钟语音。
主要贡献
-
MegaTTS 3 通过引入稀疏对齐算法,解决了现有零样本语音合成模型的局限性,该算法为潜在扩散 Transformer 提供粗粒度对齐边界,提升了对复杂句子的鲁棒性,降低了对齐学习难度,同时未限制模型的搜索空间。
-
系统采用多条件无分类器引导策略,实现了对说话人音色与文本内容的细粒度独立控制,其中文本引导尺度还可灵活调节口音强度,增强表达力。
-
通过集成分段修正流技术,MegaTTS 3 将推理速度提升至仅需 8 次采样步骤,同时保持了最先进的语音质量与自然度,以极低的计算成本实现了高保真的一分钟语音合成。
引言
作者利用潜在扩散模型与神经编解码语言模型的最新进展,应对零样本语音合成(TTS)中的关键挑战:系统需在未接触目标说话人的情况下,仅凭短音频提示生成自然且富有表现力的语音。以往工作面临根本性权衡:依赖注意力机制隐式对齐的模型缺乏鲁棒性,且生成速度慢;而使用预定义强制对齐的模型则因限制模型搜索空间而牺牲自然度与灵活性。为克服这些局限,作者提出 MegaTTS 3,一种基于稀疏对齐增强的潜在扩散 Transformer,将强制对齐生成的粗粒度对齐边界注入潜在序列,使模型能高效学习细粒度对齐,同时不抑制其表达能力。该设计提升了对时长误差的鲁棒性,并借助分段修正流技术,仅用 8 次采样步骤即可实现高质量合成。此外,作者提出多条件无分类器引导策略,实现对说话人音色与文本内容的独立控制,文本引导尺度还可灵活调节口音强度——无需成对口音标注。该方法在语音质量、可懂度与表现力方面达到最先进水平,同时实现了高效、可控的零样本 TTS。
数据集
- MegaTTS 3 的数据集由两大部分组成:大规模无标签训练语料库与多个基准测试集。
- 主要训练数据为 Libri-Light(Kahn 等,2020),一个包含 60,000 小时无标签语音的 LibriVox 有声书集合,采样率为 16kHz。
- 语音-文本对齐通过内部 ASR 系统与外部对齐工具(McAuliffe 等,2017)生成。
- 为进行可扩展性实验,构建了一个 60 万小时的多语言语料库,融合了来自 YouTube、播客(如 novelfm)及公开数据集(如 LibriLight、WenetSpeech、GigaSpeech)的英语与中文语音。
- 为处理大规模对齐,使用 60 万小时语料库中的 10,000 小时子集训练鲁棒的 MFA 模型,随后将其应用于全量数据集。
- 基准测试集包括:
- LibriSpeech test-clean(Panayotov 等,2015),用于遵循 NaturalSpeech 3(Ju 等,2024)的零样本 TTS 评估。
- LibriSpeech-PC test-clean,用于遵循 F5-TTS(Chen 等,2024b)的零样本 TTS 评估。
- L2-Artic 数据集(Zhao 等,2018),用于遵循 Melechovsky 等(2022)与 Liu 等(2024a)的带口音 TTS 评估。
- 为测试可扩展性,从多样化来源收集额外测试集:CommonVoice(Ardila 等,2019)用于嘈杂的真实语音;RAVDESS(Livingstone 和 Russo,2018)用于情感语音(仅强强度样本);LibriTTS(Zen 等,2019)用于高质量语音;以及来自视频、电影与动画的媒体片段,用于测试音色模拟能力。
- 每个测试集包含每源 40 个音频样本,用于客观与主观评估。
- 模型在 8 块 NVIDIA A100 GPU 上训练,WaveVAE 训练 200 万步,MegaTTS 3 训练 100 万步,包括 80 万步预训练与 20 万步 PeRFlow 蒸馏。
- 训练数据融合 Libri-Light 与 60 万小时多语言语料库,处理流程包括基于 ASR 的转录与对齐提取。
- 评估中使用客观指标:WER(使用微调的 HuBERT-Large 模型)、SIM-O(使用 WavLM-TDCNN 说话人嵌入)用于零样本 TTS;MCD 与音高分布矩(σ, γ, κ)用于带口音 TTS。
- 主观评估通过 Amazon Mechanical Turk 进行 MOS 评分,每数据集 40 个样本,从三个维度评分:CMOS(质量、清晰度、自然度)、SMOS(说话人相似度)、ASMOS(口音相似度),测试者每次聚焦一个方面。
- 模型参数量从 0.5B 扩展至 7.0B,同时保持 VAE 固定,数据与模型扩展均带来 SIM-O 与 WER 的持续提升。
方法
作者为 MegaTTS 3 采用两阶段架构:第一阶段为基于 WaveVAE 的语音压缩模型,第二阶段为潜在扩散 Transformer 语音生成模型。整体框架如图所示,展示两个核心组件:WaveVAE 与稀疏对齐扩散 Transformer。
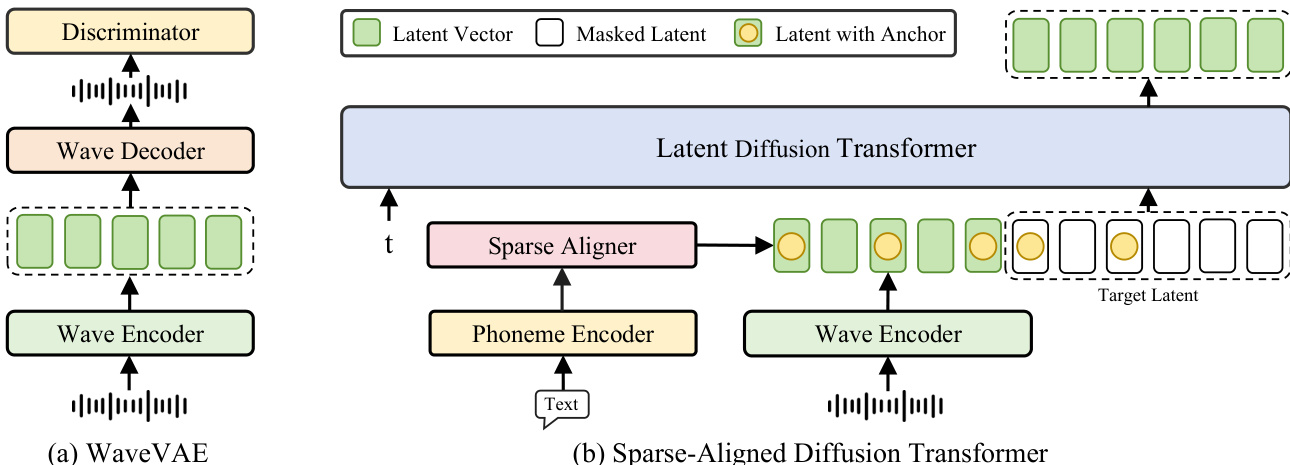
第一阶段中,WaveVAE 使用 VAE 编码器 E 将输入语音波形 s 压缩为低维潜在表示 z,该编码器将波形长度下采样因子 d 以降低计算复杂度。随后,波形解码器 D 将潜在向量 z 重建为波形 x=D(z)。为确保高质量重建,模型采用多个判别器——多周期(MPD)、多尺度(MSD)与多分辨率(MRD)——以捕捉高频细节。该压缩模型的训练损失结合了频谱重建损失 Lrec、轻微的 KL 惩罚损失 LKL 与对抗损失 LAdv。
第二阶段中,潜在扩散 Transformer 在文本与说话人信息条件下生成语音。给定从标准高斯分布采样的潜在向量 Z0 与来自压缩语音分布的目标潜在 Z1,模型学习一个修正流 T,将 Z0 映射至 Z1。该流由 Transformer 网络 vθ 参数化,用于估计常微分方程(ODE)dZt=v(Zt,t)dt 中的漂移力 v(Zt,t)。Transformer 被训练以最小化沿直线方向 (Z1−Z0) 的最小二乘损失,确保流遵循最优传输路径。
潜在扩散 Transformer 采用 LLAMA 中的标准 Transformer 块,使用旋转位置编码(RoPE)进行位置编码。训练时,潜在向量序列被随机划分为提示区域 zprompt 与掩码目标区域 ztarget,提示比例 γ 从均匀分布 U(0.1,0.9) 中采样。模型基于 zprompt 与音素嵌入 p 预测掩码目标向量 z^target,损失仅在掩码区域计算。该设置使模型能从 p 学习平均发音,从 zprompt 学习说话人特异性特征。
为增强对齐学习,模型引入稀疏对齐策略。该策略通过在音素序列中每音素保留一个锚点 token,生成粗粒度对齐路径,随后下采样并拼接至潜在序列。该粗粒度对齐简化了学习过程,同时允许模型通过注意力机制构建细粒度隐式对齐路径。稀疏对齐信息通过稀疏对齐器模块输入至潜在扩散 Transformer,该模块处理音素编码器输出与波形编码器输出,生成对齐后的潜在序列。
模型进一步采用分段修正流加速技术以提升推理效率。该技术将流轨迹划分为多个时间窗口,使学生模型可在更短的 ODE 段上训练。通过在这些缩短区间内求解 ODE,该方法显著减少了推理所需的函数评估次数,大幅加速生成过程。学生模型的训练目标是预测每个时间窗口内的漂移力,以该段终点作为目标。
最后,模型采用多条件无分类器引导(CFG)策略控制生成过程。该方法通过结合无条件与有条件输出,并为文本与说话人条件设置独立引导尺度,引导模型输出趋向条件生成。引导尺度 αtxt 与 αspk 基于实验结果选择,实现对口音强度与说话人相似度的灵活控制。训练时,模型通过随机丢弃说话人提示与文本条件(以指定概率)接触所有三类条件输入。
实验
- MegaTTS 3 在 LibriSpeech test-clean 上实现零样本语音合成的最先进性能,超越 11 个基线模型(包括 VALL-E 2、VoiceBox 与 F5-TTS),在 SIM-O、SMOS、WER 与 CMOS 指标上均表现优异,CMOS 达 4.42,WER 为 4.42,展现出卓越的说话人相似度、可懂度与鲁棒性。
- 所提出的稀疏对齐策略显著提升韵律自然度,在 LibriSpeech 上 MCD(4.42)、GPE(0.31)、VDE(0.29)与 FFE(0.34)指标上均取得最佳成绩,优于强制对齐与 NaturalSpeech 3。
- 在 L2-ARCTIC 的带口音 TTS 任务中,MegaTTS 3 显著超越 CTA-TTS 在口音相似度 MOS、MCD、音高分布统计量、CMOS 与 SMOS 上的表现,混淆矩阵分析证实其具备更强的口音可控性。
- 所提出的 WaveVAE 语音编解码器在高压缩率(25 tokens/s)下实现更优的重建质量(PESQ、ViSQOL、MCD),并因紧凑的潜在空间,使零样本 TTS 性能优于 Encodec 与 DAC。
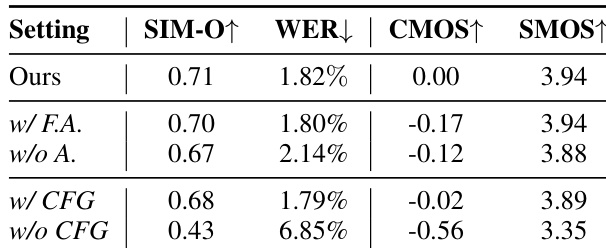
- 消融实验表明,稀疏对齐使 CMOS 提升 +0.17(相比强制对齐),多条件 CFG 增强控制灵活性,且 CFG 机制对性能至关重要。
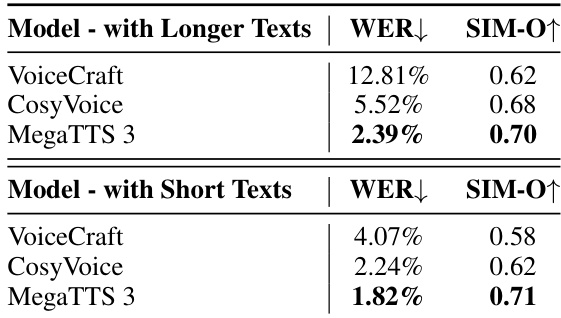
- MegaTTS 3 在长句与复杂句子上保持高语音质量与可懂度,与 AR 基线(如 VoiceCraft 与 CosyVoice)相比无显著退化,且在 ELLA-V 的困难转录上表现出强鲁棒性。
作者通过受控消融实验评估 MegaTTS 3 中不同组件的影响。结果表明,所提出的稀疏对齐策略显著提升性能,相比强制对齐与无对齐设置,CMOS 与 SMOS 均达最高。此外,多条件 CFG 机制进一步提升模型表现,完整模型在所有指标上均优于所有消融版本。
作者将 MegaTTS 3 与 VoiceCraft 及 CosyVoice 在长文本与短文本样本上进行性能对比,使用 WER 与 SIM-O 作为评估指标。结果表明,MegaTTS 3 在两种条件下均取得最低 WER 与最高 SIM-O,展现出更优的语音可懂度与说话人相似度,尤其在长文本上优势明显。
作者比较了多种语音压缩模型的重建质量,尽管 WaveVAE 使用较低的 token 速率,但在多个指标上仍取得最佳性能。WaveVAE 在 PESQ、ViSQOL 与 MCD 上均优于其他编解码器,证明其在高压缩率、高保真语音表示方面的有效性。

结果表明,MegaTTS 3 中提出的稀疏对齐在所有韵律自然度指标上均表现最佳,优于强制对齐与标准 CFG 基线。采用稀疏对齐的方法在 MCD 上达 4.42,GPE 为 0.31,VDE 为 0.29,FFE 为 0.34,相比基线模型与其他配置,显著提升了韵律自然度。

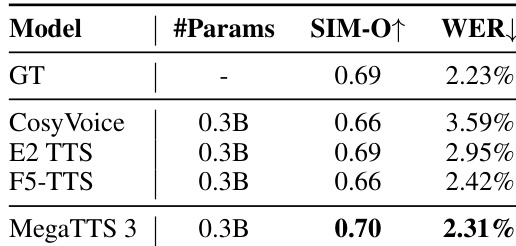
作者使用零样本语音合成模型 MegaTTS 3,并与 CosyVoice、E2 TTS 与 F5-TTS 等多个基线进行对比。结果表明,MegaTTS 3 在所有对比模型中取得最高 SIM-O 与最低 WER,表明其在说话人相似度与语音可懂度方面具有显著优势。