Command Palette
Search for a command to run...
HealthGPT:一种通过异构知识适配实现统一理解与生成的医疗大视觉语言模型
HealthGPT:一种通过异构知识适配实现统一理解与生成的医疗大视觉语言模型
摘要
我们提出HealthGPT,这是一个强大的医学多模态大模型(Med-LVLM),能够在统一的自回归框架内整合医学视觉理解与生成能力。我们的方法基于一种渐进式自举(bootstrapping)理念,旨在逐步将异构的理解与生成知识适配至预训练的大语言模型(LLMs)。这一目标通过一种新颖的异构低秩适配技术(H-LoRA)实现,并辅以定制化的分层视觉感知方法以及三阶段学习策略。为有效训练HealthGPT,我们构建了一个全面的、面向医学领域的专用理解与生成数据集,命名为VL-Health。实验结果表明,HealthGPT在医学视觉统一任务中展现出卓越的性能与良好的可扩展性。项目开源地址为:https://github.com/DCDmllm/HealthGPT。
一句话总结
浙江大学、电子科技大学、阿里巴巴、香港科技大学和新加坡国立大学的作者提出 HealthGPT,一种统一的自回归医学大视觉语言模型,通过异构低秩适配(H-LoRA)和分层视觉感知,整合医学图像理解与生成能力,在面向复杂医疗应用的新 VL-Health 数据集上超越现有模型。
主要贡献
-
HealthGPT 提出一种统一的医学大视觉语言模型(Med-LVLM),在单一自回归框架内集成视觉理解与生成能力,弥补了现有模型通常仅聚焦单一能力的不足,尤其在数据稀缺的医学领域表现突出。
-
所提出的异构低秩适配(H-LoRA)方法通过独立的 LoRA “插件” 解耦理解与生成学习,并采用可逆矩阵块乘法设计与 LoRA 专家结合,实现高效、无冲突训练,相比 MoELoRA 将计算开销降低 33%。
-
HealthGPT 在 VL-Health 上进行训练,该数据集包含七项理解任务和五项生成任务,展示了在多样化医学多模态基准上的最先进性能,尽管训练数据有限,仍优于通用模型与领域专用模型在统一任务中的表现。
引言
作者利用大视觉语言模型(LVLMs)应对智能、多功能医学 AI 系统日益增长的需求,这些系统需同时理解与生成医学视觉内容——这对诊断支持、治疗规划和自动化报告生成等应用至关重要。以往医学 LVLM 研究主要集中在理解任务,如视觉问答或报告生成,往往缺乏稳健的视觉生成能力;而通用领域的统一 LVLM 在医学场景中面临挑战,受限于高质量数据稀缺,以及理解(抽象细节)与生成(需精细保真)之间的固有冲突。这些问题导致联合训练时性能下降。为克服此问题,作者提出 HealthGPT,一种统一的医学 LVLM,采用一种新颖的参数高效微调方法——异构低秩适配(H-LoRA)。H-LoRA 通过任务特定的即插即用 LoRA 模块解耦理解与生成学习,缓解干扰并实现高效适配。其进一步结合可逆矩阵块乘法的专家混合设计,降低训练开销。分层视觉感知模块与三阶段学习策略确保有效知识融合。作者还引入 VL-Health,一个涵盖多样化医学理解与生成任务的综合性数据集。HealthGPT 在多个基准上实现最先进性能,首次在数据受限条件下成功实现医学视觉语言理解与生成的有效统一。
数据集
-
VL-Health 数据集由多个医学专用与通用多模态数据集组成,用于视觉理解任务,包括 VQA-RAD、SLAKE、PathVQA、MIMIC-CXR-VQA、LLaVA-Med、PubMedVision 和 LLaVA-1.5;用于生成任务,整合了 IXI(超分辨率)、SynthRAD2023(模态转换)、MIMIC-CHEST-XRAY(文本到图像生成)以及重新处理的 LLaVA-558k(图像重建)数据。
-
数据集包含 765,802 个视觉问答(VQA)样本用于理解任务,以及 783,045 个生成样本,涵盖重建、超分辨率和模态转换等任务。医学图像来源覆盖 11 种模态——CT、MRI、X 射线、显微镜、OCT、超声、眼底摄影等,涵盖从常见到罕见的多种疾病,包括肺部、骨骼、脑部、心血管及细胞异常。
-
数据处理包括过滤多图像样本以降低训练开销,将问题标准化为开放式与单选题格式,并对扫描图像进行切片、配准、增强与归一化处理。生成任务中,2D 图像作为视觉输入,使用 VQGAN 生成的索引监督自回归生成。
-
所有数据转换为统一的指令-响应格式,包含结构化组件:任务类型、任务指令、响应、输入图像和目标图像索引(生成任务)。任务类型决定视觉特征粒度并选择相应的 H-LoRA 子模块。
-
模型采用三阶段学习策略,使用从第一阶段数据中提取的混合-47k 子集。训练采用 H-LoRA,秩为 16 和 64,共四个专家,视觉编码器使用 CLIP-L/14,提取其第二层与倒数第二层特征以实现分层感知。f8-8192 VQGAN 作为图像索引与上采样模块。
方法
作者采用统一的自回归框架,将医学视觉理解与生成能力整合于单一模型 HealthGPT 中。该框架将两类任务均视为序列标记预测问题,模型通过共享的大语言模型(LLM)骨干网络生成理解任务的文本响应或生成任务的离散 VQGAN 索引序列。模型输入由视觉与文本标记的联合序列构成,经一系列模块处理后输出最终结果。整体架构通过动态路由视觉特征并利用专用模块适配知识,以满足理解与生成的不同需求。
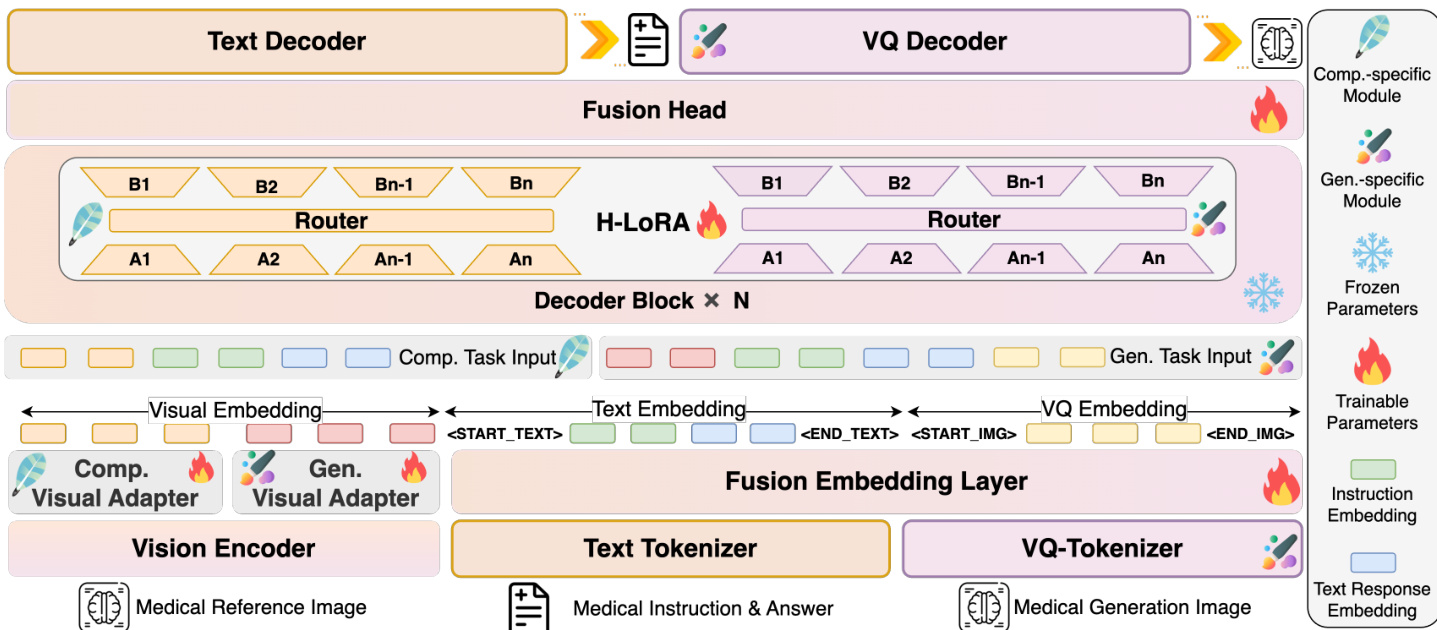
参考框架图。模型首先通过视觉编码器处理医学参考图像,提取视觉特征。这些特征随后进入视觉适配器,该适配器为任务特定:理解专用适配器用于抽象特征,生成专用适配器用于具体特征。视觉特征通过视觉嵌入层转换为视觉标记。同时,医学指令与答案经文本分词器生成文本标记,并在文本嵌入层中嵌入。对于生成任务,医学生成图像经 VQ 分词器生成 VQ 标记,并在 VQ 嵌入层中嵌入。视觉、文本与 VQ 嵌入被拼接为联合序列,输入融合嵌入层。该层融合嵌入并添加指令与任务特定嵌入以引导模型。融合序列随后由一系列解码器块处理,每个解码器块包含融合头与 H-LoRA 模块。H-LoRA 模块根据输入动态选择并组合来自任务特定 LoRA 专家的知识,实现对不同任务的高效适配。最终输出由文本解码器(理解任务)或 VQ 解码器(生成任务)生成。
模型采用分层视觉感知方法,以应对理解与生成任务在视觉需求上的差异。视觉编码器基于视觉 Transformer(ViT),处理输入图像以生成多层级的特征序列。这些特征分为两类:ViT 浅层的细粒度特征,包含适合生成的全局信息;ViT 深层的抽象粒度特征,捕捉接近文本空间的语义信息,适合理解。任务类型决定下游 LLM 使用哪一组特征。该选择由任务特定的硬路由器执行,将合适的视觉特征路由至融合头。
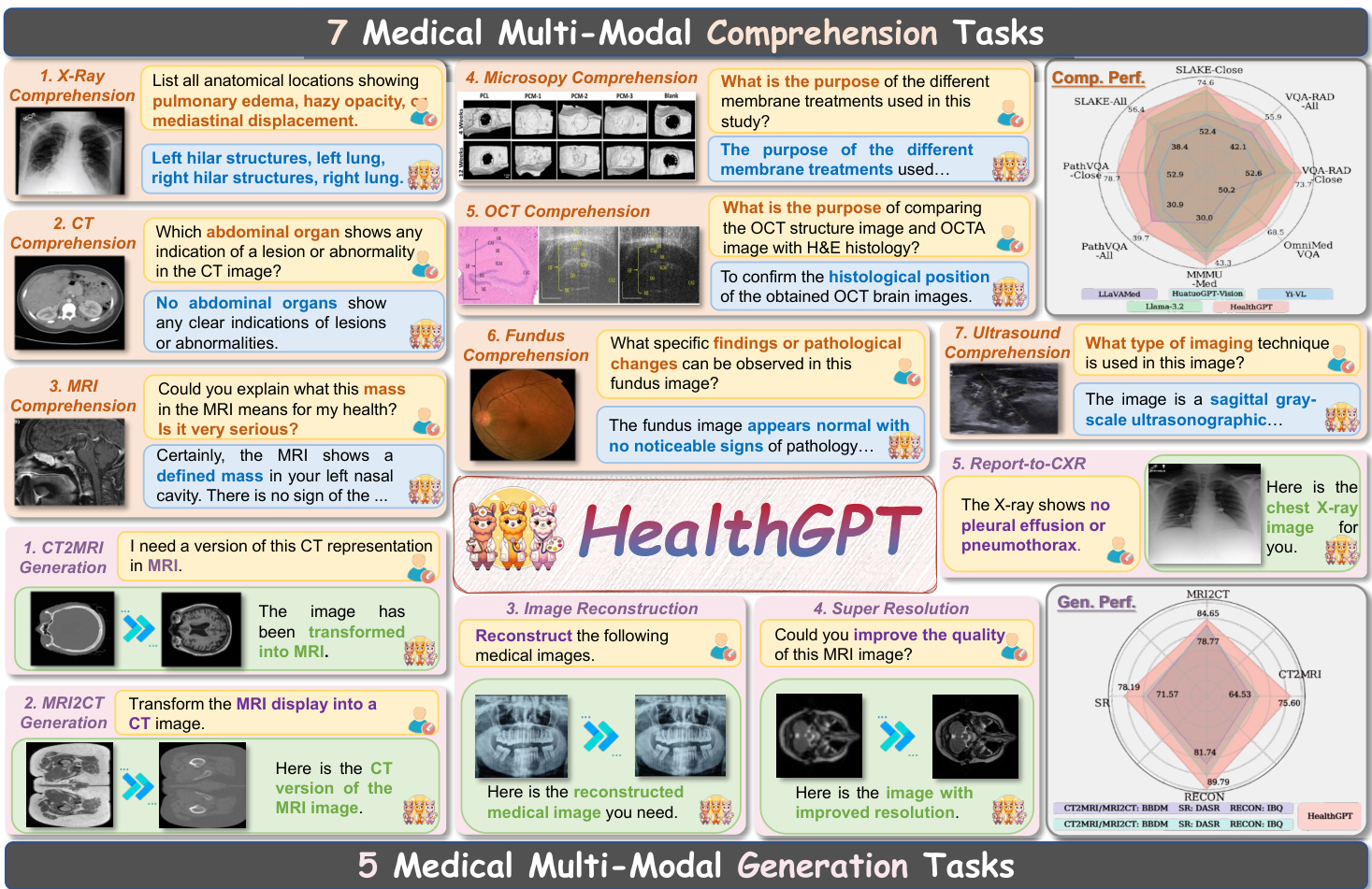
如上图所示,模型能够处理多样化的医学任务。在理解任务中,模型可回答关于 X 射线、CT 扫描、MRI 等医学图像的问题,识别解剖结构、异常情况及医疗操作目的。在生成任务中,模型可执行 CT 转 MRI、根据描述重建医学图像、提升 MRI 分辨率等任务。模型在这些任务上的性能通过综合性医学领域专用数据集 VL-Health 进行评估。
模型适配策略的核心是异构低秩适配(H-LoRA)技术。该方法将理解与生成任务的知识分别存储于独立模块中,并动态路由以提取任务相关知识。在任务层面,为每种任务类型分配专用的 H-LoRA 子模块。在特征层面,H-LoRA 融合了专家混合(MoE)思想,但避免了矩阵拆分带来的计算开销,通过将多个 LoRA 专家的低秩矩阵合并为单一统一矩阵实现。路由层基于输入隐藏状态生成专家权重,经扩展后通过逐元素乘法与矩阵乘法计算最终输出。该设计使模型能高效学习并应用来自不同任务的异构知识,而无显著计算延迟。
HealthGPT 的训练过程采用三阶段结构,以确保有效学习与模型稳定性。第一阶段为多模态对齐,分别训练医学理解与生成任务的视觉适配器及 H-LoRA 子模块。第二阶段为异构 H-LoRA 插件适配,使用混合数据微调词嵌入层与输出头,确保不同 H-LoRA 插件间的一致性,形成统一基础。第三阶段为视觉指令微调,引入额外任务特定数据进一步优化模型,增强其对下游任务的适应能力。该分阶段方法使模型逐步积累基础认知,并有效缓解任务间冲突,从而提升理解与生成任务的整体性能。
实验
-
主要实验:
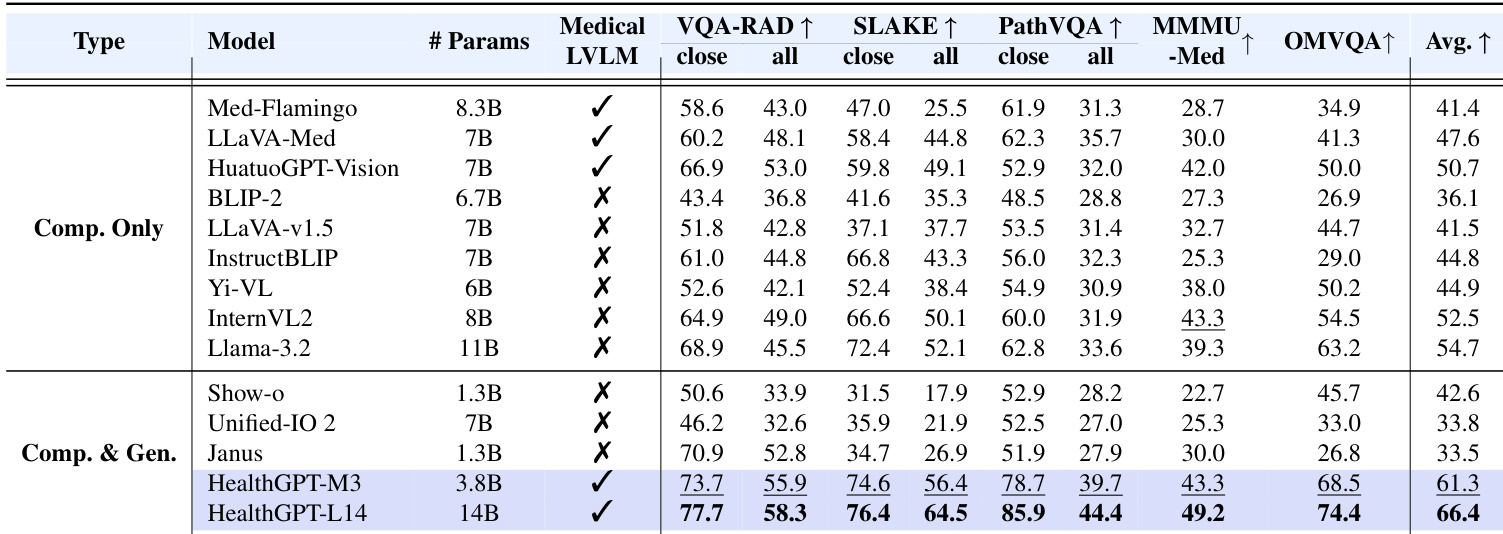
- 医学视觉理解:HealthGPT-M3 在医学多模态统一任务上达到 61.3 分,优于医学专用模型(如 HuatuoGPT-Vision)与通用模型(如 Llama-3.2);HealthGPT-L14 达到 66.4 分,展现强大可扩展性。
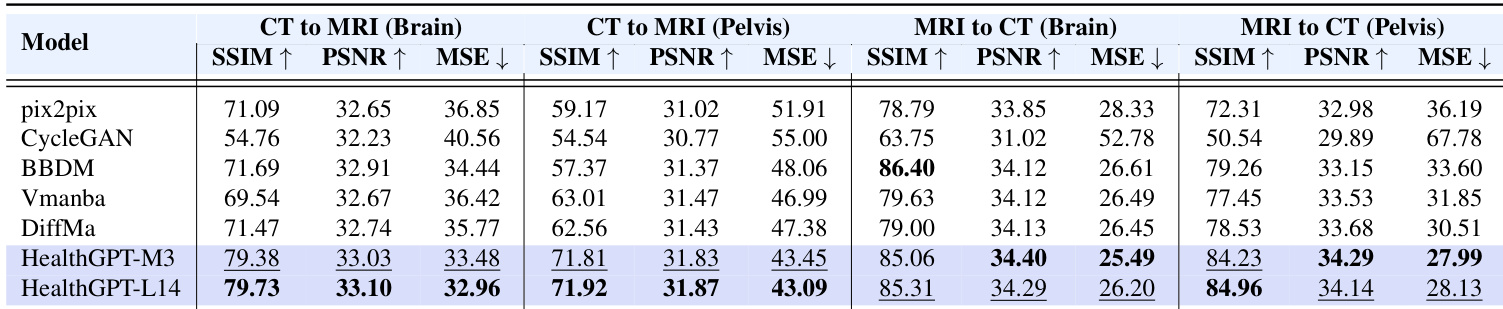
- 模态转换(CT/MRI):HealthGPT-M3 在 CT2MRI-Brain 任务中 SSIM 达 79.38,超越 Pix2Pix(71.09)与 DiffMa(71.47)。
- 超分辨率(IXI 上 4x):HealthGPT-M3 达 SSIM 78.19,PSNR 32.76,ISE 34.47,人类感知评分 12.34,显著优于现有方法。
- 图像重建:HealthGPT 展现出更优的可控性与稳定性,以极少数据超越 Unified-IO 2 与 SEED-X。
- 报告到 CXR 生成:HealthGPT 能根据文本指令生成准确的 CXR 图像,展现出在医学教育与诊断中的潜力。
-
核心结果:
- 在 OmniMedVQA 基准上,HealthGPT-L14 平均得分 74.4,超越所有对比模型在所有子任务中的表现。
- 在 VQA-RAD、SLAKE 与 PathVQA 的人工评估中,HealthGPT-L14 被临床医生频繁评为最佳响应。
- H-LoRA 在各项任务中持续优于 LoRA 与 MoELoRA,即使在 32 个专家情况下也无额外训练开销,而 MoELoRA 的训练时间显著增加。
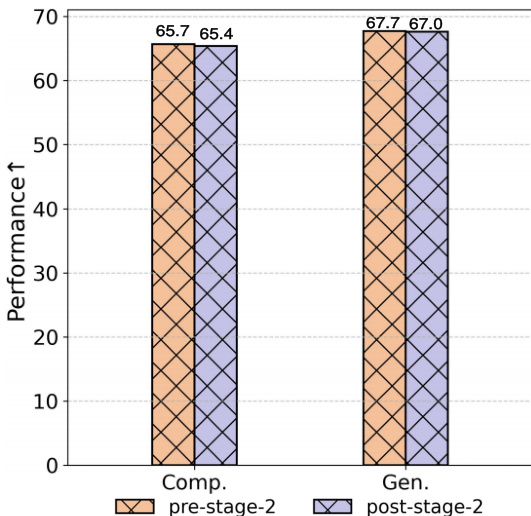
作者采用三阶段学习策略提升医学视觉理解与生成任务性能。结果显示,第二阶段后,两类任务性能均显著提升,理解任务从 65.7 提升至 67.7,生成任务从 65.4 提升至 67.0。
作者对比 HealthGPT 在不同 LoRA 专家数量下与 MoELoRA 和 H-LoRA 的性能,结果显示 H-LoRA 在理解与生成任务中均持续优于 MoELoRA,同时保持相似或更低的训练时间。结果表明,H-LoRA 在所有配置下均取得更高得分,最佳性能出现在 n=32 时,而 MoELoRA 在此配置下无法完成训练。

结果表明,HealthGPT-M3 与 HealthGPT-L14 在模态转换实验的所有子任务中均优于其他模型,HealthGPT-L14 在多数指标上取得最高分。具体而言,HealthGPT-M3 在脑部与骨盆区域的 CT 到 MRI 转换中分别取得 SSIM 79.38 与 71.81,HealthGPT-L14 进一步提升至 79.73 与 71.92,展现出在模态转换任务中的卓越性能。
结果表明,HealthGPT-M3 与 HealthGPT-L14 在多个医学视觉理解基准上均优于所有对比模型,HealthGPT-L14 达到 66.4 的最高平均分。作者采用 H-LoRA 的三阶段学习策略提升性能,证明其方法在医学下游任务中显著超越医学专用与通用模型。
作者采用三阶段学习策略训练 HealthGPT,其在所有评估任务中显著优于混合训练。结果显示,三阶段方法在理解与生成任务中均取得更高分数,各类基准提升幅度达 15.9 至 27.9 分,充分证明其在降低任务冲突与提升模型性能方面的有效性。
