Command Palette
Search for a command to run...
YOLOv12:以注意力为中心的实时目标检测器
YOLOv12:以注意力为中心的实时目标检测器
Yunjie Tian Qixiang Ye David Doermann
摘要
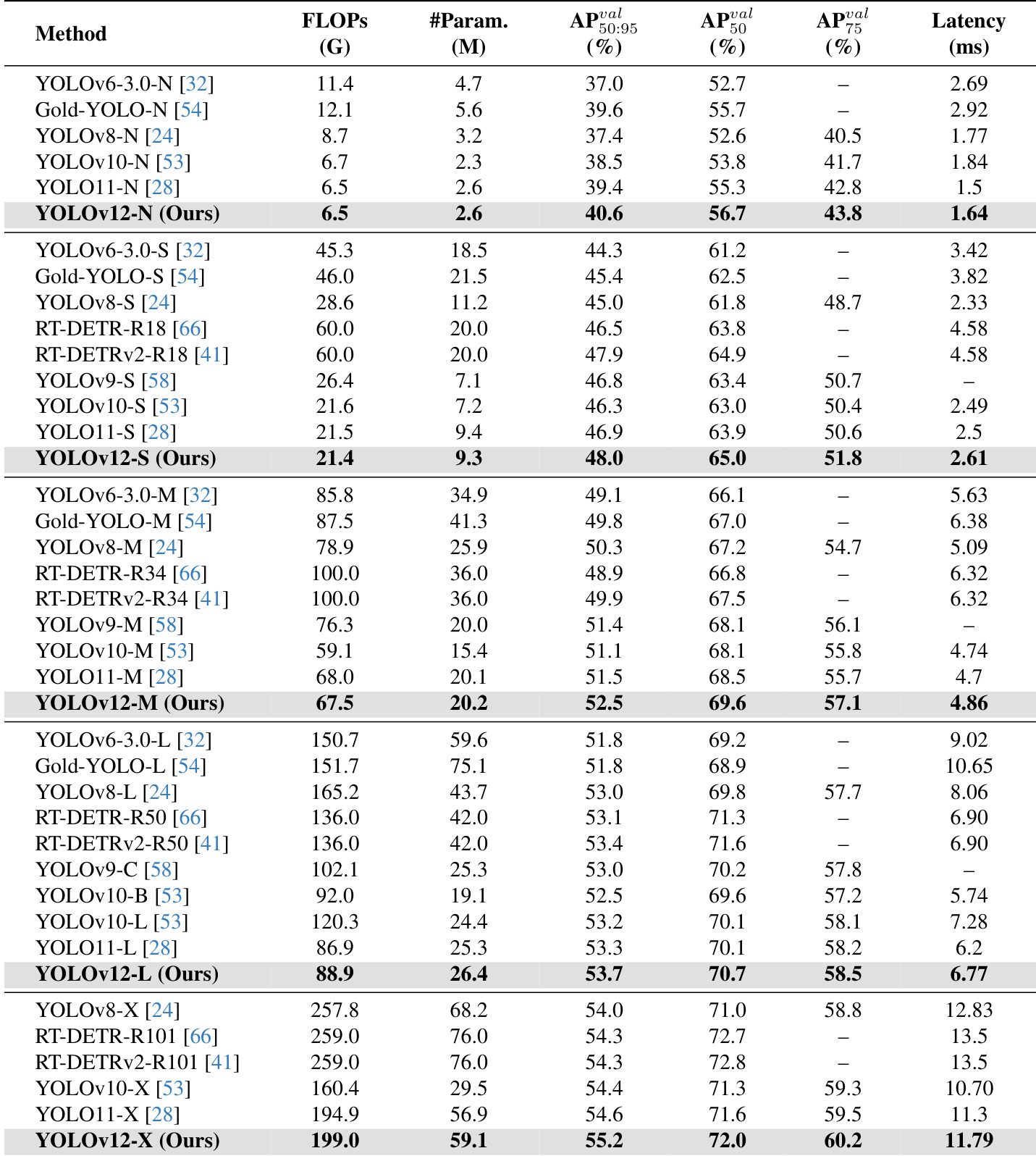
长期以来,提升YOLO框架的网络架构至关重要,但以往的研究主要集中在基于卷积神经网络(CNN)的改进上,尽管注意力机制在建模能力方面已被证明具有显著优势。这一现象的主要原因在于,基于注意力的模型难以达到CNN模型的推理速度。本文提出了一种以注意力机制为核心的YOLO框架——YOLOv12,该框架在保持与以往CNN-based模型相当推理速度的同时,充分挖掘了注意力机制带来的性能优势。YOLOv12在精度上超越了所有主流实时目标检测器,且具备竞争力的运行速度。例如,在T4 GPU上,YOLOv12-N模型实现了40.6%的mAP(平均精度均值),推理延迟仅为1.64毫秒,相较于先进的YOLOv10-N和YOLOv11-N,在精度上分别提升2.1%和1.2%,且速度相当。这一优势在其他模型规模上同样显著。此外,YOLOv12在端到端实时检测器中也表现卓越,超越了基于DETR改进的RT-DETR与RT-DETRv2系列模型:YOLOv12-S在性能上优于RT-DETR-R18与RT-DETRv2-R18,同时推理速度提升42%,计算量减少至36%,参数量降低至45%。更多对比结果详见图1。
一句话总结
纽约州立大学布法罗分校与中科院大学的研究人员提出 YOLOv12,这是一种以注意力机制为核心的实时目标检测器,在保持与基于 CNN 的 YOLO 变体及端到端 DETR 风格模型相当速度的同时,实现了更优的精度,通过高效的注意力机制,在延迟-精度和 FLOPs-精度权衡上超越了先前工作。
主要贡献
- 本工作通过引入 YOLOv12 这一以注意力机制为核心的框架,解决了实时目标检测中精度与速度长期存在的权衡问题,克服了注意力机制计算效率低下的缺陷,同时保持了实时应用所需的高推理速度。
- 所提出的 YOLOv12 集成了一种新型区域注意力模块(A2)与残差高效层聚合网络(R-ELAN),并结合 FlashAttention、移除位置编码以及调整 MLP 比例等架构优化,实现了在 YOLO 框架内高效基于注意力的建模。
- YOLOv12 在所有模型尺度上均达到最先进精度——例如 YOLOv12-N 达到 40.6% mAP,分别比 YOLOv10-N 和 YOLOv11-N 提升 2.1% 和 1.2% mAP,同时运行速度更快,参数量和 FLOPs 显著少于 RT-DETR 和 RT-DETRv2 等端到端检测器。
引言
实时目标检测在自动驾驶、机器人等应用中至关重要,低延迟与高精度是其核心要求。YOLO 系列通过在速度与性能之间取得平衡,长期主导该领域,但近期进展主要依赖于基于 CNN 的架构,尽管注意力机制已展现出更强的建模能力。其主要挑战在于注意力机制的二次方计算复杂度和低效的内存访问模式,阻碍了其在实时场景中的部署。此前尝试将注意力机制融入 YOLO 系统的努力均未能在速度上超越基于 CNN 的模型,限制了其实际应用。本文作者提出 YOLOv12,一种以注意力机制为核心的框架,通过三项关键创新克服上述局限:一种简单而高效的区域注意力模块(A2),在降低复杂度的同时保持大感受野;一种重新设计的残差高效层聚合网络(R-ELAN),提升优化与梯度流动;以及架构上的精简——包括使用 FlashAttention、移除位置编码、平衡 MLP 比例等,以提升速度并降低开销。结果表明,YOLOv12 在所有尺度上均达到最先进精度,同时在速度上匹配或超越先前基于 CNN 的 YOLO 模型,相比 YOLOv10-N、YOLOv11-N 以及 RT-DETR-R18 等端到端检测器,在显著更低的 FLOPs、参数量和延迟下实现更优性能。
方法
作者提出一种新颖的网络架构,将注意力机制有效整合进 YOLO 框架,解决了此类设计在实时目标检测系统中通常存在的计算效率低下问题。该方法的核心在于两项关键创新:区域注意力模块与残差高效层聚合网络(R-ELAN),旨在降低计算复杂度的同时保持高性能。
区域注意力模块被提出作为现有注意力机制的简单而高效替代方案。如图所示,该模块通过将分辨率 (H,W) 的特征图沿高度或宽度方向划分为 l 个段,生成大小为 (lH,W) 或 (H,lW) 的子区域,从而将全局注意力转化为局部操作。该方法避免了如移位窗口或十字交叉注意力等方法所需的显式窗口划分,消除了相关开销,并将实现简化为单一的重塑操作。默认 l 值设为 4,使感受野缩减至原始的四分之一,但仍保留足够大的感受野以实现有效的特征表示。该设计将注意力机制的计算成本从 2n2hd 降低至 21n2hd,其中 n 为 token 数量,h 为头数,d 为头大小。尽管在 n 上仍具二次复杂度,但针对 640×640 的固定输入分辨率,该设计依然高效,作者观察到性能仅略有下降,却实现了显著的速度提升。
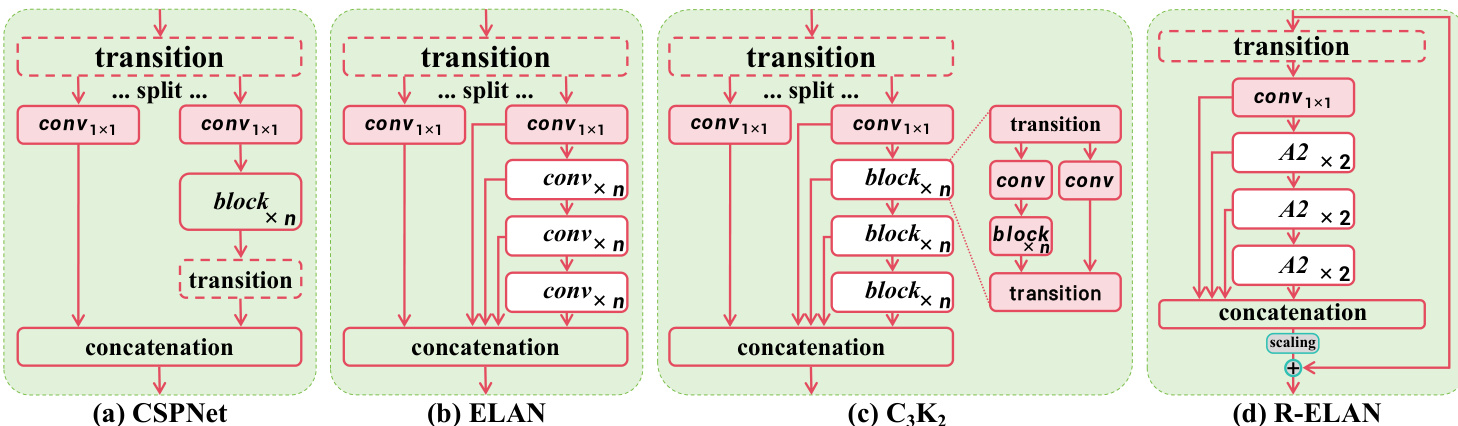
R-ELAN 架构旨在解决原始高效层聚合网络(ELAN)中存在的不稳定性和梯度阻塞问题。如框架图所示,标准 ELAN(图 3b)将过渡层输出分为两部分,其中一部分通过多个模块处理后与另一部分拼接。该设计缺乏从输入到输出的残差连接,尤其在结合注意力机制时可能阻碍收敛。为此,作者提出 R-ELAN(图 3d),在模块输入与输出之间引入一条残差捷径,并以 0.01 的缩放因子进行加权。该缩放因子类似于深度视觉 Transformer 中使用的层缩放,有助于稳定训练。此外,R-ELAN 通过先应用过渡层调整通道维度并生成单一特征图,再经后续模块处理后拼接,优化了聚合过程。该设计形成瓶颈结构,在保留特征融合能力的同时降低计算成本与内存占用。

除上述核心模块外,作者还实施多项架构改进,以更好地适配 YOLO 系统的实时约束。保留了先前 YOLO 系统的分层设计,区别于注意力主导的视觉 Transformer 常见的平铺式架构。在主干网络中,移除了最后一阶段的三个模块堆叠,仅保留单个 R-ELAN 模块,以简化网络结构并促进优化。前两个阶段的主干网络沿用 YOLOv11 的设计,且 R-ELAN 模块不应用于这些阶段。此外,对原始注意力机制的若干默认配置进行了调整:MLP 比例降低至 1.2(小型模型为 2),使用带批归一化的 nn.Conv2d 替代带层归一化的 nn.Linear,以利用卷积操作的高效性;移除位置编码;引入一个大尺寸可分离卷积(7×7),称为位置感知器,以帮助区域注意力模块捕捉位置信息。这些修改旨在更合理地分配计算资源,提升系统整体效率。
实验
- YOLOv12-N 在 MSCOCO 2017 上达到 45.8 mAP,分别比 YOLOv6-N、YOLOv8-N、YOLOv10-N 和 YOLOv11-N 提升 3.6%、3.3%、2.1% 和 1.2%,推理延迟为 1.64 ms/图像。
- YOLOv12-S 达到 48.0 mAP,延迟为 2.61 ms/图像,分别超越 YOLOv8-S、YOLOv9-S、YOLOv10-S 和 YOLOv11-S 3.0%、1.2%、1.7% 和 1.1%,同时保持更低或相当的 FLOPs 与参数量。
- YOLOv12-M 达到 52.5 mAP,延迟为 4.86 ms/图像,优于 Gold-YOLO-M、YOLOv8-M、YOLOv9-M、YOLOv10-M、YOLOv11-M 以及 RT-DETR-R34/RT-DETRv2-R34。
- YOLOv12-L 比 YOLOv10-L 提升 0.4% mAP,FLOPs 减少 31.4G,且在速度上超越 RT-DETR-R50/RT-DETRv2-R50,FLOPs 减少 34.6%,参数量减少 37.1%。
- YOLOv12-X 比 YOLOv10-X 和 YOLOv11-X 分别提升 0.8% 和 0.6% mAP,且在速度、FLOPs(减少 23.4%)和参数量(减少 22.2%)上优于 RT-DETR-R101/RT-DETRv2-R101。
- 消融实验表明,R-ELAN 在大模型(YOLOv12-L/X)中提升训练稳定性并显著降低复杂度,性能损失极小;区域注意力在 GPU 与 CPU 平台上均显著加速推理。
- 诊断分析显示,基于卷积的注意力(带批归一化)优于基于线性层的注意力(带层归一化);移除位置嵌入可提升性能与速度;MLP 比例为 1.2 时性能优于传统 4.0;FlashAttention 可降低 0.3–0.4 ms 延迟。
- 可视化结果表明,YOLOv12 生成的物体热图比 YOLOv10 和 YOLOv11 更清晰,表明其因区域注意力机制的大感受野而具备更优的前景感知能力。
作者使用 MSCOCO 2017 数据集评估 YOLOv12,与多个最先进实时检测器进行对比。结果表明,YOLOv12 在所有模型尺度上均实现更高精度,同时参数更少、推理速度更快,尤其在 N、S 和 M 变体上表现突出,L 和 X 变体也保持了竞争力。
作者使用 MS COCO 2017 数据集将 YOLOv12 与多个最先进检测器进行对比,结果显示 YOLOv12 在精度更高、参数更少方面优于 YOLOv8、YOLOv9、RT-DETR 和 YOLOv10。结果表明,YOLOv12 在精度-参数权衡上建立了更优的基准,尤其在小型模型中表现突出,体现了其高效性与有效性。

作者在不同模型尺度与硬件平台(RTX 3080、A5000、A6000)上将 YOLOv12 与 YOLOv9、YOLOv10 和 YOLOv11 进行对比,结果显示 YOLOv12 在上述 GPU 上均实现更快的推理速度,同时保持竞争力。例如,YOLOv12-N 在 RTX 3080 上 FP32 推理延迟降至 1.7 ms,速度超越 YOLOv9,与 YOLOv10 和 YOLOv11 相当。

YOLOv12-N/S/M/L/X 模型采用 600 个训练周期,优化器为 SGD,学习率采用线性衰减,并设置 3 个周期的预热阶段。配置包括特定超参数:批量大小为 32 × 8,权重衰减为 5 × 10⁻⁴,数据增强方式包括 Mosaic、Mixup 和复制粘贴,以提升模型性能。
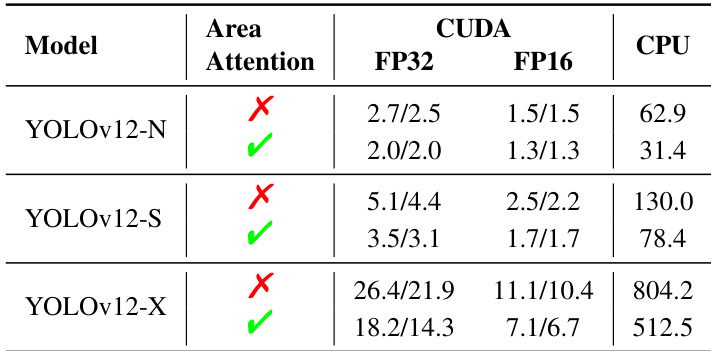
结果表明,区域注意力机制在 GPU(CUDA)与 CPU 平台上均显著降低 YOLOv12-N、YOLOv12-S 和 YOLOv12-X 的推理延迟。例如,在 RTX 3080 上启用区域注意力后,YOLOv12-N 的 FP32 延迟减少 0.7ms,所有模型与硬件配置下均观察到一致的速度提升。